- 紹介
-
 新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
アプリケーションの容量と可用性を向上
新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
アプリケーションの容量と可用性を向上 あらゆる業務ワークロードに対応するスループットと容量の多様性
あらゆる業務ワークロードに対応するスループットと容量の多様性 データのバックアップと復元を瞬時に、安全に、データの整合性を保ちながら行います。
データのバックアップと復元を瞬時に、安全に、データの整合性を保ちながら行います。 ビジネスコストを最大90%削減
ビジネスコストを最大90%削減 包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
迅速な拡張性を備えた先進の仮想サーバーサービス
包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
迅速な拡張性を備えた先進の仮想サーバーサービス FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します
FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します 3D レンダリング、AI、ML 用の仮想サーバーと統合
3D レンダリング、AI、ML 用の仮想サーバーと統合 今すぐ独占的な先行予約を確保し、 NVIDIAの強力なテクノロジー によって駆動される
今すぐ独占的な先行予約を確保し、 NVIDIAの強力なテクノロジー によって駆動される
AI開発のための オールインクルーシブスタックへの 優先アクセスを手に入れましょう!
今すぐ独占的な先行予約を確保し、 NVIDIAの強力なテクノロジー によって駆動される
AI開発のための オールインクルーシブスタックへの 優先アクセスを手に入れましょう!
3D レンダリング、AI、ML 用の仮想サーバーと統合
迅速な拡張性を備えた先進の仮想サーバーサービス
ビジネスコストを最大90%削減
独立したインフラで強力なパフォーマンス サービスは、すべてのサイズでAPIを初期化、維持、管理、保護します
サービスは、すべてのサイズでAPIを初期化、維持、管理、保護します
 FPT Kubernetes Engineでアプリケーションを迅速に作成、管理、展開するソリューションを提供します
コンテナ画像の保存、管理、デプロイ、セキュリティ保護が容易
FPT Kubernetes Engineでアプリケーションを迅速に作成、管理、展開するソリューションを提供します
コンテナ画像の保存、管理、デプロイ、セキュリティ保護が容易
 スマート管理サービス
スマート管理サービス 企業向けの仮想コンピューターサービス
いつでも、どこでも、どんなプラットフォームでものシステム監視ソリューション
企業向けの仮想コンピューターサービス
いつでも、どこでも、どんなプラットフォームでものシステム監視ソリューション 高度なGPU処理と統合されたKubernetesサービスにより、高パフォーマンスのアプリケーション開発を加速
