- 紹介
-
 新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
アプリケーションの容量と可用性を向上
新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
アプリケーションの容量と可用性を向上 あらゆる業務ワークロードに対応するスループットと容量の多様性
あらゆる業務ワークロードに対応するスループットと容量の多様性 データのバックアップと復元を瞬時に、安全に、データの整合性を保ちながら行います。
データのバックアップと復元を瞬時に、安全に、データの整合性を保ちながら行います。 ビジネスコストを最大90%削減
ビジネスコストを最大90%削減 包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
迅速な拡張性を備えた先進の仮想サーバーサービス
包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
迅速な拡張性を備えた先進の仮想サーバーサービス FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します
FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します 3D レンダリング、AI、ML 用の仮想サーバーと統合
3D レンダリング、AI、ML 用の仮想サーバーと統合 今すぐ独占的な先行予約を確保し、 NVIDIAの強力なテクノロジー によって駆動される
今すぐ独占的な先行予約を確保し、 NVIDIAの強力なテクノロジー によって駆動される
AI開発のための オールインクルーシブスタックへの 優先アクセスを手に入れましょう!
今すぐ独占的な先行予約を確保し、 NVIDIAの強力なテクノロジー によって駆動される
AI開発のための オールインクルーシブスタックへの 優先アクセスを手に入れましょう!
3D レンダリング、AI、ML 用の仮想サーバーと統合
迅速な拡張性を備えた先進の仮想サーバーサービス
ビジネスコストを最大90%削減
独立したインフラで強力なパフォーマンス サービスは、すべてのサイズでAPIを初期化、維持、管理、保護します
サービスは、すべてのサイズでAPIを初期化、維持、管理、保護します
 FPT Kubernetes Engineでアプリケーションを迅速に作成、管理、展開するソリューションを提供します
コンテナ画像の保存、管理、デプロイ、セキュリティ保護が容易
FPT Kubernetes Engineでアプリケーションを迅速に作成、管理、展開するソリューションを提供します
コンテナ画像の保存、管理、デプロイ、セキュリティ保護が容易
 スマート管理サービス
スマート管理サービス 企業向けの仮想コンピューターサービス
いつでも、どこでも、どんなプラットフォームでものシステム監視ソリューション
企業向けの仮想コンピューターサービス
いつでも、どこでも、どんなプラットフォームでものシステム監視ソリューション 高度なGPU処理と統合されたKubernetesサービスにより、高パフォーマンスのアプリケーション開発を加速
