- About Us
-
 Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand. Virtual server integration for 3D Rendering, AI or ML
Virtual server integration for 3D Rendering, AI or ML Enhance application capacity and availability.
Enhance application capacity and availability. Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology! FPT Web Application Firewall provides powerful protection for web applications
FPT Web Application Firewall provides powerful protection for web applications Advanced virtual server with rapid scalability
Advanced virtual server with rapid scalability Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
Backup and restore data instantly, securely and maintain data integrity.
Advanced virtual server with rapid scalability
Access to an all-inclusive stack for AI development, driven by NVIDIA’s powerful technology!
Enhance application capacity and availability.
Backup and restore data instantly, securely and maintain data integrity.
Recovery, ensuring quick operation for the business after all incidents and disasters.
 Diverse throughput and capacity to meet various business workloads.
Diverse throughput and capacity to meet various business workloads.
Secure, unlimited storage to ensures efficiency as well as high and continuous data access demand.
FPT Web Application Firewall provides powerful protection for web applications
Intelligent and Comprehensive Virtual Web Application Firewall - Security Collaboration between FPT Cloud and Penta Security.
The Next generation firewall security service
Easily store, manage, deploy, and secure Container images
Safe, secure, stable, high-performance Kubernetes platform
Provided as a service to deploy, monitor, backup, restore, and scale MongoDB databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale Redis databases on cloud.
Provided as a service to deploy, monitor, backup, restore, and scale PostgreSQL databases on cloud. System Monitoring Solution anywhere, anytime, anyplatform
System Monitoring Solution anywhere, anytime, anyplatform Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling.
Helps reduce operational costs by up to 40% compared to traditional BI solutions, while improving efficiency through optimized resource usage and infrastructure scaling. - Pricing
- Partner
- Event




FPT Cloud provides Kubernetes with NVIDIA GPU support, featuring the following key functionalities:
-
Flexible GPU configuration with the option to choose GPU types and GPU memory for each Worker Group.
-
Automatic GPU resource management and allocation in Kubernetes with NVIDIA Operator.
-
Visualization and monitoring of GPUs through NVIDIA DCGM (Data Center GPU Manager).
-
Automatic scaling of Containers/Nodes with Autoscaler based on increasing/decreasing GPU resource demands from applications.
-
Support for GPU sharing using the Multi-Instance mechanism, optimizing resource utilization and GPU usage cost.
FPT Cloud utilizes the NVIDIA GPU Operator to provide an automated tool for managing all the necessary software components to use GPUs on Kubernetes (K8s). The GPU Operator allows users to utilize GPU resources in a K8s cluster similar to how they use CPUs.
The software components include:
-
NVIDIA Drivers (CUDA, MIG, ...)
-
NVIDIA Device Plugin
-
NVIDIA Container Toolkit
-
NVIDIA GPU Feature Discovery
-
NVIDIA Data Center GPU Manager (Monitoring)
The K8s Operator automatically configures Multi-Instance GPU (MIG) for workers. To achieve MIG configuration, workers need to be labeled according to profiles supported by Nvidia. MIG configurations are listed in the Configmap default-mig-parted-config on K8s in the 'gpu-operator' namespace.
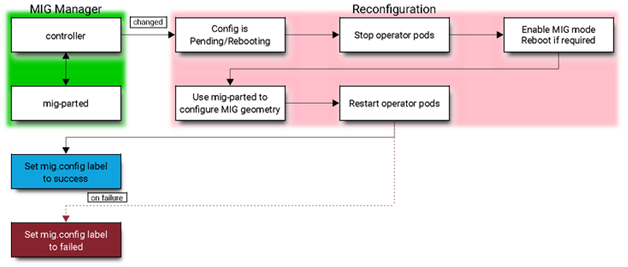
MIG on Kubernetes is designed as a controller. It monitors changes to the label 'nvidia.com/mig.config' on the worker, then applies the MIG configuration requested by the user. When the label changes, MIG first stops all GPU pods, including the device plugin, GFD (GPU Feature Discovery), and DCGM exporter. It then stops all systemd services on GPU workers if the driver is pre-installed. These services are listed in the configmap named 'default-gpu-clients.' Finally, MIG reapplies the MIG configuration and restarts the GPU pods (and potentially GPU systemd services on GPU workers if needed). Enabling MIG mode requires restarting the worker.
FPT Cloud currently supports the Nvidia A30 GPU card and supports the following MIG profiles-labels:
| No. | GPU A30 Profile | Strategy | Number instance | Instance resource |
|---|---|---|---|---|
| 1 | all-1g.6gb | single | 4 | 1g.6gb |
| 2 | all-2g.12gb | single | 2 | 2g.12gb |
| 3 | all-balanced | mixed | 2 | 1g.6gb |
| 4 | all-balanced | mixed | 1 | 2g.12gb |
| 5 | none (no label) | none | 0 | 0 (Entire) |
Example:
With the A30 GPU card, you can configure a single strategy with the label 'all-1g.6gb.' This label signifies that the Operator will divide the A30 GPU on the worker into 4x MIG devices with 1 logical GPU resource (equivalent to ¼ of the physical GPU) and 6GB of GPU RAM. This MIG configuration applies to all labeled cards on the worker.
