- About Us
-
 Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand. Virtual server integration for 3D Rendering, AI or ML
Virtual server integration for 3D Rendering, AI or ML Enhance application capacity and availability.
Enhance application capacity and availability. Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology! FPT Web Application Firewall provides powerful protection for web applications
FPT Web Application Firewall provides powerful protection for web applications Advanced virtual server with rapid scalability
Advanced virtual server with rapid scalability Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
 Diverse throughput and capacity to meet various business workloads.
Diverse throughput and capacity to meet various business workloads.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
FPT Web Application Firewall provides powerful protection for web applications
Intelligent and Comprehensive Virtual Web Application Firewall - Security Collaboration between FPT Cloud and Penta Security.
The Next generation firewall security service
Easily store, manage, deploy, and secure Container images
Safe, secure, stable, high-performance Kubernetes platform
Provided as a service to deploy, monitor, backup, restore, and scale MongoDB databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale Redis databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale PostgreSQL databases on cloud. System Monitoring Solution anywhere, anytime, anyplatform
System Monitoring Solution anywhere, anytime, anyplatform Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling.
Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling. - Pricing
- Partner
- Event





Finetune BERT on GLUE MRPC using Code Server
This guide will walk you through fine-tuning a pre-trained BERT model on the GLUE MRPC task using a GPU-enabled Code Server container.
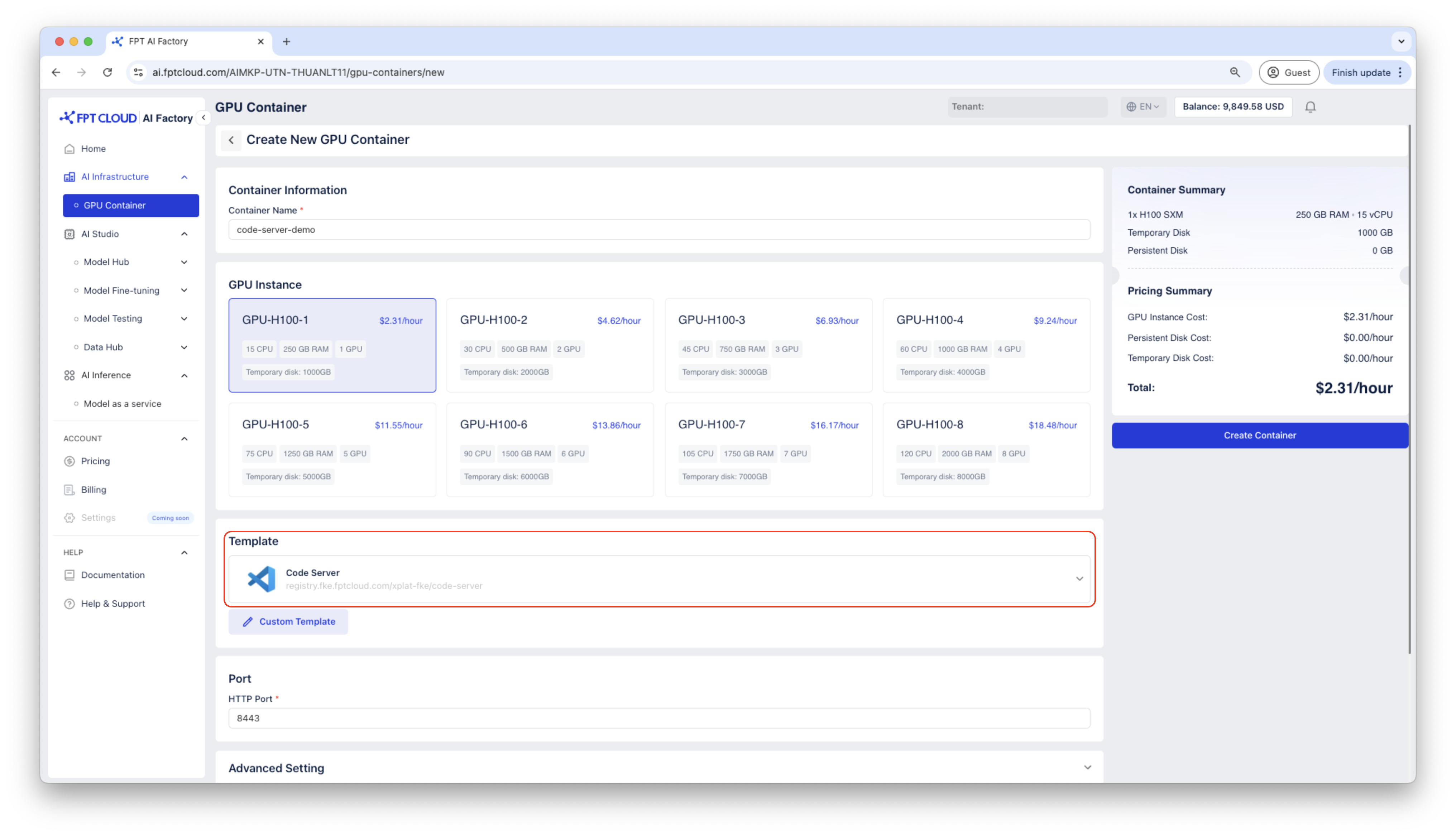
Step 1: Create a GPU Container
