- 紹介
-
 新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
アプリケーションの容量と可用性を向上
新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
アプリケーションの容量と可用性を向上 あらゆる業務ワークロードに対応するスループットと容量の多様性
あらゆる業務ワークロードに対応するスループットと容量の多様性 データのバックアップと復元を瞬時に、安全に、データの整合性を保ちながら行います。
データのバックアップと復元を瞬時に、安全に、データの整合性を保ちながら行います。 ビジネスコストを最大90%削減
ビジネスコストを最大90%削減 包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
迅速な拡張性を備えた先進の仮想サーバーサービス
包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
迅速な拡張性を備えた先進の仮想サーバーサービス FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します
FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します 3D レンダリング、AI、ML 用の仮想サーバーと統合
3D レンダリング、AI、ML 用の仮想サーバーと統合 今すぐ独占的な先行予約を確保し、 NVIDIAの強力なテクノロジー によって駆動されるAI開発のための オールインクルーシブスタックへの 優先アクセスを手に入れましょう!
今すぐ独占的な先行予約を確保し、 NVIDIAの強力なテクノロジー によって駆動されるAI開発のための オールインクルーシブスタックへの 優先アクセスを手に入れましょう!
3D レンダリング、AI、ML 用の仮想サーバーと統合
迅速な拡張性を備えた先進の仮想サーバーサービス
ビジネスコストを最大90%削減
独立したインフラで強力なパフォーマンス
今すぐ独占的な先行予約を確保し、 NVIDIAの強力なテクノロジー によって駆動されるAI開発のための オールインクルーシブスタックへの 優先アクセスを手に入れましょう!
今すぐ独占的な先行予約を確保し、 NVIDIAの強力なテクノロジー によって駆動されるAI開発のための オールインクルーシブスタックへの 優先アクセスを手に入れましょう!
3D レンダリング、AI、ML 用の仮想サーバーと統合
迅速な拡張性を備えた先進の仮想サーバーサービス
ビジネスコストを最大90%削減
独立したインフラで強力なパフォーマンス サービスは、すべてのサイズでAPIを初期化、維持、管理、保護します
サービスは、すべてのサイズでAPIを初期化、維持、管理、保護します
 FPT Kubernetes Engineでアプリケーションを迅速に作成、管理、展開するソリューションを提供します
