- About Us
-
 Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand. Virtual server integration for 3D Rendering, AI or ML
Virtual server integration for 3D Rendering, AI or ML Enhance application capacity and availability.
Enhance application capacity and availability. Secure your exclusive advance order today and gain priority access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Secure your exclusive advance order today and gain priority access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology! FPT Web Application Firewall provides powerful protection for web applications
FPT Web Application Firewall provides powerful protection for web applications Advanced virtual server with rapid scalability
Advanced virtual server with rapid scalability Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Secure your exclusive advance order today and gain priority access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Secure your exclusive advance order today and gain priority access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
 Diverse throughput and capacity to meet various business workloads.
Diverse throughput and capacity to meet various business workloads.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
FPT Web Application Firewall provides powerful protection for web applications
Intelligent and Comprehensive Virtual Web Application Firewall - Security Collaboration between FPT Cloud and Penta Security.
The Next generation firewall security service
Easily store, manage, deploy, and secure Container images
Safe, secure, stable, high-performance Kubernetes platform
Provided as a service to deploy, monitor, backup, restore, and scale MongoDB databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale Redis databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale PostgreSQL databases on cloud. Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling.
Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling. - Pricing
- Partner
- Event
Access the Model Testing service and choose Test Jobs tab, click button "Create New Job"
Step 1: Select a model
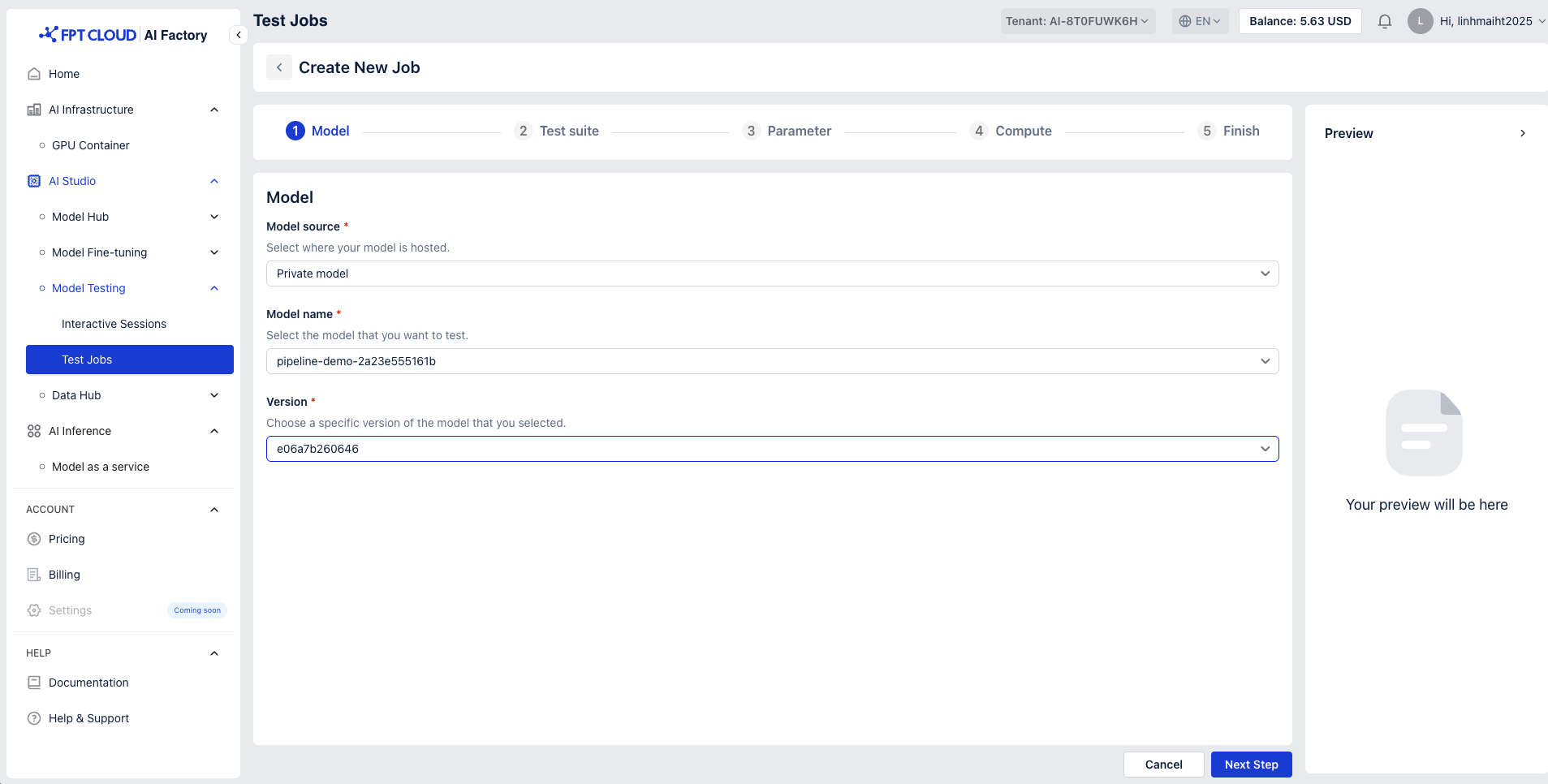
-
Model Source: Select where your model is hosted
You can choose between two model sources when configuring your setup:
- Catalog
- When Catalog is selected as the source, the system will display a list of all available models from the Model Catalog.