Create a container using Code Server template.
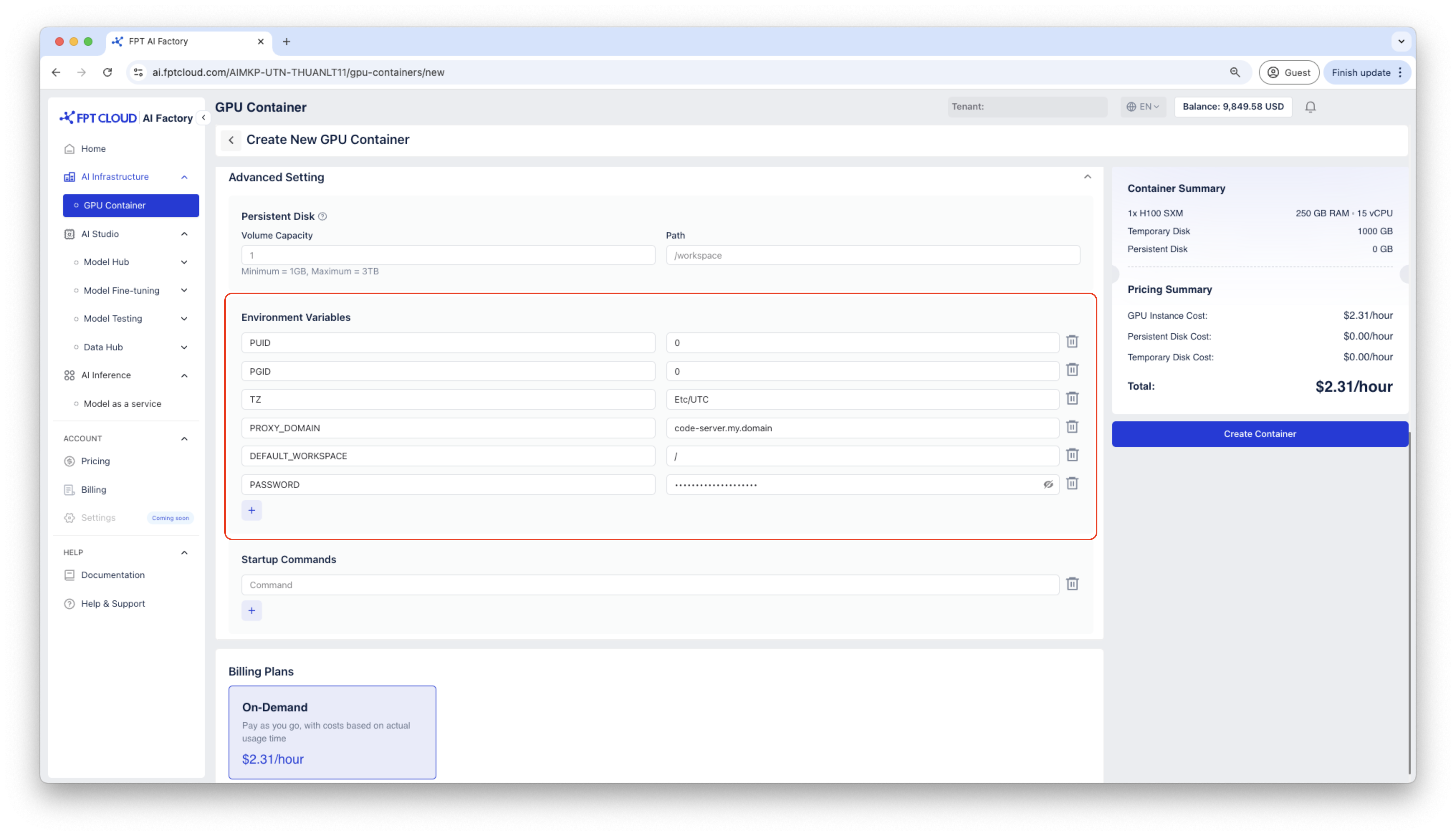
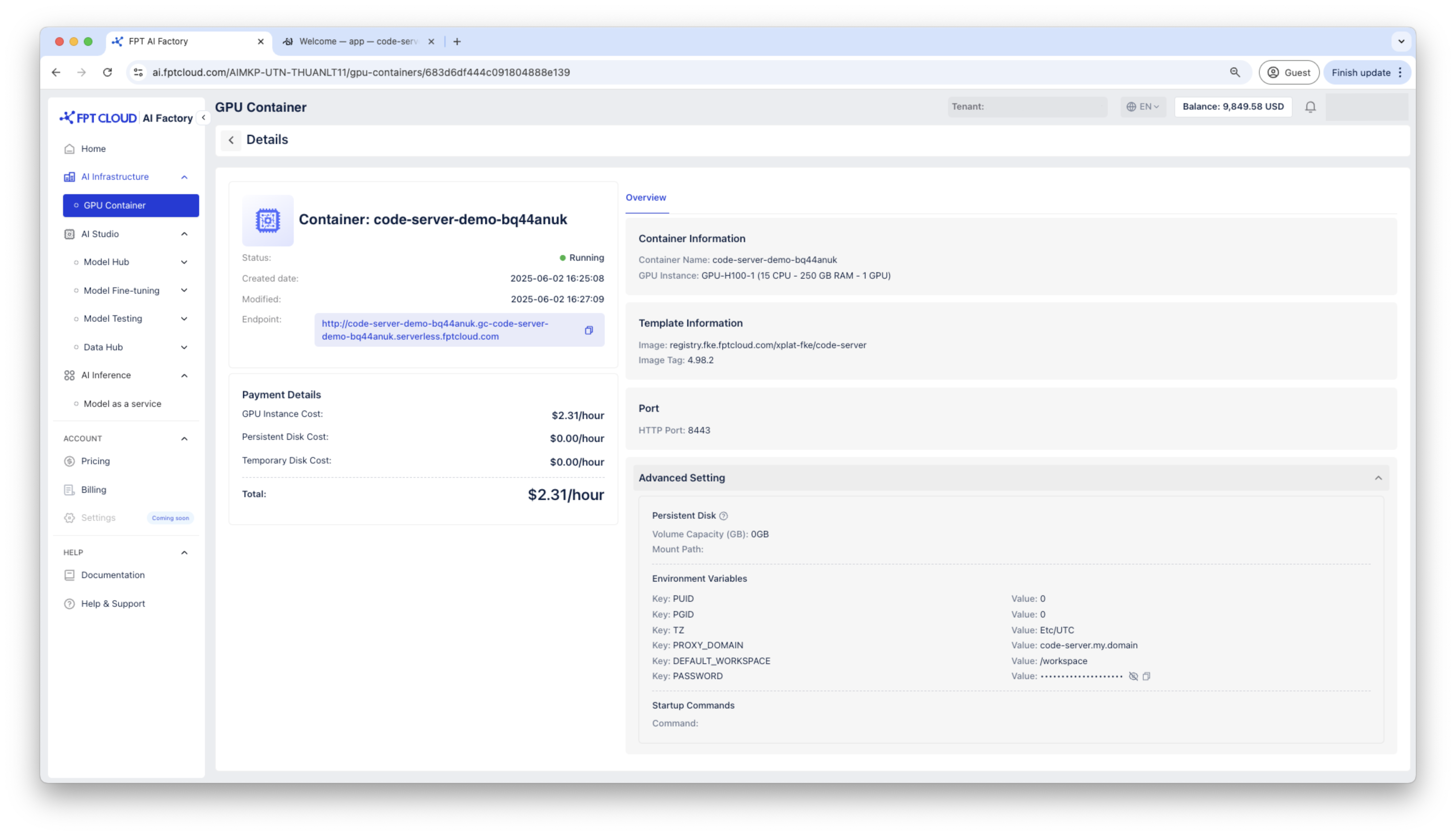
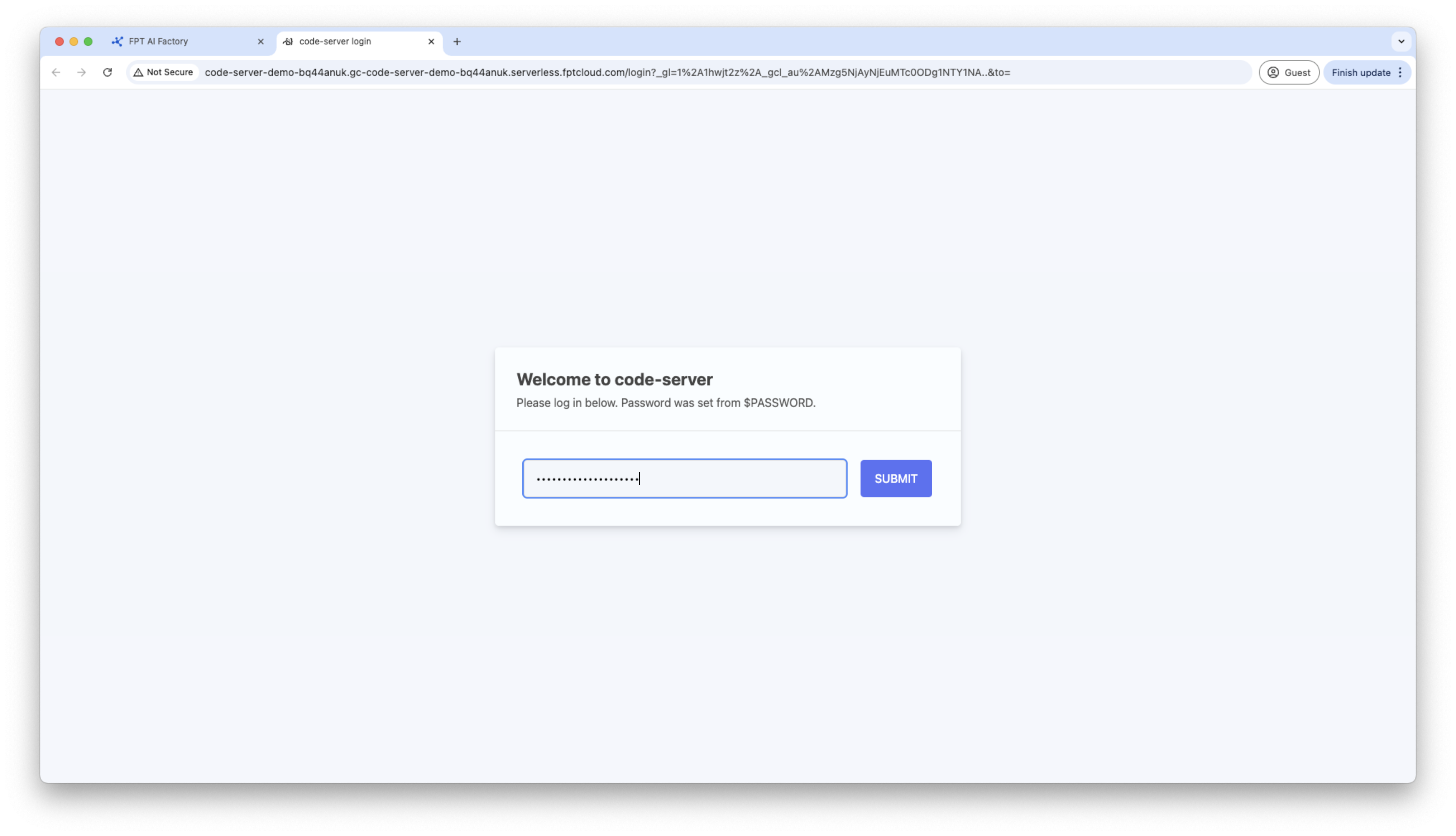
Access to container via HTTP endpoint, the Code Server container will ask for the password, please use the password generated in container details to connect.
Step 2: Install python3, pip
sudo apt update && sudo apt install -y python3 python3-pip python3-venv gitStep 3: Active virtual environment
Using virtual environment to install required python packages and run training code
python3 -m venv ~/venv
source ~/venv/bin/activateStep 4: Install required python packages
pip install --upgrade pip
