- About Us
-
 Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand. Virtual server integration for 3D Rendering, AI or ML
Virtual server integration for 3D Rendering, AI or ML Enhance application capacity and availability.
Enhance application capacity and availability. Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology! FPT Web Application Firewall provides powerful protection for web applications
FPT Web Application Firewall provides powerful protection for web applications Advanced virtual server with rapid scalability
Advanced virtual server with rapid scalability Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
 Diverse throughput and capacity to meet various business workloads.
Diverse throughput and capacity to meet various business workloads.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
FPT Web Application Firewall provides powerful protection for web applications
Intelligent and Comprehensive Virtual Web Application Firewall - Security Collaboration between FPT Cloud and Penta Security.
The Next generation firewall security service
Easily store, manage, deploy, and secure Container images
Safe, secure, stable, high-performance Kubernetes platform
Provided as a service to deploy, monitor, backup, restore, and scale MongoDB databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale Redis databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale PostgreSQL databases on cloud. System Monitoring Solution anywhere, anytime, anyplatform
System Monitoring Solution anywhere, anytime, anyplatform Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling.
Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling. - Pricing
- Partner
- Event




Kubernetes manages and utilizes GPU resources similar to how it manages CPU resources. Depending on the GPU specifications of the Worker Group, you need to configure GPU resources for applications running on Kubernetes accordingly.
Note:
-
You can define GPU limits without defining GPU requests since Kubernetes default uses limits value as requests.
-
You can define both GPU limits and requests but these values must be equal.
-
You can not define GPU requests without defining limits.
You can view the GPU specs on Kubernetes by running this command:
kubectl get node ||worker-node|| -o json | jq ‘.items[].metadata.labels‘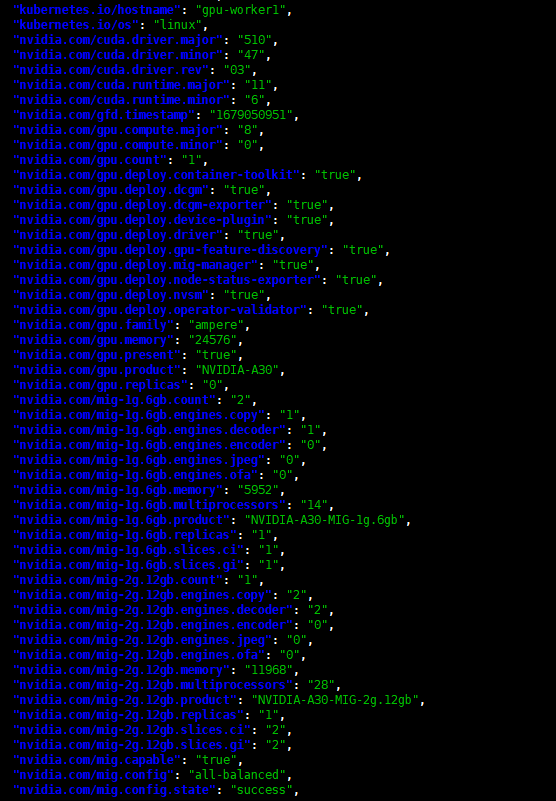
For example, the image above shows a worker using the NVIDIA A30 GPU, with the configuration strategy set to all-balanced, and the status is success.
You can view the GPU Instance specifications by running this command (ssh to the worker node, then execute the command):
nvidia-smi mig -lgi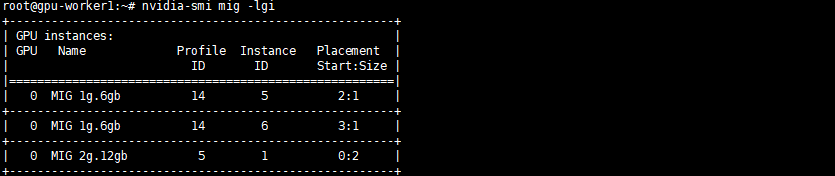
Example of deploying an application with GPU workload:
- With the strategy set to single, the GPU resources are declared as:
nvidia.com/gpu: ||gpu-count||Example:
nvidia.com/gpu: 1Note: With strategy: single, the GPU is divided equally into instances.
Example deployment with strategy: single GPU usage:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-gpu-app
spec:
replicas: 1
selector:
matchLabels:
component: gpu-app
template:
metadata:
labels:
component: gpu-app
spec:
containers:
– name: gpu-container
securityContext:
capabilities:
add:
– SYS_ADMIN
resources:
limits:
nvidia.com/gpu: 1
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: [“/bin/sh”, “-c”]
args:
– while true; do /usr/bin/dcgmproftester11 –no-dcgm-validation -t 1004 -d 300; sleep 30; done- With the strategy set to mixed, the GPU resources are declared as:
nvidia.com/||mig-profile||: ||gpu-count||Example:
nvidia.com/mig-1g.6gb: 2Note: With strategy: mixed, the GPU is divided into 2 instance types, so we need to explicitly define the instance type when declaring the resource.
Example deployment with strategy: mixed GPU usage:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-gpu-app
spec:
replicas: 1
selector:
matchLabels:
component: gpu-app
template:
metadata:
labels:
component: gpu-app
spec:
containers:
– name: gpu-container
securityContext:
capabilities:
add:
– SYS_ADMIN
resources:
limits:
nvidia.com/mig-1g.6gb: 1
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: [“/bin/sh”, “-c”]
args:
– while true; do /usr/bin/dcgmproftester11 –no-dcgm-validation -t 1004 -d 300; sleep 30; done- With the strategy set to none, the GPU resources are declared as:
nvidia.com/gpu: 1Note: With strategy: none, the GPU is fully allocated to the application pod.
Example deployment with strategy: none GPU usage:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-gpu-app
spec:
replicas: 1
selector:
matchLabels:
component: gpu-app
template:
metadata:
labels:
component: gpu-app
spec:
containers:
– name: gpu-container
securityContext:
capabilities:
add:
– SYS_ADMIN
resources:
limits:
nvidia.com/gpu: 1
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: [“/bin/sh”, “-c”]
args:
– while true; do /usr/bin/dcgmproftester11 –no-dcgm-validation -t 1004 -d 300; sleep 30; done