- About Us
-
 Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand. Virtual server integration for 3D Rendering, AI or ML
Virtual server integration for 3D Rendering, AI or ML Enhance application capacity and availability.
Enhance application capacity and availability. Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology! FPT Web Application Firewall provides powerful protection for web applications
FPT Web Application Firewall provides powerful protection for web applications Advanced virtual server with rapid scalability
Advanced virtual server with rapid scalability Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
 Diverse throughput and capacity to meet various business workloads.
Diverse throughput and capacity to meet various business workloads.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
FPT Web Application Firewall provides powerful protection for web applications
Intelligent and Comprehensive Virtual Web Application Firewall - Security Collaboration between FPT Cloud and Penta Security.
The Next generation firewall security service
Easily store, manage, deploy, and secure Container images
Safe, secure, stable, high-performance Kubernetes platform
Provided as a service to deploy, monitor, backup, restore, and scale MongoDB databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale Redis databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale PostgreSQL databases on cloud. System Monitoring Solution anywhere, anytime, anyplatform
System Monitoring Solution anywhere, anytime, anyplatform Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling.
Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling. - Pricing
- Partner
- Event

First of all, you must prepare the best dataset because it directly impacts how well the model performs on your intended use case.
Here’s what good dataset quality enables:
-
Collect examples to target remaining issues.
- If the model still isn't good at certain aspects, add training examples that directly show the model how to do these aspects correctly.
-
Scrutinize existing examples for issues.
- If your model has grammar, logic, or style issues, check if your data has any of the same issues. For instance, if the model now says "I will schedule this meeting for you" (when it shouldn't), see if existing examples teach the model to say it can do new things that it can't do
-
Consider the balance and diversity of data.
- If 60% of the assistant responses in the data says "I cannot answer this", but at inference time only 5% of responses should say that, you will likely get an overabundance of refusals.
-
Make sure your training examples contain all of the information needed for the response.
- If we want the model to compliment a user based on their personal traits and a training example includes assistant compliments for traits not found in the preceding conversation, the model may learn to hallucinate information.
-
Look at the agreement and consistency in the training examples.
- If multiple people created the training data, it's likely that model performance will be limited by the level of agreement and consistency between people. For instance, in a text extraction task, if people only agreed on 70% of extracted snippets, the model would likely not be able to do better than this.
-
Make sure all of your training examples are in the same format, as expected for inference.
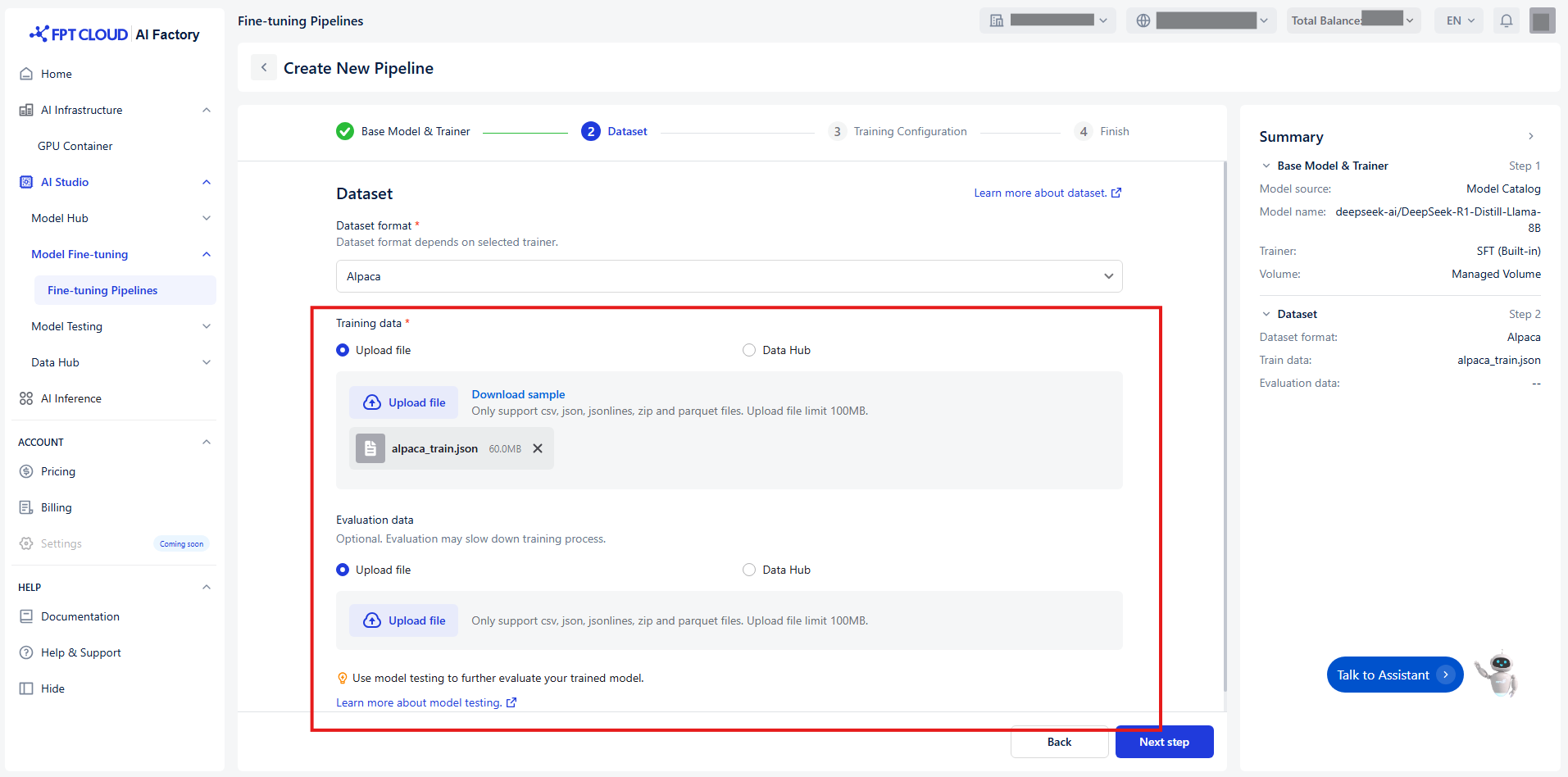
You have two ways to transfer the Training data and Evaluation data:
-
Upload a file
-
Default value Upload file
-
Choose a local file from your computer.
-
(Optional) Click Download sample to see an example of the expected format.
-
Notice: Ensure the file matches the selected data format
| Trainer | Supported data format | Supported file format | Supported file size |
|---|---|---|---|
| SFT | Alpaca | CSV JSON JSONLINES ZIP PARQUET |
Limit 100MB |
| SFT | ShareGPT | JSON JSONLINES ZIP PARQUET |
Limit 100MB |
| SFT | ShareGPT_Image | ZIP PARQUET |
Limit 100MB |
| DPO | ShareGPT | JSON JSONLINES ZIP PARQUET |
Limit 100MB |
| Pre-training | Corpus | TXT JSON JSONLINES ZIP PARQUET |
Limit 100MB |
-
Connect to Data Hub
-
Click Data Hub
-
Select a connection or dataset from the Data Hub. Notice: Ensure the dataset is compatible with the selected format.
-
(Optional) Click Open Data Hub to preview or manage datasets.
-
(Optional) Click Reload icon to update connection and dataset list.
-
Follow the detailed guide Data Hub
-