コンテナ画像の保存、管理、デプロイ、セキュリティ保護が容易
FPT Kubernetes Engineでアプリケーションを迅速に作成、管理、展開するソリューションを提供します
コンテナ画像の保存、管理、デプロイ、セキュリティ保護が容易
 スマート管理サービス
スマート管理サービス 企業向けの仮想コンピューターサービス
いつでも、どこでも、どんなプラットフォームでものシステム監視ソリューション
企業向けの仮想コンピューターサービス
いつでも、どこでも、どんなプラットフォームでものシステム監視ソリューション 高度なGPU処理と統合されたKubernetesサービスにより、高パフォーマンスのアプリケーション開発を加速
サービスとして提供され、クラウドでのMongoDBデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
高度なGPU処理と統合されたKubernetesサービスにより、高パフォーマンスのアプリケーション開発を加速
サービスとして提供され、クラウドでのMongoDBデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする "サービスとして提供され、クラウドでのMySQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのPostgreSQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのRedisデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
アプリケーションの容量と可用性を向上
FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します
包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
無制限のストレージ、安全で保証されたパフォーマンス、継続的で高いデータ検索ニーズ
あらゆる業務ワークロードに対応するスループットと容量の多様性
"サービスとして提供され、クラウドでのMySQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのPostgreSQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのRedisデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
アプリケーションの容量と可用性を向上
FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します
包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
