- About Us
-
 Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand. Virtual server integration for 3D Rendering, AI or ML
Virtual server integration for 3D Rendering, AI or ML Enhance application capacity and availability.
Enhance application capacity and availability. Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology! FPT Web Application Firewall provides powerful protection for web applications
FPT Web Application Firewall provides powerful protection for web applications Advanced virtual server with rapid scalability
Advanced virtual server with rapid scalability Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
 Diverse throughput and capacity to meet various business workloads.
Diverse throughput and capacity to meet various business workloads.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
FPT Web Application Firewall provides powerful protection for web applications
Intelligent and Comprehensive Virtual Web Application Firewall - Security Collaboration between FPT Cloud and Penta Security.
The Next generation firewall security service
Easily store, manage, deploy, and secure Container images
Safe, secure, stable, high-performance Kubernetes platform
Provided as a service to deploy, monitor, backup, restore, and scale MongoDB databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale Redis databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale PostgreSQL databases on cloud. Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling.
Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling. - Pricing
- Partner
- Event
Select a session to review the model's response. The system will then open a testing playground where you can interact with the model
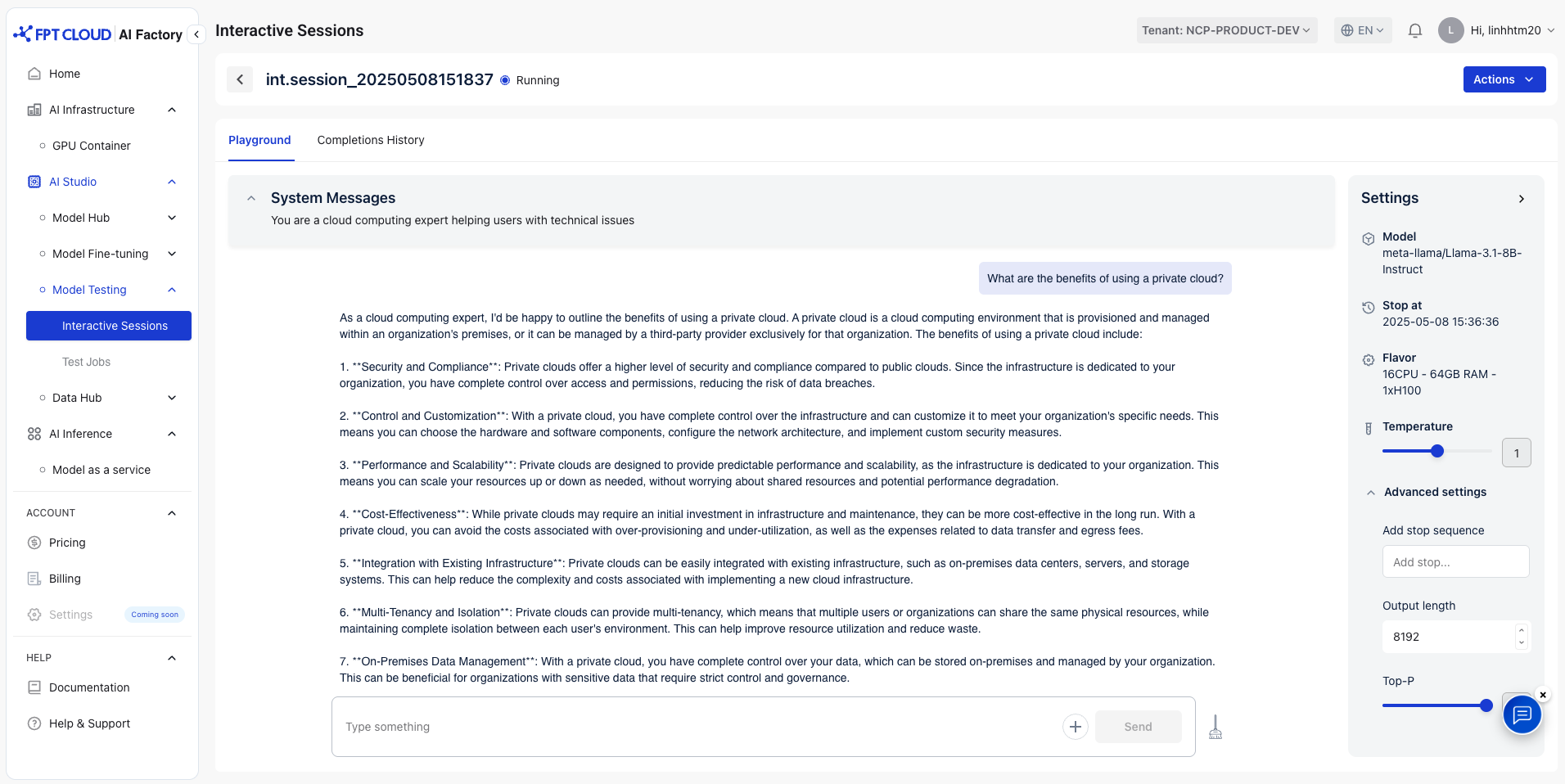
1. System Message
An instruction that sets the behavior and tone of the AI model. It helps guide how the model responds throughout the conversation.
You can modify the system message based on your preferences. Default message: "You are a helpful assistant"
Example: You are a cloud computing expert helping users with technical issues
2. User message
The input or question provided by the user to the AI. It serves as the main prompt that the model responds to in a conversation.
Example: What are the benefits of using a private cloud?