サービスとして提供され、クラウドでのMongoDBデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
高度なGPU処理と統合されたKubernetesサービスにより、高パフォーマンスのアプリケーション開発を加速
サービスとして提供され、クラウドでのMongoDBデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする "サービスとして提供され、クラウドでのMySQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのPostgreSQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのRedisデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
アプリケーションの容量と可用性を向上
FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します
包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
無制限のストレージ、安全で保証されたパフォーマンス、継続的で高いデータ検索ニーズ
あらゆる業務ワークロードに対応するスループットと容量の多様性
"サービスとして提供され、クラウドでのMySQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのPostgreSQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのRedisデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
アプリケーションの容量と可用性を向上
FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します
包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
無制限のストレージ、安全で保証されたパフォーマンス、継続的で高いデータ検索ニーズ
あらゆる業務ワークロードに対応するスループットと容量の多様性 - 価格表
- パートナー
- イベント
テストモデルの応答
テストモデルの応答
セッションを選択して、モデルの応答を確認します。その後、システムはテストプレイグラウンドを開き、モデルを操作できます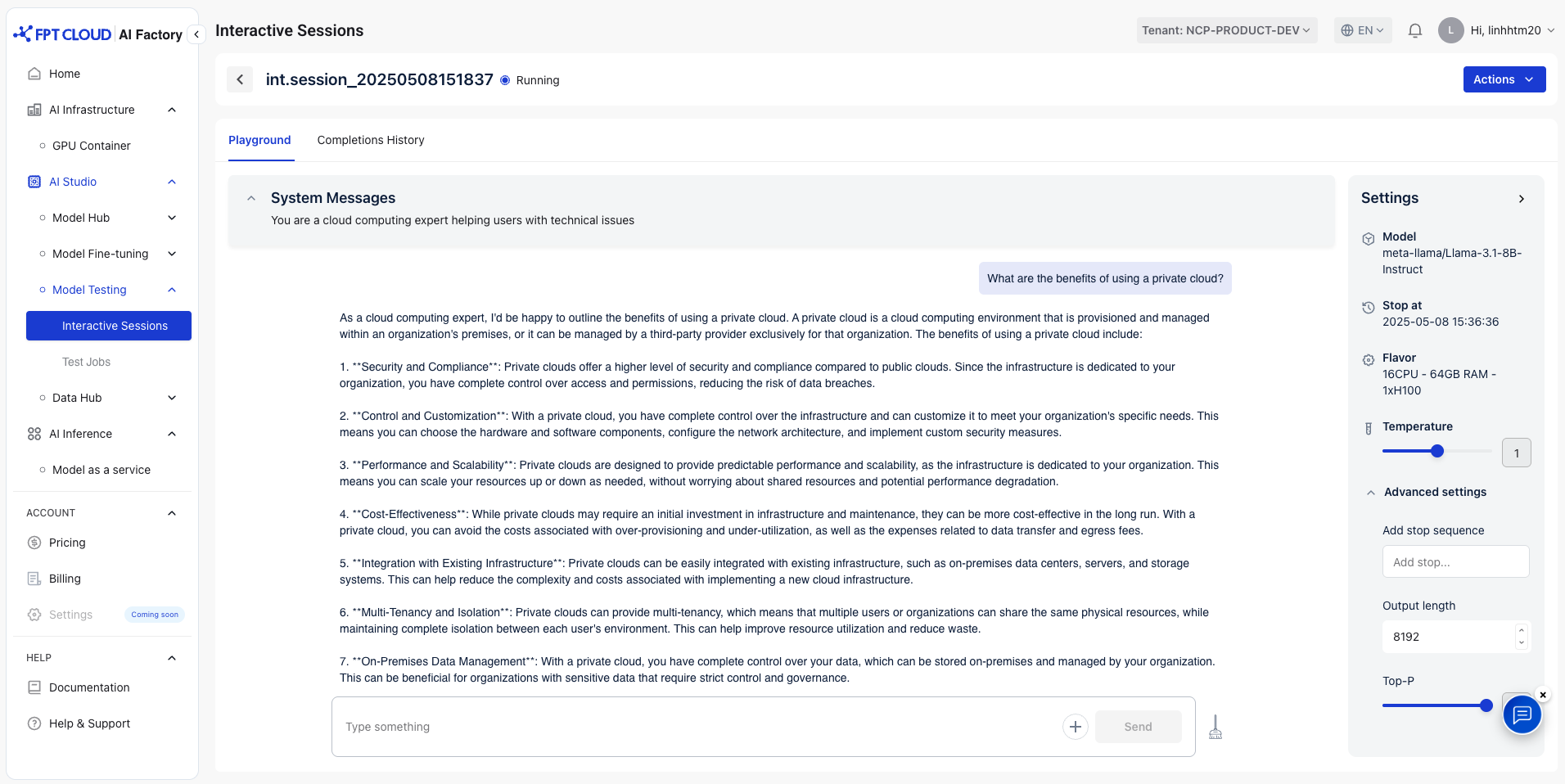
1. システムメッセージ
AI モデルの動作とトーンを設定する命令。会話全体を通じてモデルがどのように応答するかをガイドできます。
システムメッセージは、好みに基づいて変更できます。デフォルトメッセージ:「あなたは役立つアシスタントです」
例:あなたはクラウドコンピューティングの専門家であり、技術的な問題でユーザーをサポートしています。
2. ユーザーメッセージ
ユーザーがAIに提供したインプットまたは質問。モデルが会話で応答するメイン プロンプトとして機能します。
例: プライベートクラウドを使用する利点は何ですか?