無制限のストレージ、安全で保証されたパフォーマンス、継続的で高いデータ検索ニーズ
あらゆる業務ワークロードに対応するスループットと容量の多様性 - 価格表
- パートナー
- イベント
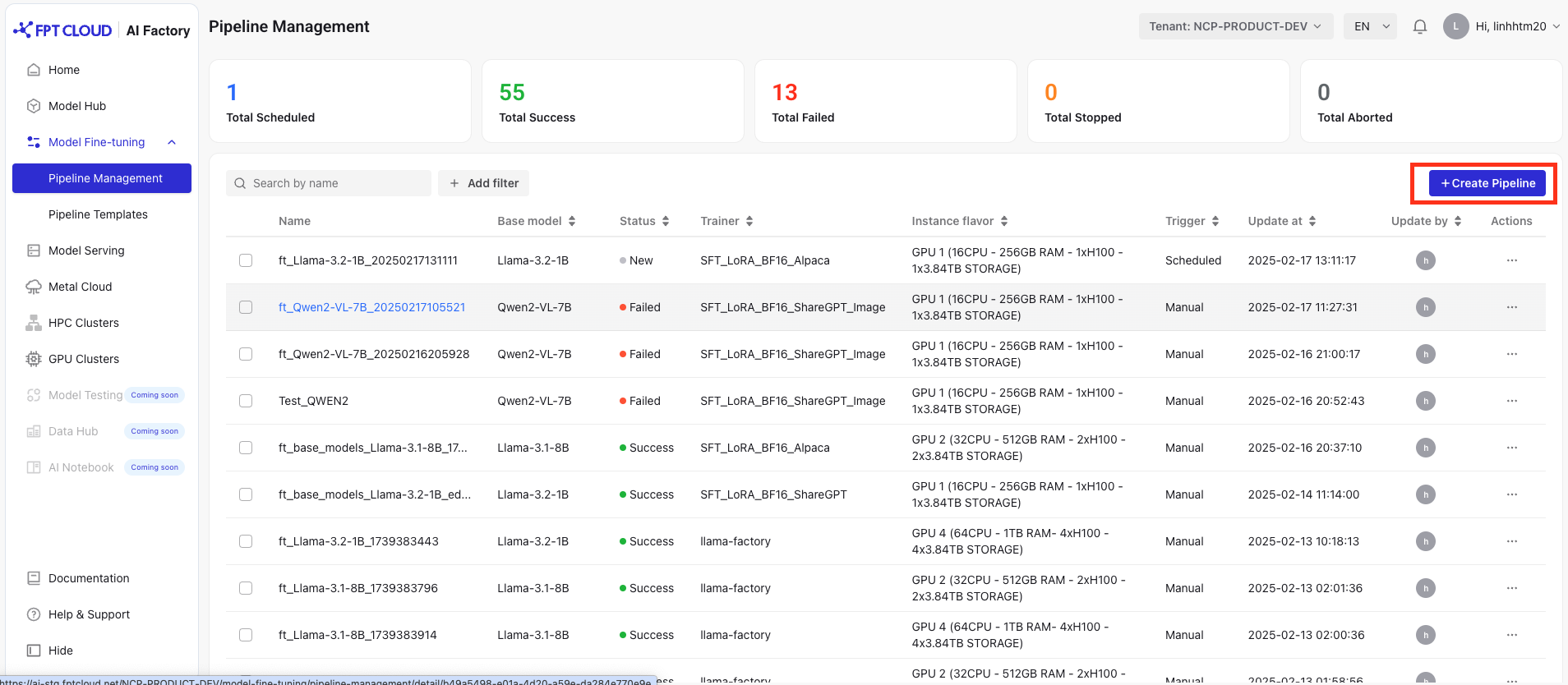
パイプラインの作成
パイプラインの作成
Model Fine-tuningサービスにアクセスし、「パイプライン管理」を選択し、「パイプライン作成」ボタンをクリックします。
1. ベースモデルを選択します
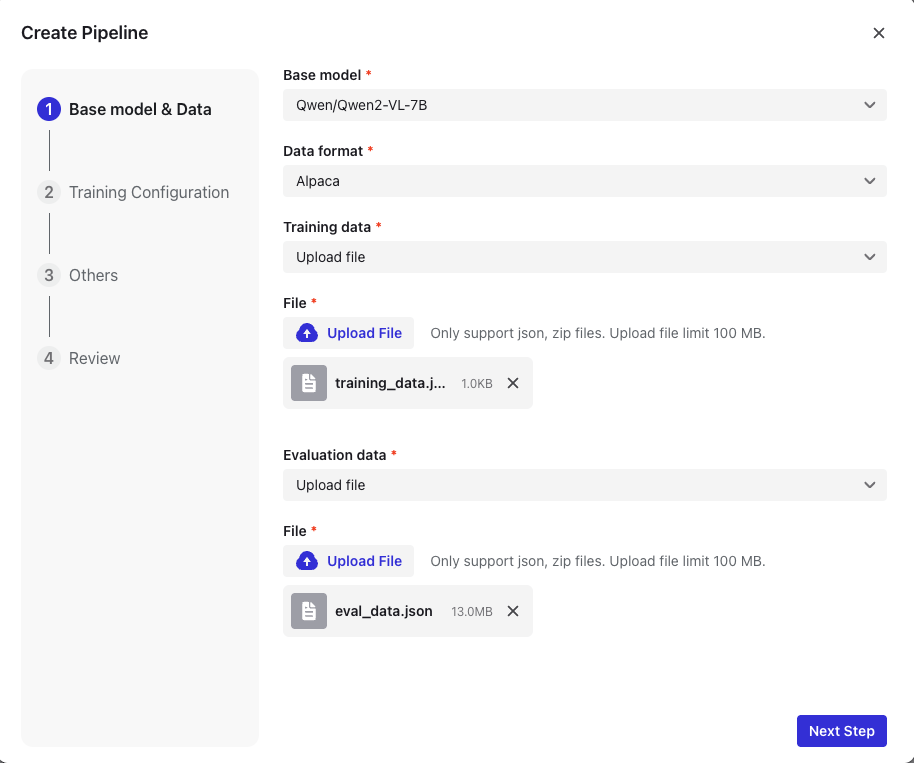
- 現在、ファインチューニング用の複数ベースモデルを提供しています。
| ベースモデル | 説明 |
|---|---|
| Llama-3.1-8B | NLPタスク用に最適化された80億のパラメータを備えたLlama-3.1 |
| Llama-3.2-1B | コンパクトな1Bパラメータバージョンで、リソースが限られている高性能アプリケーションに最適 |
| Llama-3.2-1B-Instruct | 指示ベースのインタラクション用に微調整されている |
| Llama-3.2-3B | 3Bパラメータを持つバランスの取れたモデル |
| Llama-3.2-3B-Instruct | 特定のイントラクションタスク用に微調整されたバージョン |
| Llama-3.2-8B-Instruct | ガイド付き応答用のインストラクション調整された 8B モデル |
| Llama-3.2-11B-Vision | テキスト画像タスク用のビジョン対応モデル |
| Llama-3.2-11B-Vision-Instruct | 指示ベースの微調整されたビジョンモデル |
| Meta-Llama-3.1-8B-Instruct | Meta-Llama-3.1の8Bインストラクションチューニングバージョン |
| Qwen2-0.5B | 組み込みAI用の0.5Bコンパクトモデル |
| Qwen2-1.5B | 1.5Bバージョン、効率と拡張性のバランス |
| Qwen2-VL-7B | 7B パラメーターを持つビジョン言語モデル |
| Qwen2.5-14B-Instruct | 複雑なAIタスクのための高度な14Bインストラクションチューニングバージョン |
| Llama-3.1-70B | 複雑なNLPタスク、研究、自動化のための高度な70Bインストラクションチューニングバージョン |
| Llama-3.3-70B-Instruct | 高度なAIアシスタント、推論、自動化のための高度な 70Bインストラクションチューニングバージョン |
| Qwen2.5-32B | 効率的なNLP、コーディング、リサーチ、および内容生成のための32Bインストラクションチューニングバージョン |
注:自らのモデルをアップロードしたい場合は、お問い合わせください!