サービスとして提供され、クラウドでのMongoDBデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
高度なGPU処理と統合されたKubernetesサービスにより、高パフォーマンスのアプリケーション開発を加速
サービスとして提供され、クラウドでのMongoDBデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする "サービスとして提供され、クラウドでのMySQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのPostgreSQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのRedisデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
アプリケーションの容量と可用性を向上
FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します
包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
無制限のストレージ、安全で保証されたパフォーマンス、継続的で高いデータ検索ニーズ
あらゆる業務ワークロードに対応するスループットと容量の多様性
"サービスとして提供され、クラウドでのMySQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのPostgreSQLデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
サービスとして提供され、クラウドでのRedisデータベースのデプロイ、監視、バックアップ、復旧、拡張をサポートする
アプリケーションの容量と可用性を向上
FPT CloudとCyRadarの連携製品であるこのファイアウォールサービスは、Webアプリケーションを強力に保護します
包括的なスキャン能力、詳細な分析、およびセキュリティホールの評価を提供して、ビジネスアプリケーションシステムの情報セキュリティを強化します
新世代のファイアウォール・ソリューションは、綿密なセキュリティ機能により、ビジネス・アプリケーションとデータを包括的に保護します。
無制限のストレージ、安全で保証されたパフォーマンス、継続的で高いデータ検索ニーズ
あらゆる業務ワークロードに対応するスループットと容量の多様性 - 価格表
- パートナー
- イベント
定義: パイプラインとは、事前学習済みの機械学習モデルを特定のタスクまたはデータセットに適合させるために使用される構造化された一連のステップを指します。このパイプラインは、データの準備、モデルの構成、学習、評価、および微調整されたモデルの保存に関連するステージを自動化および整理します。
データサンプル : GitHub (link) にアクセスして、使用するサンプルデータを取得
モデル微調整サービスにアクセスし、「パイプライン管理」を選択し、「パイプライン作成」をクリックします。
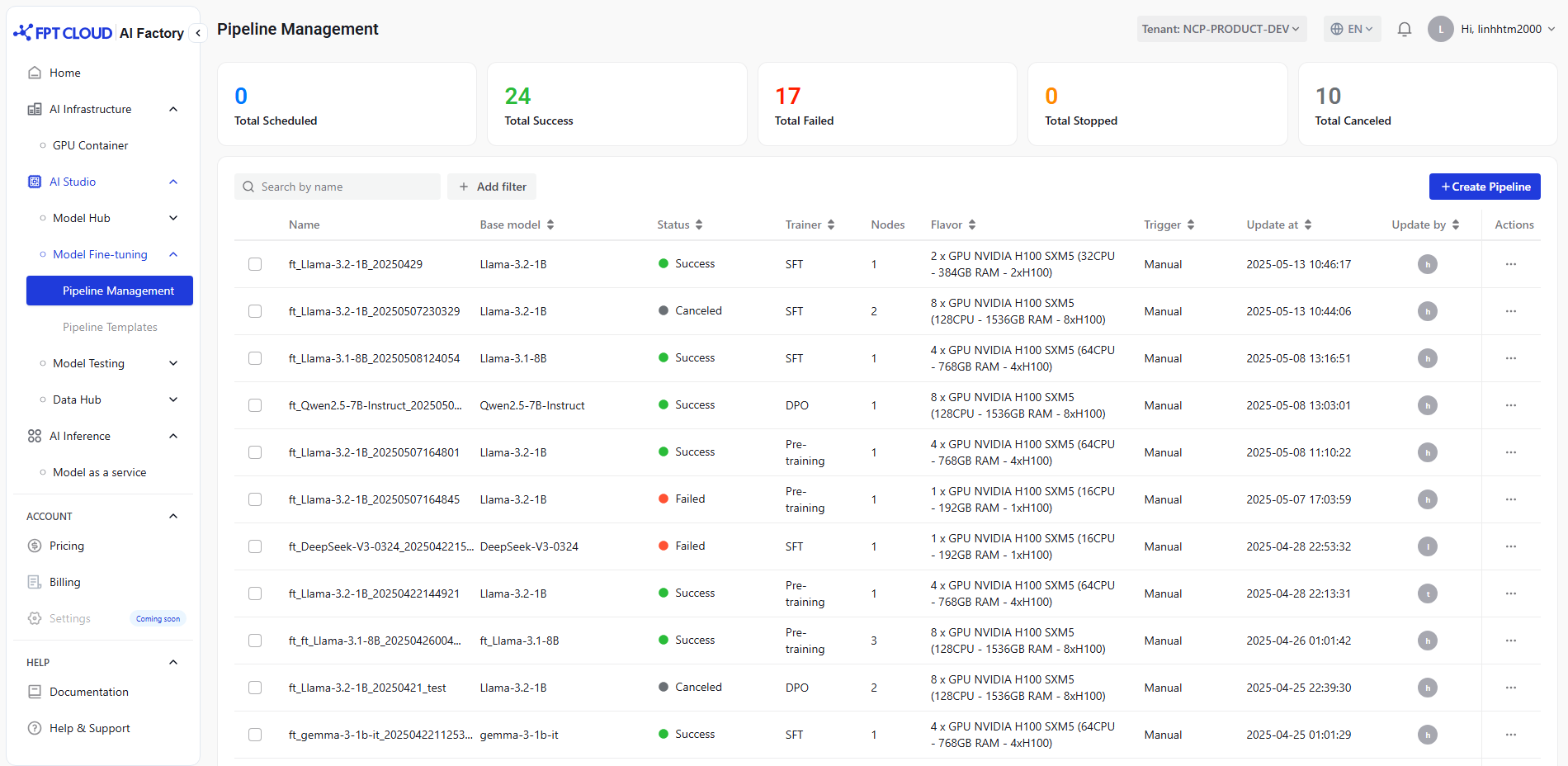
1. ベースモデルを選択します
- 現在、ファインチューニング用のベースモデルを提供しています。