VLM(Vision-Language Models)でのテスト用に、.jpegおよび.jpg形式での画像のアップロードをサポートしています。画像テストをサポートするモデル一覧:
- Meta-llama/Llama-3.2-11B-Vision-Instruct
- Qwen/Qwen2-VL-2B-Instruct
- Qwen/Qwen2-VL-7B-Instruct
- Qwen/Qwen2-VL-72B-Instruct
- Qwen/Qwen2.5-VL-3B-Instruct
- Qwen/Qwen2.5-VL-7B-Instruct
- Qwen/Qwen2.5-VL-72B-Instruct
- google/gemma-3-12b-it
- google/gemma-3-27b-it
- google/gemma-3-4b-it
3. 設定
- 温度:回答で許容される創造性は、通常0 から 2の範囲です。
デフォルト: 1
- 低温(0に近い):
- このモデルは、より予測可能で決定論的な応答を生成します。
- 確率の高い単語やトークンを優先し、より焦点を絞った正確な アウトプットを生成します。
- 高温(1以上):
- このモデルは、より創造的で多様で、予想外の応答を生成します。
- より広範な可能な単語からサンプリングされるため、アウトプットはより 多様になります が、精度が低下する可能性があります。
- 詳細設定:
- 停止シーケンスの追加:停止シーケンスを使用すると、検出時にモデルを停止する 1 つ以上のシーケンスを指定することで、生成されたテキストの長さと内容を制御できます。
- アウトプットの長さ: モデル内で生成されるテキストの長さを制御し、プロンプトに応答してモデルが生成できるトークン (単語またはサブワード) の最大数を設定します。デフォルト: 8192
- Top-P: 生成モデルで使用され、生成されたテキストのランダム性と多様性を管理し、モデルの出力分布からサンプリングする際の温度の代替として機能します。デフォルト: 0.95
アウトプットモデルの設定例:
- ストップシーケンスの追加:サードパーティ
- 出力長:1000
- Top-P:0.95
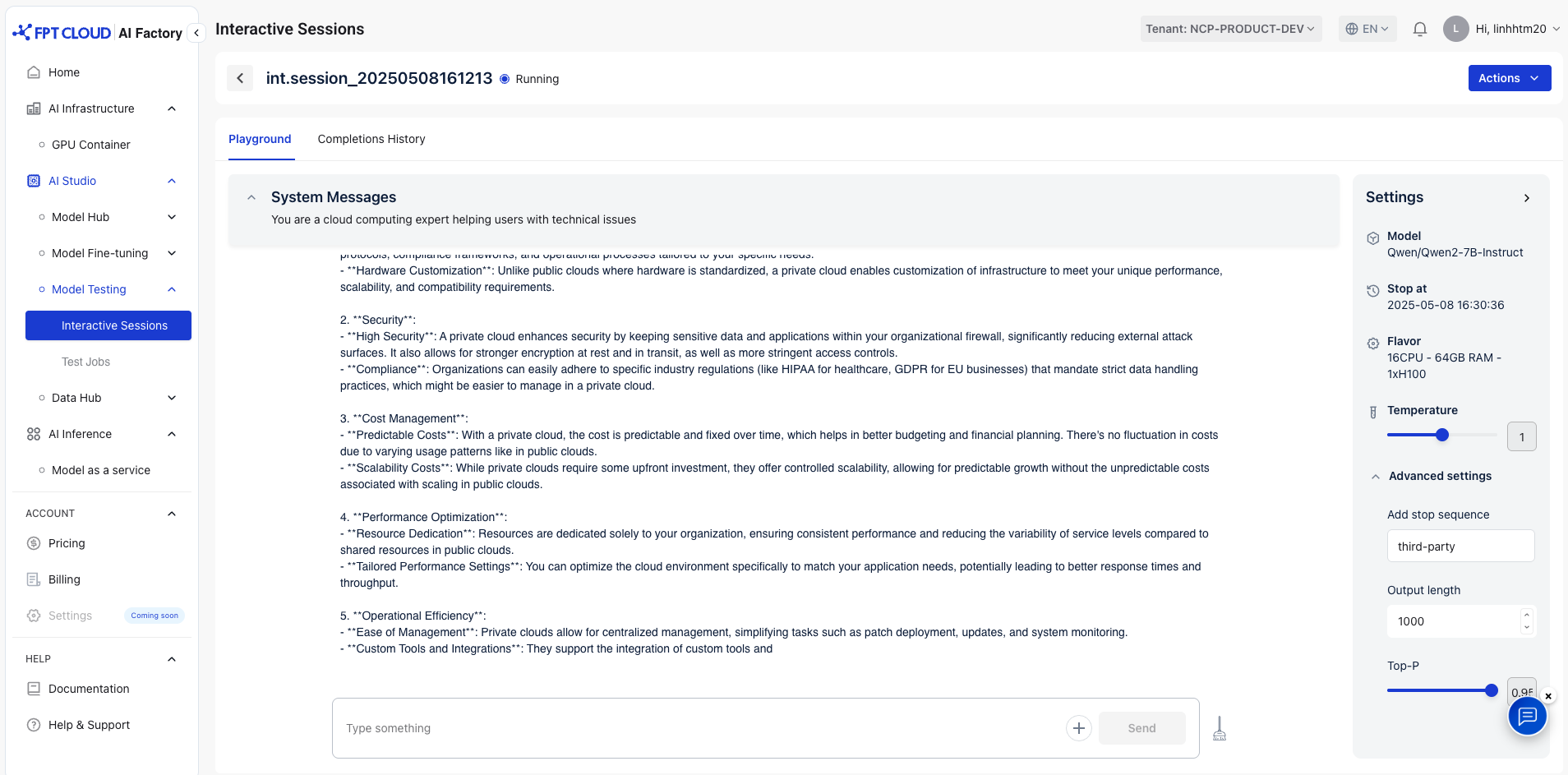
→ モデルは、停止シーケンスに遭遇するか、トークンの最大制限に達すると停止します。
© 2025 FPT Cloud. All Rights Reserved.