2. データセットを準備する
- トレーニング/評価データセットをアップロードするには、次の 2つの方法があります。
- ファイルのアップロード:対応形式:ZIP(zip2回)、JSON(最大:100MB)
- 接続の選択:接続を選択し、バケット内のオブジェクトへのパスを入力します。
接続を選択する前に、データハブにアクセスし、データソースを選択し、バケットへのエンドポイントURLを入力し、アクセスキーとシークレットキーを指定して接続を作成する必要があります。
- データサンプル :GitHub(リンク)にアクセスして、使用するサンプルデータを取得して下さい。
3. トレーニングの構成
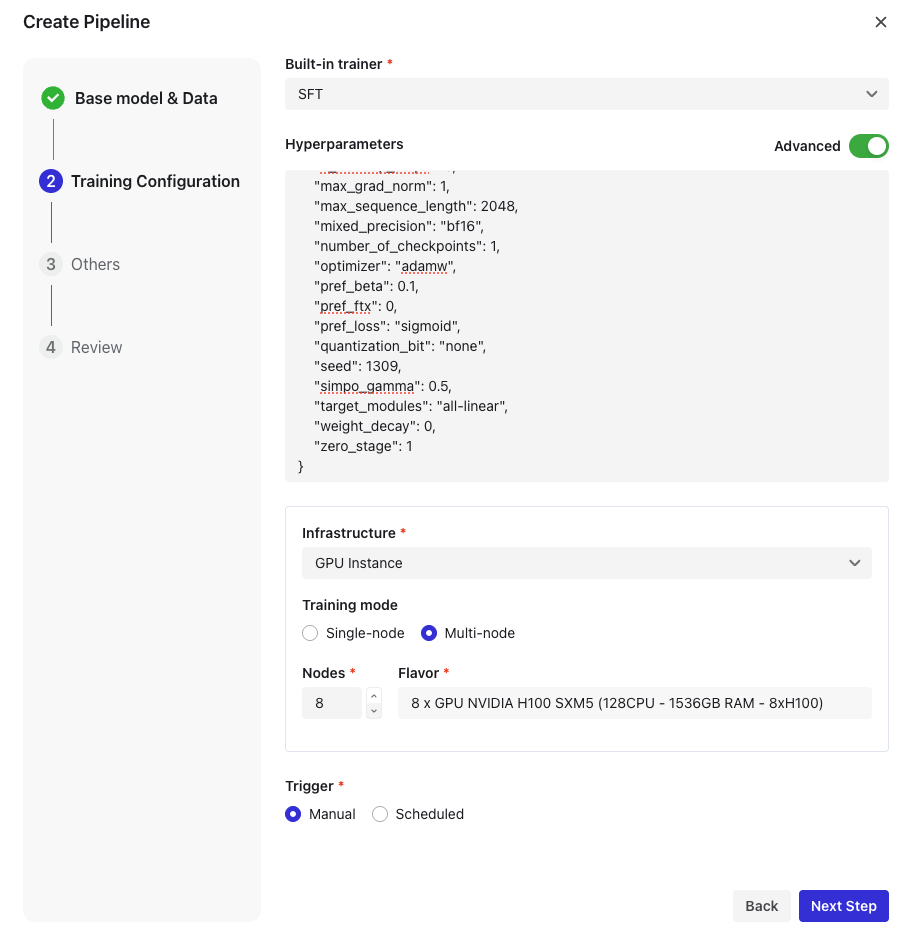
- トレーナーを選択
| トレーナー | 説明 |
|---|---|
| データセットのフォーマット: {instruction, input, output} | |
| SFT_LoRA_BF16_ShareGPT | ShareGPTデータセットでトレーニングされ、会話の応答が改善されました。 |
| データセットのフォーマット:multi-turn chats / {conversations[from, value]} | |
| SFT_LoRA_BF16_ShareGPT_Image | マルチモーダル(テキストおよび画像)処理に最適化されています。 |
| データセットのフォーマット:マルチターンチャット / {会話[差出人, 値]} + image_path |
4. ハイパーパラメータの設定
| ハイパーパラメータ | 説明 |
|---|---|
| Epochs | データセットのトレーニングサイクルの数 |
| Batch Size | ステップごとに処理されるサンプルの数 |
| Learning Rate | モデルのウェイトの更新を制御します |