| ベースモデル | 説明 |
|---|---|
| Llama-3.1-8B | 基本言語モデル、80億パラメータ、汎用性、微調整に最適 |
| Llama-3.2-1B | 軽量ベースモデル、10億パラメータ、高速、効率的、エッジ使用に最適 |
| Llama-3.2-8B-Instruct | インストラクショナルチューニングモデル、80億パラメータ、対話とタスクに最適化 |
| Llama-3.2-11B-Vision-Instruct | ビジョン言語タスクに最適化されたマルチモーダル命令調整モデル、110億 パラメーター |
| Llama-3.3-70B-Instruct | インストラクションチューニングされたLLaMAモデル、700億パラメータ、複雑なタスクに優れています |
| Meta-Llama-3-8B-Instruct | インストラクショナルチューニングされたLLaMAモデル、80億パラメータ、会話型タスクに最適化 |
| Qwen2-0.5B-Instruct | 小型の命令調整モデル、5億パラメータ、軽量でタスク効率が良い |
| Qwen2-VL-7B-Instruct | マルチモーダルインストラクションチューニングモデル、70億パラメーター、効率的な視覚言語理解 |
| Qwen2-VL-72B | マルチモーダル基本モデル、720億パラメータ、視覚と言語の両方を処理 |
| Qwen2-VL-72B-Instruct | マルチモーダルインストラクションチューニングモデル、720億パラメータ、視覚言語の理解と生成 |
| Qwen2.5-0.5B-Instruct | インストラクチャリング調整モデルの更新、5億パラメータ、効率の向上、タスク処理 |
| Qwen2.5-14B-Instruct | インストラクショナルチューニング言語モデル、140億パラメータ、バランスの取れた電力と効率 |
| Qwen2.5-32B-Instruct | インストラクショナルチューニング言語モデル、320億パラメータ、タスクの理解に強い |
| Qwen2.5-VL-72B-Instruct | マルチモーダル命令調整モデル、720億パラメータ、ビジョン言語タスクに優れています |
| Mixtral-8x7B-v0.1 | スパース混合専門家モデル、8エキスパート、高効率、強力なパフォーマンス |
| Mixtral-8x22B-v0.1 | 大規模な混合専門家モデル、8×22B エキスパート、スケーラブル、効率的、強力な推論 |
| Mixtral-8x22B-Instruct-v0.1 | インストラクションチューニングされた混合専門家モデル、8×22Bのエキスパートは、次のタスクに優れています |
| DeepSeek-R1 | DeepSeekによる基盤言語モデル、汎用性、強力、オープンソース |
| DeepSeek-R1-Distill-Llama-70B | LlaMA700億から抽出された効率的な言語モデル、最適化されたパフォーマンス |
| DeepSeek-R1-V3-0324 | 高度な多言語モデル、最新のDeepSeekバージョン、多様なタスクに最適化 |
注:独自モデルをアップロードする場合は、お問い合わせください!