pip install scikit-learn scipy
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install datasets evaluate accelerate Step 5: Clone Hugging Face transformers from Github
cd /workspace
git clone https://github.com/huggingface/transformers.git
pip install –e . Step 6: Finetune BERT on GLUE MRPC.
Your output will be stored at /tmp/bert-finetuned. In this step, you will fine-tune the pre-trained BERT model on the Microsoft Research Paraphrase Corpus (MRPC) task from the GLUE benchmark. This means the model will learn to classify whether two sentences are paraphrases (have the same meaning) or not.
cd /workspace/transformers/examples/pytorch/text-classification
python3 run_glue.py
--model_name_or_path bert-base-uncased
--task_name mrpc
--do_train
--do_eval
--per_device_train_batch_size 16
--learning_rate 2e-5
--num_train_epochs 3
--output_dir /tmp/bert-finetuned
--overwrite_output_dir 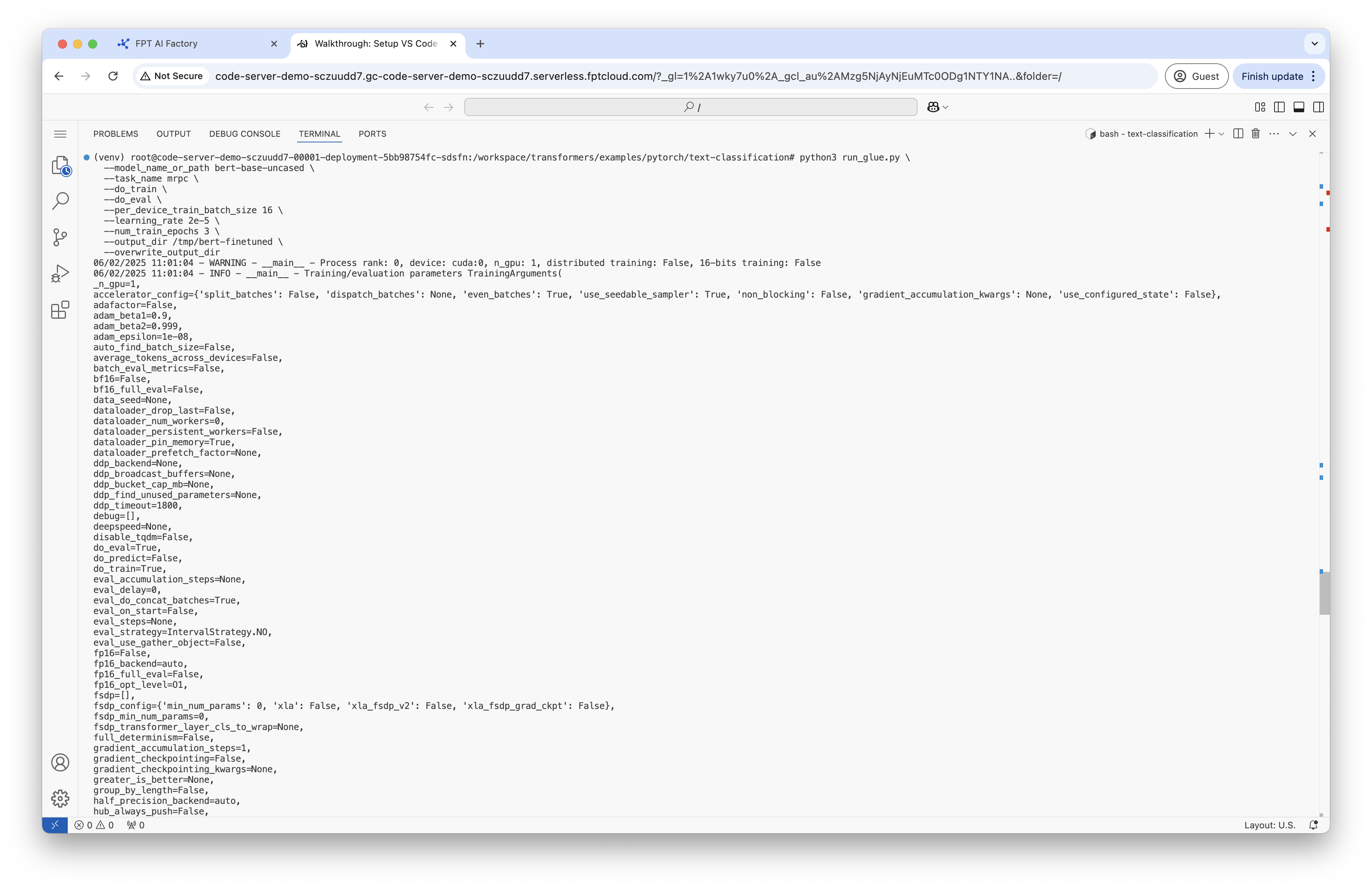
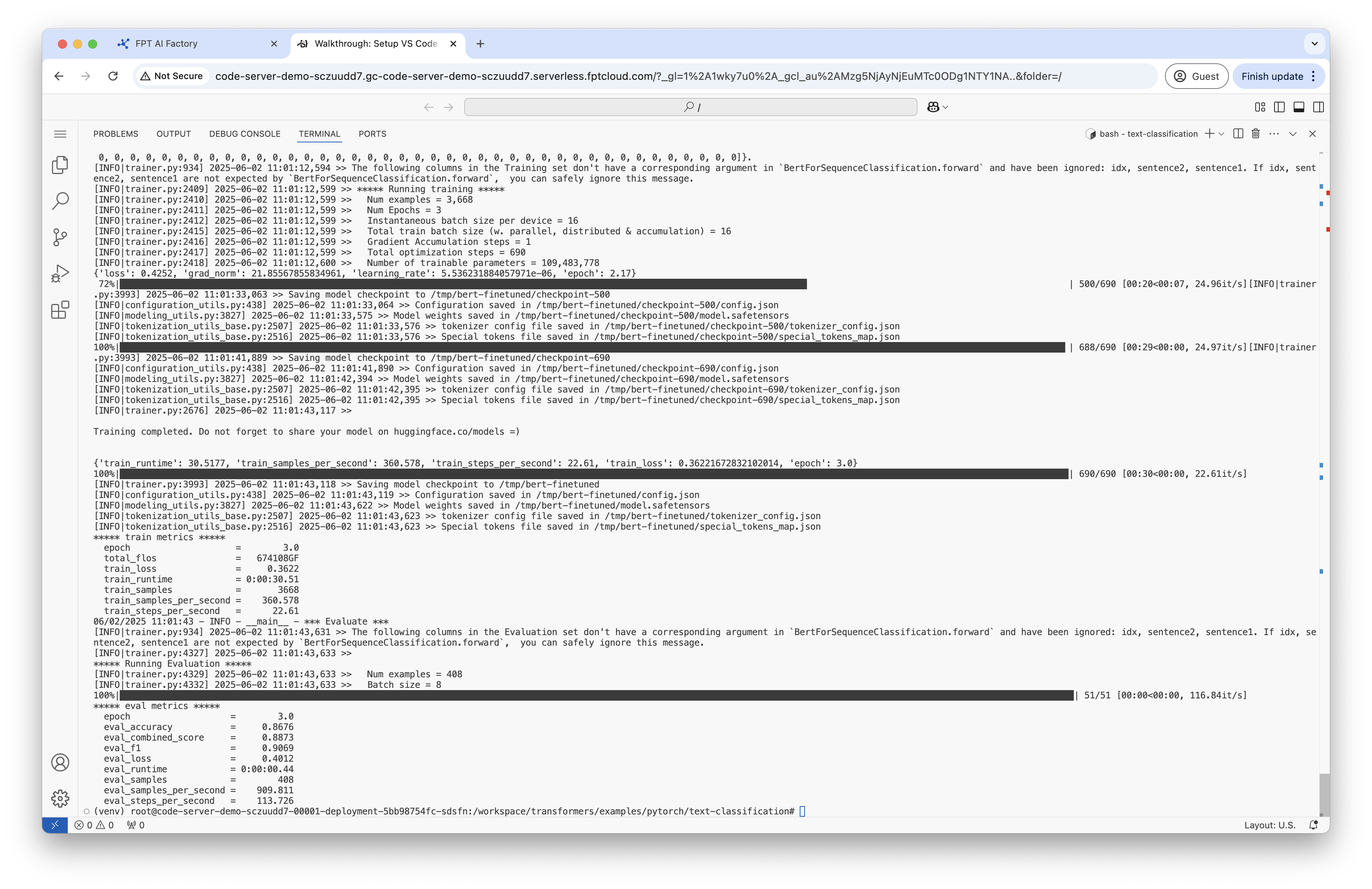
Step 7: Test model
Create a file contains test script called test.py
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# Load fine-tuned model and tokenizer
model_path = "/tmp/bert-finetuned"
model = BertForSequenceClassification.from_pretrained(model_path)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# Move model to GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# Prepare test sentence
sentence1 = "This is a great example!"
sentence2 = "This is a demo for code server GPU Container!"
inputs = tokenizer(sentence1, sentence2, return_tensors="pt").to(device)
# Run inference
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class = torch.argmax(logits, dim=1).item()
# Map class to label (MRPC uses 0/1)
label_map = {0: "not paraphrase", 1: "paraphrase"}
print(f"Sentence: {sentence1}")
print(f"Sentence: {sentence2}")
print(f"Predicted Class: {predicted_class} ({label_map[predicted_class]})") Run file test.py to test the finetuned model
python3 test.py