- This option is suitable when you want to browse or select from predefined, public models.
- Private Model
- When Private Model is selected, only your organization’s custom or privately uploaded models will be shown.
- Select a model and make sure to select the correct version you want to test.
- Use this option if you want to work with models that are not publicly listed in the catalog.
- Catalog
- Model Name: Select the model that you want to test
Step 2: Test suite settings
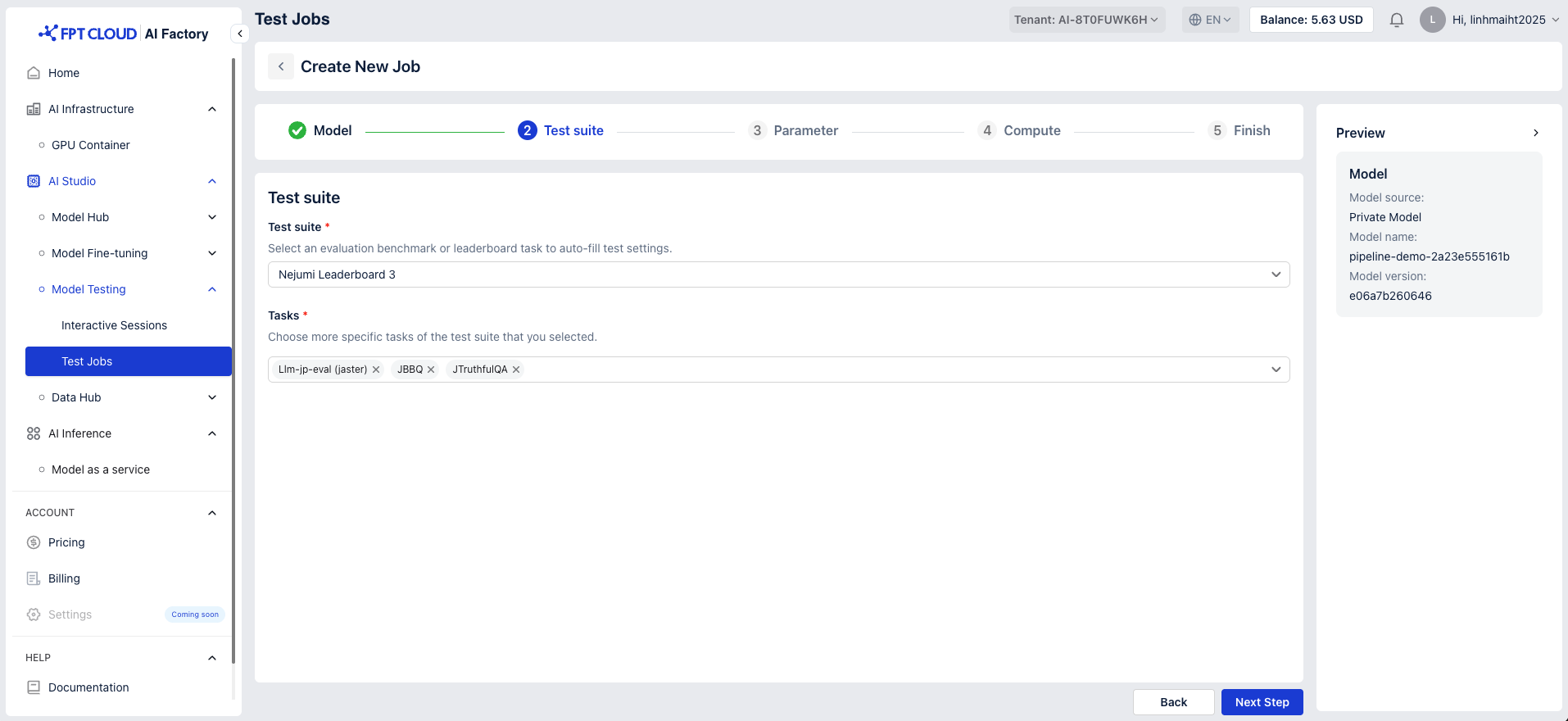
A test suite is a collection of test cases designed to evaluate the performance, accuracy, and stability of a machine learning model.