2. データ形式を選択する
- 現在、微調整にサポートされているデータ形式は次のとおりです。
| データ形式 | 説明 | データ構造 | ファイル形式 |
|---|---|---|---|
| Alpaca | 監視された微調整タスクのための入力とアウトプットのペアを持つ命令追従形式 | {instruction, input, output} | json、zip 圧縮 |
| Corpus | モデルの学習と評価に使用される大規模な構造化テキストコレクション | {text} | json、zip 圧縮 |
| ShareGPT | ShareGPTデータセットでトレーニングされ、会話の応答を改善 | multi-turn chats / {conversations [from, value]} | json、zip 圧縮 |
| ShareGPT_Image | マルチモーダル(テキストおよび画像)処理に最適化 | multi-turn chats / {conversations [from, value]} + image_path | zip:train.jsonとフォルダの画像 |
- 注:各データセットには、少なくとも 50 個のサンプルが含まれている必要があります。
データ形式の詳細については、こちらをご覧ください https://fptcloud.com/en/documents/model-fine-tuning/?doc=select-data-formathttps://fptcloud.com/en/documents/model-fine-tuning/?doc=select-data-format
3. データセットを準備する
- トレーニング/評価データセットをアップロードするには、次の 2 つの方法があります。
- ファイルをアップロード:対応形式:ZIP(zip2回)、JSON(最大:100MB)
- 接続を選択:接続を選択し、バケット内のオブジェクトへのパスを入力
接続を選択する前に、データハブにアクセスし、データソースを選択し、バケットのエンドポイントURLを入力し、アクセスキーとシークレット キーを指定して接続を作成する必要があります。 接続作成ガイドは、こちらで参照できます https://fptcloud.com/en/documents/data-hub/?doc=create-connection