| Sequence Length | 入力あたりの最大トークン長 |
| Checkpoint Steps | チェックポイントを保存する頻度の定義 |
| Gradient Accumulation Steps | ウェイト更新前にグラデーション更新の決定 |
| Distributed backend | 分散トレーニングのバックエンド |
| Zero Stage | ZeROオプティマイザーのステージ |
また、JSONファイルを使用した構成のための20を超えるハイパーパラメーターをサポートする詳細モードも提供しています。上記のパラメータに加えて、システムは以下のパラメータもサポートしています。
| ハイパーパラメータ | 説明 |
|---|---|
| lr_scheduler_type | 使用する学習率スケジューラの種類 |
| lr_warmup_steps | 学習率スケジューラのウォームアップフェーズの学習ステップ数 |
| disable_gradient_checkpointing | グラデーションチェックポイントを無効にする |
| eval_strategy | モデル評価戦略 |
| eval_steps | モデル評価頻度 |
| mixed_precision | 最適化された使用 |
| optimizer | 使用する微調整の種類 |
| lora_alpha | LoRAのスケーリング係数 |
| lora_dropout | LoRAのドロップアウト率 |
| lora_rank | LoRAのランク |
| quantization_bit | 量子化のビット数 |
| flash_attention_v2 | Flash Attention v2を使用しているかどうか |
| logging_steps | ログする頻度 |