-
Test suite: Select an evaluation benchmark or leader board task to auto-fill test settings
Support is currently limited to the Nejumi Leaderboard 3 - benchmarking Japanese LLMs on language skills and alignment, using diverse datasets for performance and safety evaluation.
-
Tasks: Choose more specific tasks of the test suite that you selected.
Nejumi Leaderboard 3 provides specific tasks such as Llm-jp-eval (jaster), JBBQ and JTruthfulQA. You can choose to view results for all tasks or select a single task
- Llm-jp-eval (jaster): A benchmark dataset designed to evaluate Japanese language models on a wide range of general language processing tasks, including reading comprehension, reasoning, and semantic understanding.
- JBBQ: A dataset focused on detecting and measuring biases in Japanese language models, evaluating fairness and sensitivity to biased or harmful content.
- JTruthfulQA: JTruthfulQA is a QA dataset designed to measure the truthfulness a Japanese language model outputs.
Hover over each option to view detailed information about the tasks
Step 3: Set parameters
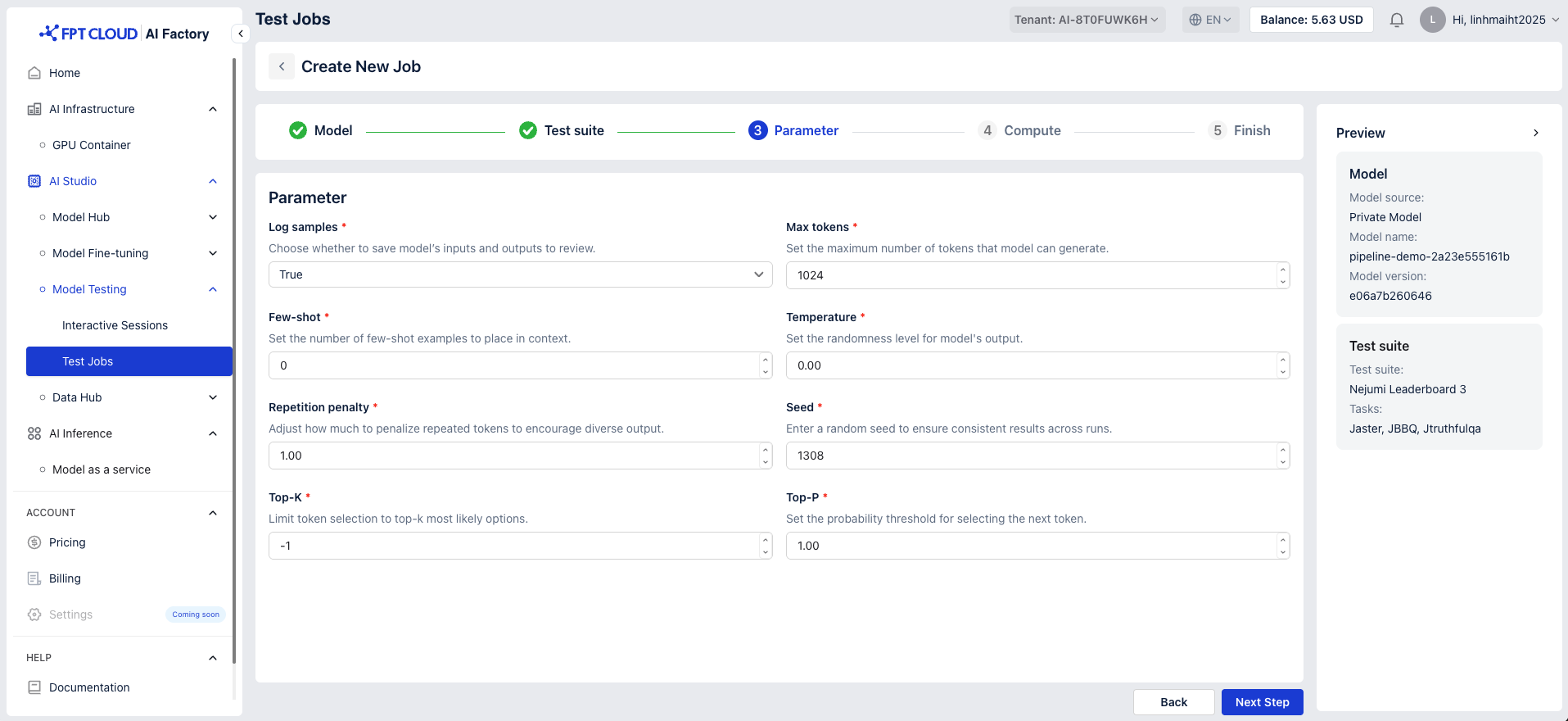
| Parameters | Description | Default value |
|---|---|---|
| Log samples | Choose whether to save model’s inputs and outputs to review | True |
| Max tokens | Set the maximum number of tokens that model can generate. | 1024 |
| Few-shot | Set the number of few-shot examples to place in context. | 0 |
| Temperature | Set the randomness level for model's output | 0.00 |
| Repetition penalty | Adjust how much to penalize repeated tokens to encourage diverse output. | 1.00 |
| Seed | Enter a random seed to ensure consistent results across runs. | 1308 |
| Top-K | Limit token selection to top-k most likely options. | -1 |
| Top-P | Set the probability threshold for selecting the next token. | 1.00 |
Step 4: Select GPU configuration
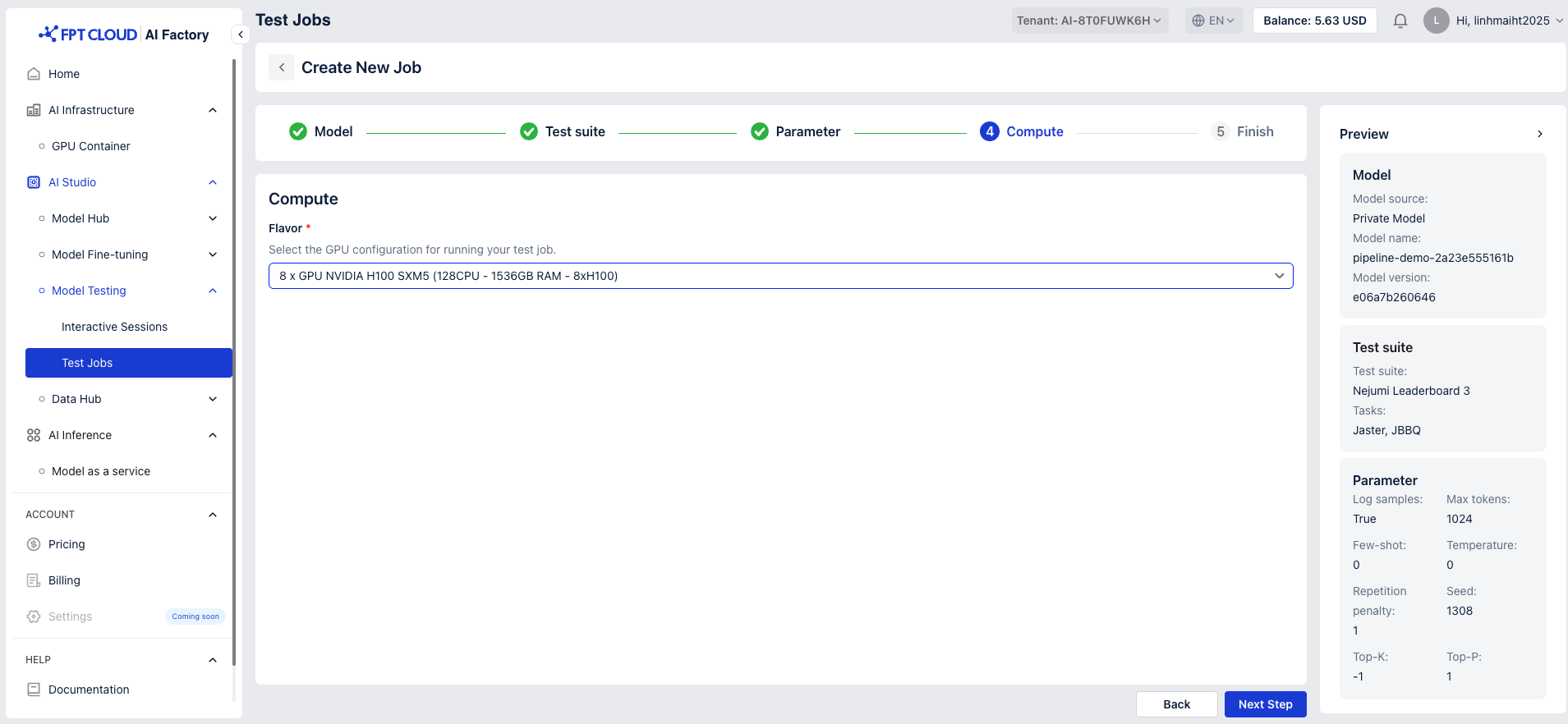
Select the GPU configuration for running your test job.