- データサンプル : GitHub(リンク)にアクセスして、使用するサンプルデータを取得
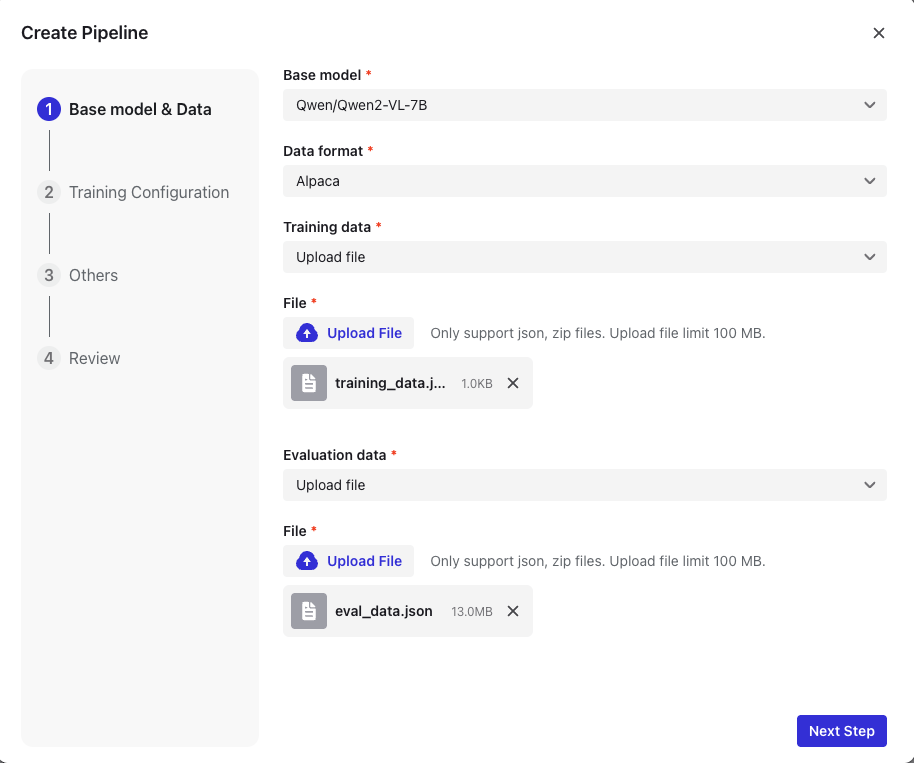
4. トレーニング設定
- トレーナーを選択
| トレーナー | 説明 | サポートのデータ形式 |
|---|---|---|
| 事前学習 | 言語理解のためのラベル付けされていない大きなデータを使用した初期トレーニング フェーズ | Corpus |
| SFT | 監視された微調整トレーナー、ラベル付きデータを使用してモデルの動作を調整 | Alpaca/ShareGPT/ |
| ShareGPT_Image | ||
| DPO | 直接的な嗜好最適化トレーナーは、モデルを人間の嗜好信号と直接調整します | シェアGPT/ShareGPT_Image |
5. ハイパーパラメータの設定
| パラメーター | 説明 | 種類 | 対応値 | 既定値 |
|---|---|---|---|---|
| learning_rate | トレーニングの学習率 | float | [0.00001-0.001] | 0.00001 |
| batch_size | トレーニングのバッチ サイズ。分散トレーニングの場合、これは各デバイスのバッチサイズです | int | 更新 | 1 |
| epochs | トレーニングエポックの数 | Int | 更新 | 1 |
| gradient_accumulation_steps | 逆方向/更新パスを実行する前に、勾配を蓄積する更新ステップの数 | int | 更新 | 4 |
| checkpoint_steps | 2 つのチェックポイントが保存される前のトレーニング ステップの数 save_strategy="steps"の場合 | int | 更新 | 1000 |
| max_sequence_length | 最大入力長、より長いシーケンスはこの値にカットオフされます | int | 更新 | 2048 |
| finetuning_type | 使用するパラメータモード | enum[string] | lora/full | lora |
