- About Us
-
 Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand. Virtual server integration for 3D Rendering, AI or ML
Virtual server integration for 3D Rendering, AI or ML Enhance application capacity and availability.
Enhance application capacity and availability. Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology! FPT Web Application Firewall provides powerful protection for web applications
FPT Web Application Firewall provides powerful protection for web applications Advanced virtual server with rapid scalability
Advanced virtual server with rapid scalability Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
 Diverse throughput and capacity to meet various business workloads.
Diverse throughput and capacity to meet various business workloads.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
FPT Web Application Firewall provides powerful protection for web applications
Intelligent and Comprehensive Virtual Web Application Firewall - Security Collaboration between FPT Cloud and Penta Security.
The Next generation firewall security service
Easily store, manage, deploy, and secure Container images
Safe, secure, stable, high-performance Kubernetes platform
Provided as a service to deploy, monitor, backup, restore, and scale MongoDB databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale Redis databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale PostgreSQL databases on cloud. System Monitoring Solution anywhere, anytime, anyplatform
System Monitoring Solution anywhere, anytime, anyplatform Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling.
Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling. - Pricing
- Partner
- Event





Introduction
GPT-OSS is the latest open-weight model series of OpenAI, designed for powerful reasoning, agentic tasks, and versatile developer use cases. Required:
-
openai/gpt-oss-20b: for lower latency, and local or specialized use cases
- The smaller model
- Only requires about 16GB of VRAM
-
openai/gpt-oss-120b: recommend for production, general purpose, high reasoning use cases
- Our larger full-sized model
- Best with ≥60GB VRAM
- Can fit on a single H100 or multi-GPU setups
Step 1: Deploy a container with vLLM v0.10.1 template
-
Click Create a new container button
-
In the template selection, choose latest the vLLM template (v0.10.1).
-
For GPU selection, only 1xH100 GPU is required to serve the model
-
Keep all the other settings on their defaults if you want to serve openai/gpt-oss-20b. Change model if you want to serve openai/gpt-oss-120b.
-
Click Create Container to create your container.
Wait for your container to initialize. This process usually takes around 15 minutes to download the gpt-oss-20b model and up to 2 hours for the gpt-oss-120b model. You can monitor the progress in the Container Logs.
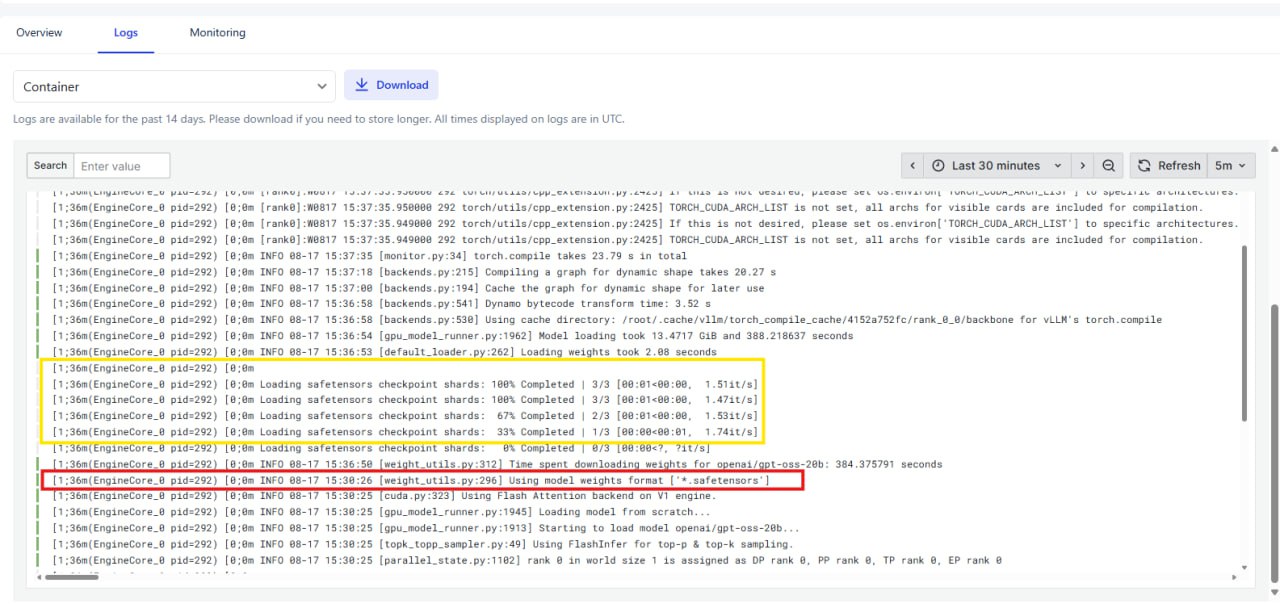
If the logs stop at a line similar to ( Red box in the screenshot)
Using model weights format [*.safetensors]This means the model is still downloading or initializing, and the endpoint is not yet ready to receive requests.
The model is considered fully loaded and ready to serve only when you see all checkpoint shards completed, like this ( Yellow box in the screenshot)
Loading safetensors checkpoint shards: 100% Completed [3/3]This indicates that all model files have been successfully loaded.
Step 2: Sending a Run request
After your container is running and the model is downloaded, you can send a run request to test the setup.
- Check the available model list.
curl -X 'GET' \
'{your endpoint}/v1/models' \ -H 'accept: application/json'.fptcloud.com/v1/models' \
-H 'accept: application/json'- Test the model by asking a few simple questions.
curl -X 'POST' \
'{your endpoint}/v1/chat/completions' \88sdgk-8000.serverless.fptcloud.com/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"content": "Tell me what is GPT-OSS?",
"role": "user",
"name": "admin"
}
],
"model": " openai/gpt-oss-120b"
}'
You can track the performance, availability, and resource usage of containerized services, helping detect issues and optimize operations by using the Monitoring feature.