- 1 x GPU NVIDIA H100 SXM5 (16CPU - 192GB RAM - 1xH100)
- 2 x GPU NVIDIA H100 SXM5 (32CPU - 384GB RAM - 2xH100)
- 4 x GPU NVIDIA H100 SXM5 (64CPU - 768GB RAM - 4xH100)
- 8 x GPU NVIDIA H100 SXM5 (128CPU - 1536GB RAM - 8xH100)
Step 5: Finish & Review
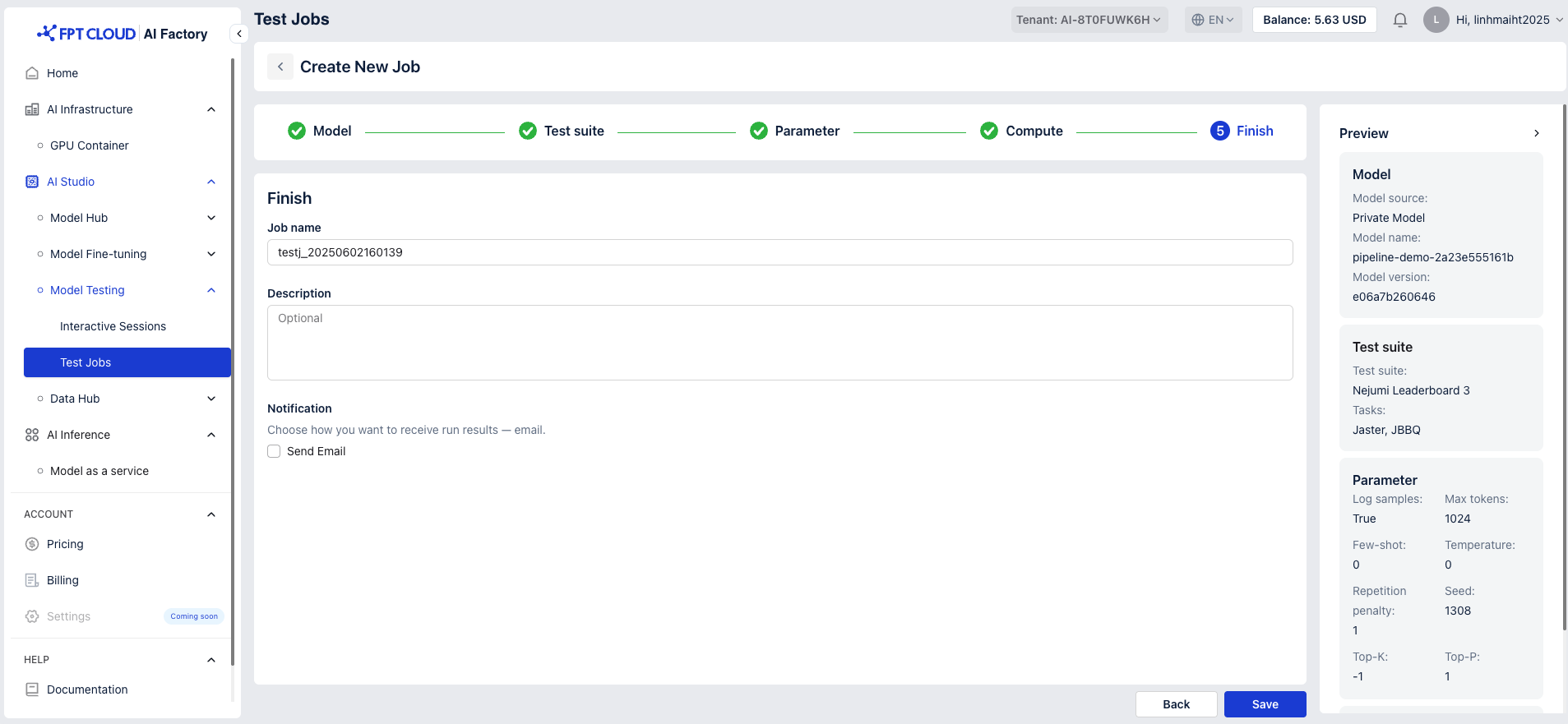
- Enter Job Name
- Default format:
ft_[base model]_[timestamp] - Editable with a 50-character limit
- Default format:
- Enter Job Description (Max 200 characters)
- Notification: Choose how you want to receive run results - email
- Click “Save”
You can manually run the job by clicking the Run button