- About Us
-
 Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand. Virtual server integration for 3D Rendering, AI or ML
Virtual server integration for 3D Rendering, AI or ML Enhance application capacity and availability.
Enhance application capacity and availability. Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology! FPT Web Application Firewall provides powerful protection for web applications
FPT Web Application Firewall provides powerful protection for web applications Advanced virtual server with rapid scalability
Advanced virtual server with rapid scalability Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
 Diverse throughput and capacity to meet various business workloads.
Diverse throughput and capacity to meet various business workloads.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
FPT Web Application Firewall provides powerful protection for web applications
Intelligent and Comprehensive Virtual Web Application Firewall - Security Collaboration between FPT Cloud and Penta Security.
The Next generation firewall security service
Easily store, manage, deploy, and secure Container images
Safe, secure, stable, high-performance Kubernetes platform
Provided as a service to deploy, monitor, backup, restore, and scale MongoDB databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale Redis databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale PostgreSQL databases on cloud. System Monitoring Solution anywhere, anytime, anyplatform
System Monitoring Solution anywhere, anytime, anyplatform Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling.
Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling. - Pricing
- Partner
- Event




One of the significant advantages of using GPUs on K8s is the ability to share GPUs. Most workloads do not require the full memory and computing resources of individual GPUs. Therefore, sharing GPUs among multiple processes is essential to increase GPU utilization and reduce infrastructure costs.
GPU sharing currently has three mechanisms:
-
Time Slicing:
-
Multi-instance GPU (MIG)
-
Multi-Process Service (MPS):
Time slicing is a mechanism that allows GPU workloads to be interleaved with each other. It utilizes a GPU time-slicing scheduler to concurrently execute multiple CUDA processes through time-sharing.
When Time slicing is activated, the GPU will share its resources among various processes in a fair-sharing manner by switching between processes at regular intervals. This mechanism introduces overhead as a result of continuous process switching, leading to frame stuttering and increased latency. Additionally, Time slicing lacks a memory isolation mechanism between shared GPU processes or any memory allocation limits, which can result in frequent Out-of-Memory (OOM) errors.
Multi-Instance GPU (MIG) is an architecture available on NVIDIA that enables the subdivision of a GPU into separate GPU partitions. These partitions are isolated from each other in terms of memory bandwidth, cache memory, and processing cores.
With MIG, each instance's graphics processor is independent and has its own dedicated memory system. The on-chip port crossbar, L2 cache, memory controllers, and DRAM bus addresses are uniquely assigned to each instance. This ensures fault tolerance, and the application's workload can be computed with throughput and latency on each individual instance.
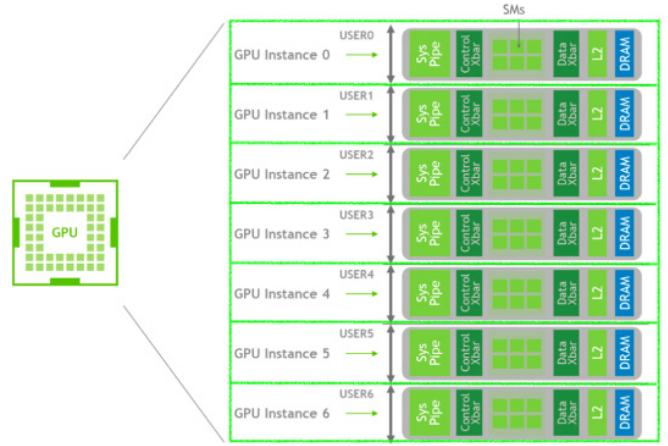
These independent GPU partitions (MIG) are named according to a format indicating the device's memory and compute resources, for example, "1g.gb" corresponds to a GPU slice with 6 GB of memory.
MIG does not allow the creation of GPU partitions with custom sizes and quantities, as each GPU model supports only a specific set of MIG configurations depending on the hardware configuration of the device. This limits resource optimization when utilizing the GPU. Furthermore, MIG devices must adhere to specific arrangement rules, further restricting the flexibility of their usage.
MIG is a GPU sharing method that provides the highest level of isolation between processes. However, this mechanism lacks flexibility and is only compatible with certain GPU architectures (Ampere and Hopper).
In the context of Kubernetes (K8s), NVIDIA has developed the GPU Operator to facilitate MIG usage, although there are still limitations. Users utilize a ConfigMap to define a set of MIG configurations that can be applied to each node by labeling that node.
To efficiently use GPU resources in a K8s cluster, users must continuously modify the ConfigMap to adjust MIG sizes to meet the changing resource requirements of workloads. This process is inconvenient, even though configuring MIG is an improvement over directly accessing nodes and manually creating/deleting MIG devices. Nevertheless, it still requires effort and time. As a result, MIG device configurations are rarely modified over time or are not applied at all, leading to significant inefficiency in GPU utilization and suboptimal GPU usage costs. This issue is addressed by the use of the Automatic GPU Partitioning (MPS) mechanism.
Multi-Process Service (MPS) utilizes the client-server model of the CUDA API, enabling the simultaneous execution of multiple processes on the same GPU.
The server manages GPU access rights concurrently among clients. Clients connect to the server through the client runtime, integrated into the CUDA Driver library and transparent to the application.
Fundamentally, MPS is compatible with all current GPUs, providing the highest flexibility, allowing the creation of GPU partitions with options for both memory capacity and computational capabilities. However, the MPS mechanism does not truly isolate the entire memory space between processes. In most cases, MPS demonstrates a good compromise between MIG and Time-slicing.
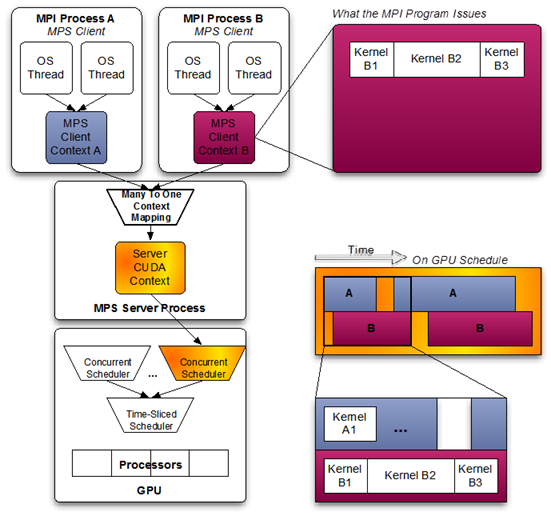
Compared to Time-slicing, MPS eliminates the overhead of context switching by running processes in parallel through spatial sharing, leading to improved computational performance. Furthermore, MPS allocates a separate GPU memory address space for each process, addressing the limitations of Time-slicing.
However, in MPS, processes are not completely isolated from each other. Although MPS allows limiting the memory and computational resources of a client, it does not provide error isolation and memory protection. This means that a process encountering an issue can lead to a GPU reset, affecting all other processes running on the GPU. NVIDIA Kubernetes does not currently support MPS partitioning, so using MPS on Kubernetes requires third-party software.