- About Us
-
 Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand. Virtual server integration for 3D Rendering, AI or ML
Virtual server integration for 3D Rendering, AI or ML Enhance application capacity and availability.
Enhance application capacity and availability. Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology! FPT Web Application Firewall provides powerful protection for web applications
FPT Web Application Firewall provides powerful protection for web applications Advanced virtual server with rapid scalability
Advanced virtual server with rapid scalability Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
 Diverse throughput and capacity to meet various business workloads.
Diverse throughput and capacity to meet various business workloads.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
FPT Web Application Firewall provides powerful protection for web applications
Intelligent and Comprehensive Virtual Web Application Firewall - Security Collaboration between FPT Cloud and Penta Security.
The Next generation firewall security service
Easily store, manage, deploy, and secure Container images
Safe, secure, stable, high-performance Kubernetes platform
Provided as a service to deploy, monitor, backup, restore, and scale MongoDB databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale Redis databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale PostgreSQL databases on cloud. System Monitoring Solution anywhere, anytime, anyplatform
System Monitoring Solution anywhere, anytime, anyplatform Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling.
Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling. - Pricing
- Partner
- Event





You can connect to your GPU Container using a few different methods, depending on your specific needs, preferences, and the template used to create the container.
HTTP Services
Connecting to a container using HTTP is convenient, quick, and secure via HTTPS. To connect using the HTTP Service:
Step 1: Once the container is running, navigate to Container Details Page.
Step 2: Find the endpoint, then copy to clipbooard or click to open on browser.
Step 3: Follow the guide that matches your template.
| Template | Jupyter, Code Server | Ollama WebUI | Ollama | vLLM |
|---|---|---|---|---|
| Pre-condition | None | None | None | Hugging Face Token (*) |
| Next steps |
|
|
Testing your container using Postman (*) | Testing your container using Postman (*) |
(*) Hugging Face Token: Hugging Face Token in Environment Variable section is required when using Ollama template. If you do not have Hugging Face Token yet, please follow this guide.
(*) Testing container by using Postman: Append /v1/models to your endpoint, then provide your API_TOKEN in the Authorization. If you're using the vLLM template, also include HUGGING_FACE_HUB_TOKEN in the request parameters to test your container.
TCP Ports
To access your instance via public endpoint, you will need to add TCP ports to the container configuration. When your container is created, you will receive a public domain and an external public port mapping to access your service. An external public port will be randomly selected from the range 30000-40000.
The format will be DOMAIN:EXTERNAL_PORT -> INTERNAL_PORT. For example:
tcp-endpoint-stg.serverless.fptcloud.com:34771 → :22SSH Terminal
- To get the SSH command for your container, navigate to the Container details page. Copy the command listed under SSH command..
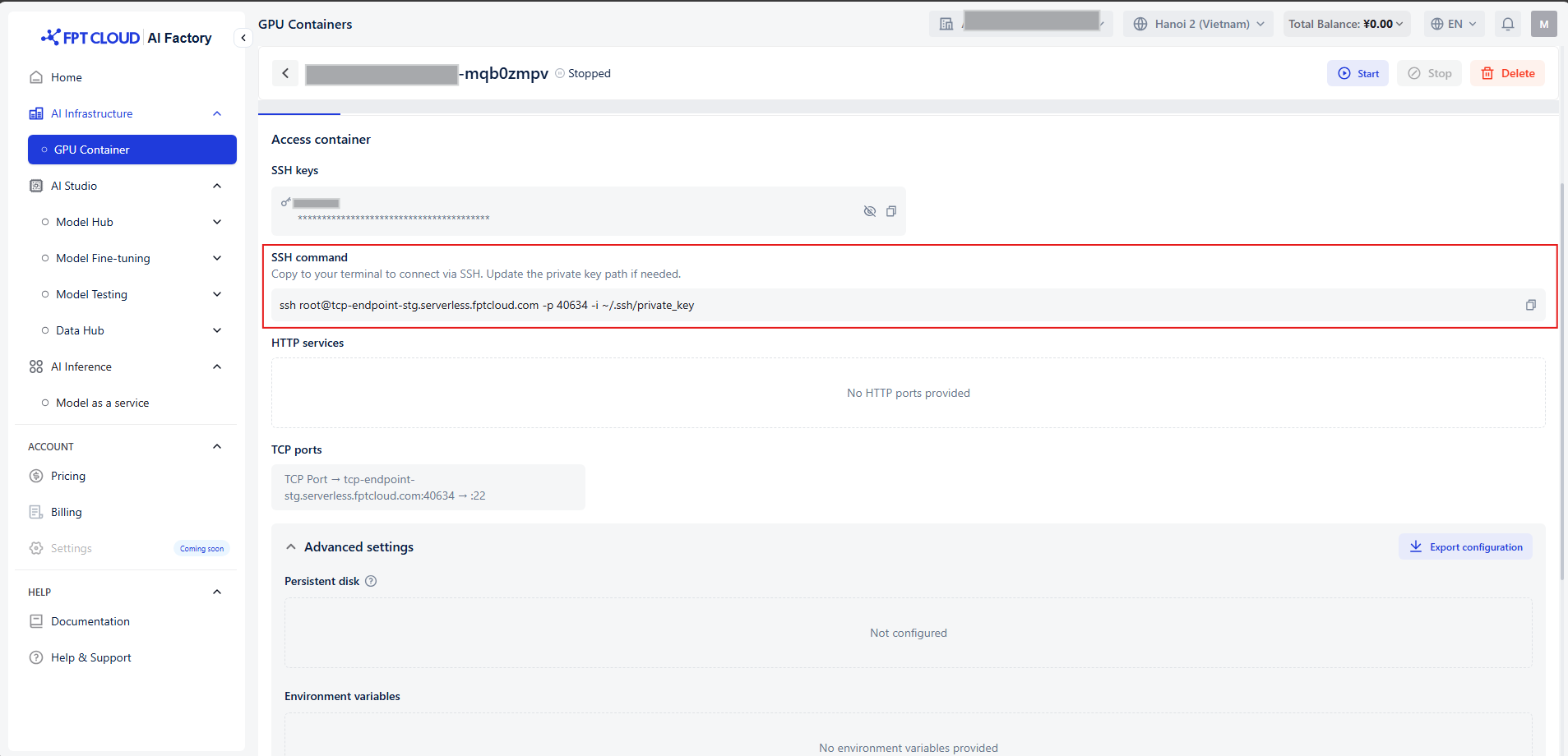
It should look something like this:
ssh root@tcp-endpoint-stg.serverless.fptcloud.com -p 34771 ~/.ssh/id_e25595- Run the copied command in your local terminal to connect to your container.