| distributed_backend | 分散トレーニングに使用するバックエンド。デフォルトは ddp | enum[string] | ddp/deepseed | ddp |
| deepspeed_zero_stage | DeepSpeed ZeROアルゴリズムを適用するステージdistributed_backend=deepspeedの場合にのみ適用 | enum[int] | 1/2/3 | 1 |
ハイパーパラメータの詳細については、こちらをご覧ください https://fptcloud.com/en/documents/model-fine-tuning/?doc=set-hyperparameters
6. トレーニングノードを選択します
- シングルノード構成とマルチノード構成の両方をサポートし、最大16ノード
7. トリガーの微調整
| トリガー | 説明 |
|---|---|
| 手動 | ユーザーが開始する微調整。 |
| スケジュール | 設定されたスケジュールに基づく自動微調整。 |
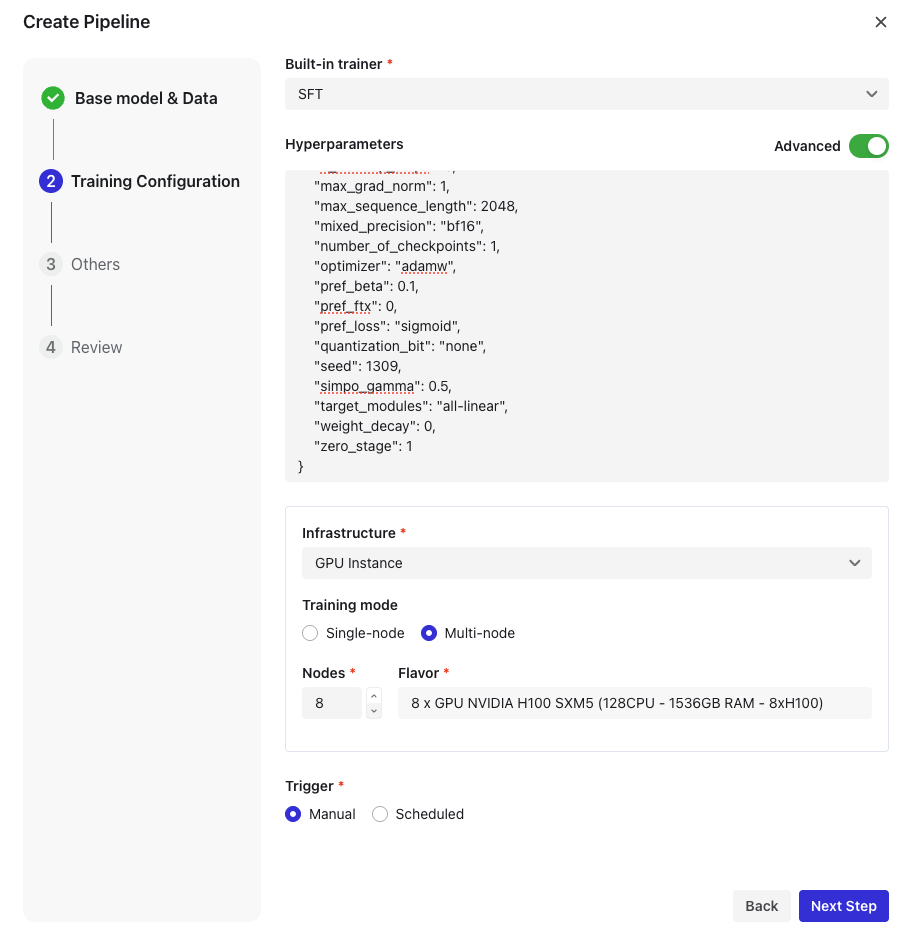
8. 追加設定
- テストデータ(ZIP、JSON最大100MB)をアップロード
- チェックポイント数を設定
- 電子メール通知を有効にする:パイプラインを作成するアカウントにメール通知が送信されます
9. レビューとファイナライズ
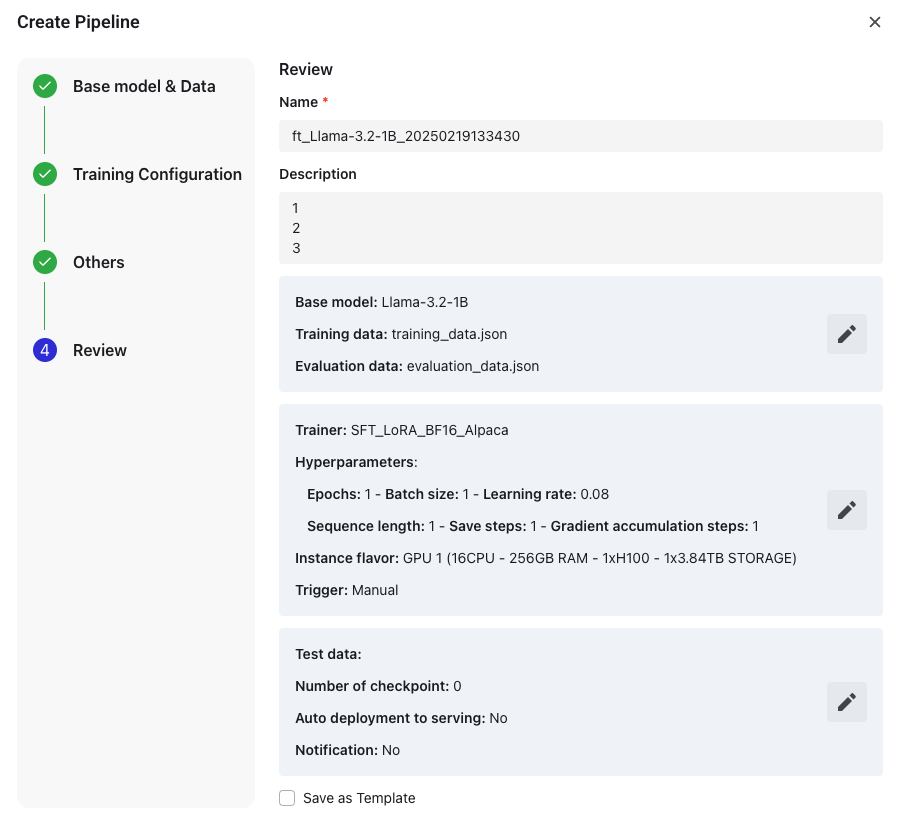
- パイプライン名を入力
- デフォルトの形式:
ft_[基本モデル]_[タイムスタンプ] - 50文字以内で編集可能
- デフォルトの形式:
- パイプラインの説明を入力( 最大 200文字)
- 確定する前に設定を確認します。
- テンプレートとして保存 (任意)
- デフォルトの形式:
ft_[基本モデル]_[タイムスタンプ]_template - 100文字以内で編集可能
- デフォルトの形式:
- 「終了」をクリックして 、パイプラインを作成します。
パイプラインは、「開始」をクリックして手動で開始するか、スケジュールに従って実行するように設定できます。