| checkpoint_strategy | |
| max_grad_norm | グラデーションの正規化 |
| number_of_checkpoints | 保存されたチェックポイントの数 |
| seed | ランダムのシード |
| full_determinism | トレーニングプロセスの決定性を確保する |
| weight_decay | パラメーターの大きさのスケーリング係数 |
| target_modules | 微調整するモジュールの名前 |
5. トリガーの微調整
| トリガー | 形容 |
|---|---|
| 手動 | ユーザーが開始する微調整。 |
| 予定 | 設定されたスケジュールに基づく自動微調整。 |
6. 追加設定
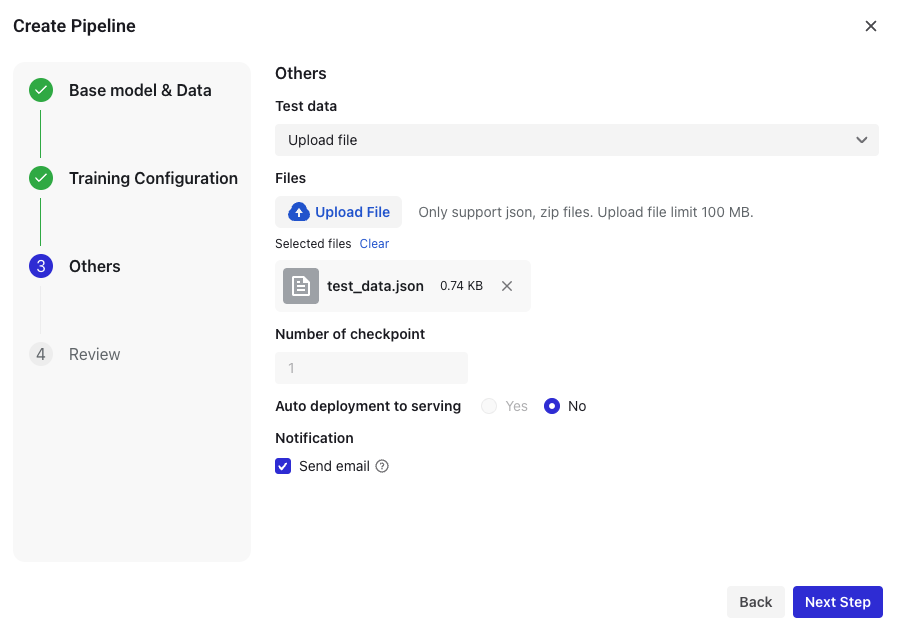
- テストデータのアップロード(ZIP、JSON最大100MB)
- チェックポイント数の設定
- 電子メール通知を有効化: 通知は、パイプラインを作成するアカウントにメールで送信されます
7. レビュー&ファイナライズ
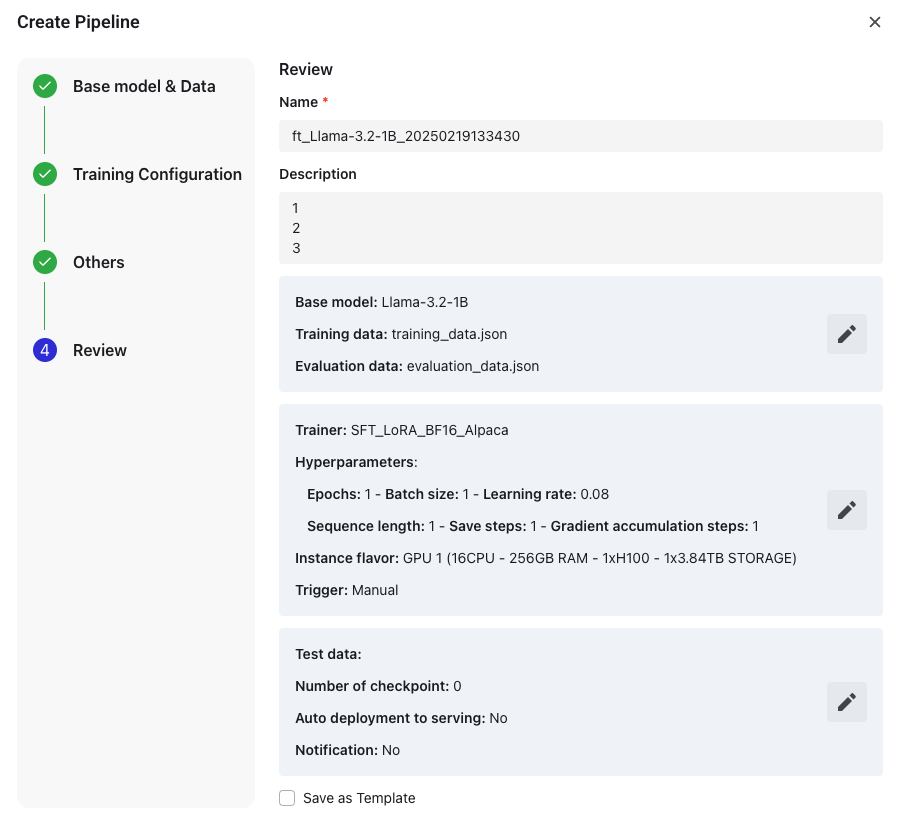
-
パイプライン名を入力
- デフォルトの形式: ft[ベースモデル][タイムスタンプ]
- 50文字以内で編集可能
-
パイプラインの説明を入力(最大 200文字)
-
確定する前に設定を確認します。
-
テンプレートとして保存 (任意)
- デフォルトの形式: ft[ベースモデル][タイムスタンプ]_template
- 100文字以内で編集可能
5.「終了」をクリックして 、パイプラインを作成します。
パイプラインは、「開始」ボタンをクリックして手動で開始するか、スケジュールに基づいて実行するように設定できます。
© 2025 FPT Cloud. All Rights Reserved.