We support uploading images in .jpeg and .jpg formats for testing with VLM (Vision-Language Models). List models supporting image testing
- meta-llama/Llama-3.2-11B-Vision-Instruct
- Qwen/Qwen2-VL-2B-Instruct
- Qwen/Qwen2-VL-7B-Instruct
- Qwen/Qwen2-VL-72B-Instruct
- Qwen/Qwen2.5-VL-3B-Instruct
- Qwen/Qwen2.5-VL-7B-Instruct
- Qwen/Qwen2.5-VL-72B-Instruct
- google/gemma-3-12b-it
- google/gemma-3-27b-it
- google/gemma-3-4b-it
3. Settings:
- Temperature: Creativity allowed in the responses, typically ranges from 0 to 2. Default: 1
- Low Temperature (closer to 0):
- The model generates more predictable, deterministic responses.
- It favors high-probability words or tokens, producing more focused and precise output.
- High Temperature (closer to 1 or higher):
- The model generates more creative, diverse, and unexpected responses.
- It samples from a wider range of possible words, making the output more varied but potentially less accurate.
- Low Temperature (closer to 0):
- Advanced settings:
- Add stop sequence: The stop sequence allows you to control the length and content of the generated text by specifying one or more sequences that, when detected, will cause the model to halt.
- Output length: Controls the length of the generated text in a model, setting the maximum number of tokens (words or subwords) the model can produce in response to a prompt.. Default: 8192
- Top-P: Used in generative models to manage the randomness and diversity of generated text, serving as an alternative to temperature in sampling from the model's output distribution. Default: 0.95
Example Model Output with These Settings:
- Add Stop Sequence: Third-party
- Output length: 1000
- Top-P: 0.95
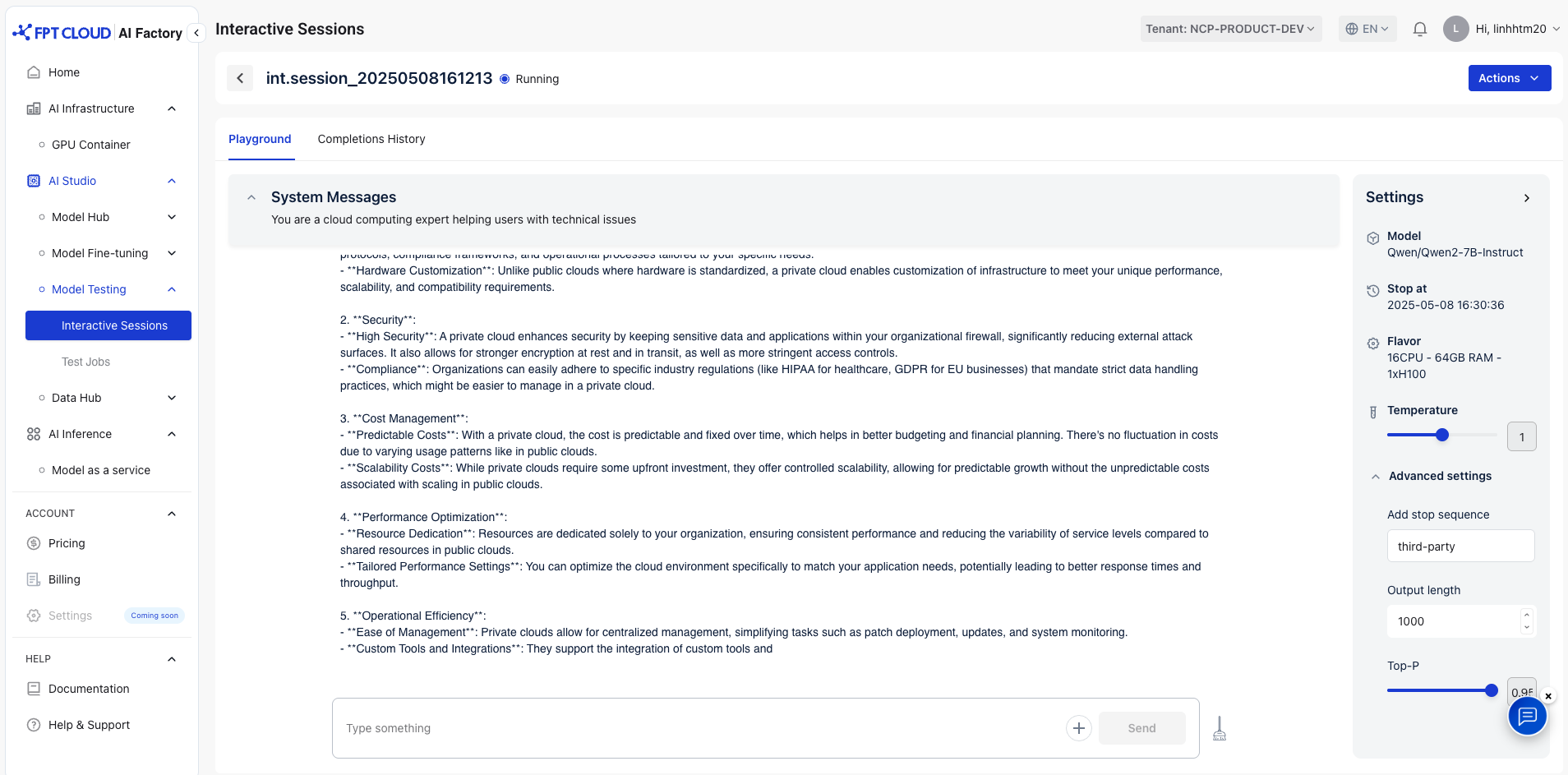
→ Model will stop either when it encounters a stop sequence or reaches the maximum token limit.
