- About Us
-
 Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand. Virtual server integration for 3D Rendering, AI or ML
Virtual server integration for 3D Rendering, AI or ML Enhance application capacity and availability.
Enhance application capacity and availability. Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology! FPT Web Application Firewall provides powerful protection for web applications
FPT Web Application Firewall provides powerful protection for web applications Advanced virtual server with rapid scalability
Advanced virtual server with rapid scalability Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
 Diverse throughput and capacity to meet various business workloads.
Diverse throughput and capacity to meet various business workloads.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
FPT Web Application Firewall provides powerful protection for web applications
Intelligent and Comprehensive Virtual Web Application Firewall - Security Collaboration between FPT Cloud and Penta Security.
The Next generation firewall security service
Easily store, manage, deploy, and secure Container images
Safe, secure, stable, high-performance Kubernetes platform
Provided as a service to deploy, monitor, backup, restore, and scale MongoDB databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale Redis databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale PostgreSQL databases on cloud. System Monitoring Solution anywhere, anytime, anyplatform
System Monitoring Solution anywhere, anytime, anyplatform Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling.
Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling. - Pricing
- Partner
- Event

Select Trainer
Select Trainer
Select the appropriate trainer - which guides the model you select for training.
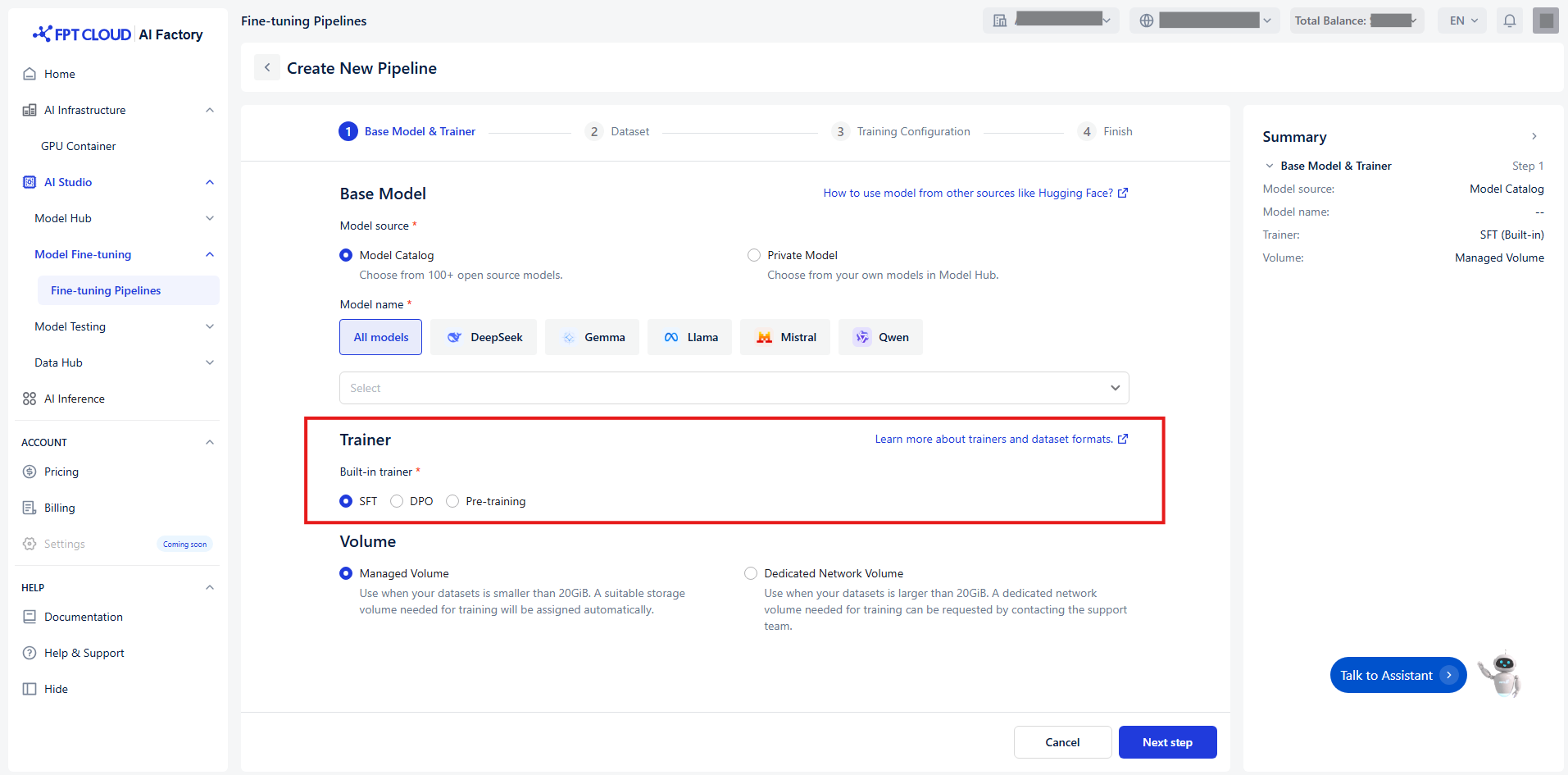
We offer three trainers to optimize your models:
| Trainer | Definition | How it works | Best for |
|---|---|---|---|
| SFT (Supervised fine-tuning) | Foundational technique that trains your model on input-output pairs, teaching it to produce desired responses for specific inputs. | - Provide examples of correct responses to prompts to guide the model’s behavior. - Often uses human-generated “ground truth” responses to show the model how it should respond. |
- Classification - Nuanced translation - Generating content in a specific format - Correcting instruction-following failures |
| DPO (Direct preference optimization) | Trains models to prefer certain types of responses over others by learning from comparative feedback, without requiring a separate reward model. | - Provide both correct and incorrect example responses for a prompt. - Indicate the correct response to help the model perform better. |
- Summarizing text, focusing on the right things - Generating chat messages with the right tone and style |
| Pre-training | Initial training phase using large unlabeled data for language understanding. | - Exposes the model to vast amounts of text data to learn grammar, facts, reasoning patterns, and world knowledge. - No labeled examples required. |
- Building foundational language understanding - Preparing models for downstream fine-tuning tasks |
© 2025 FPT Cloud. All Rights Reserved.