FPT Cloud uses Nvidia GPU Telemetry integrated with kube-prometheus-stack as a monitoring and supervision tool for GPU usage on K8s. The monitoring tool includes a collector, a time-series database for storing metrics, and visualization through popular open-source applications such as Prometheus and Grafana. Prometheus also incorporates Alertmanager for creating and managing alerts. It is deployed alongside kube-state-metrics and node_exporter to display cluster-level metrics for Kubernetes API objects and node-level metrics, such as GPU usage.
GPU Telemetry architecture model in use:
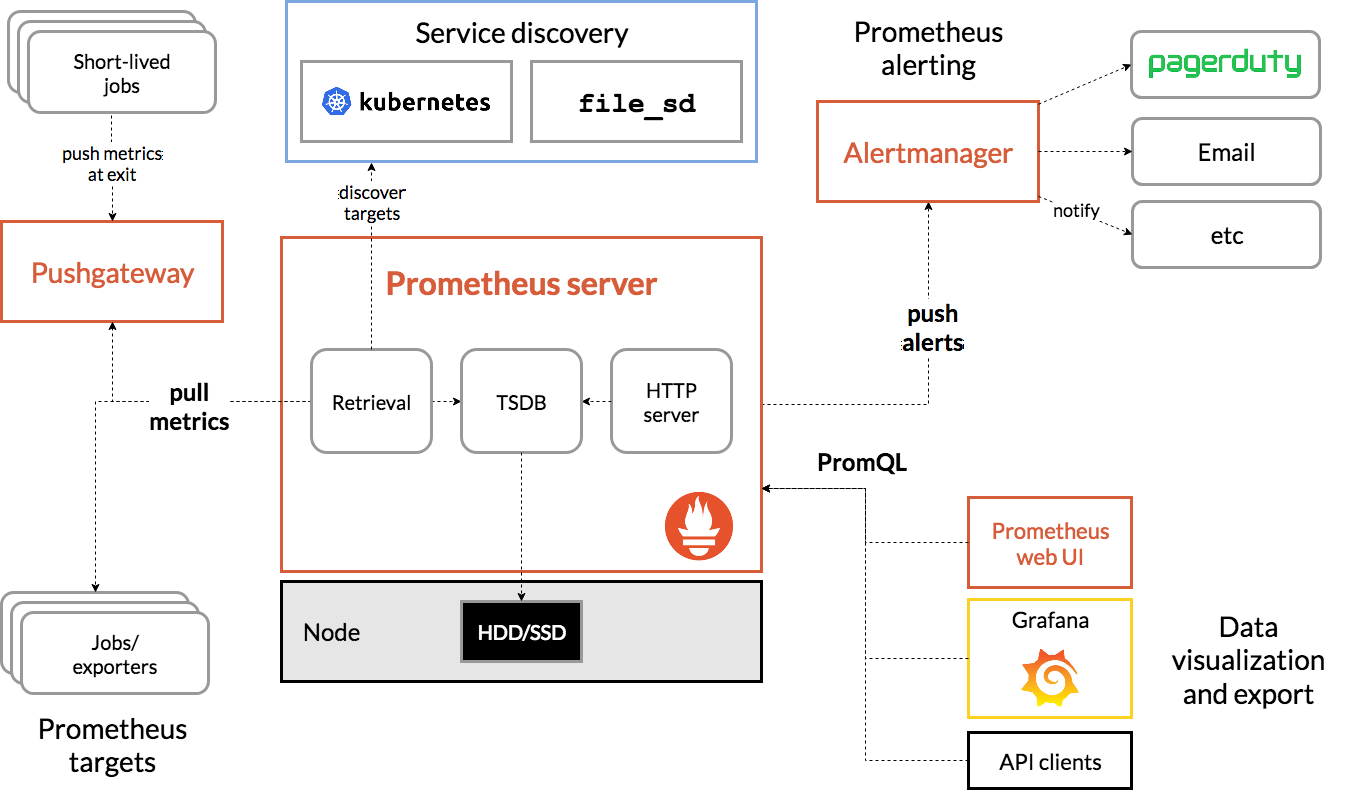
To collect GPU telemetry in Kubernetes, Nvidia recommends using dcgm-exporter. Dcgm-exporter displays GPU metrics for Prometheus and can provide visualizations through Grafana. It is designed to leverage the KubeletPodResources API and display GPU metrics in a format that Prometheus can collect. The tool includes a ServiceMonitor to expose endpoints.
Nvidia DCGM GPU Dashboard:
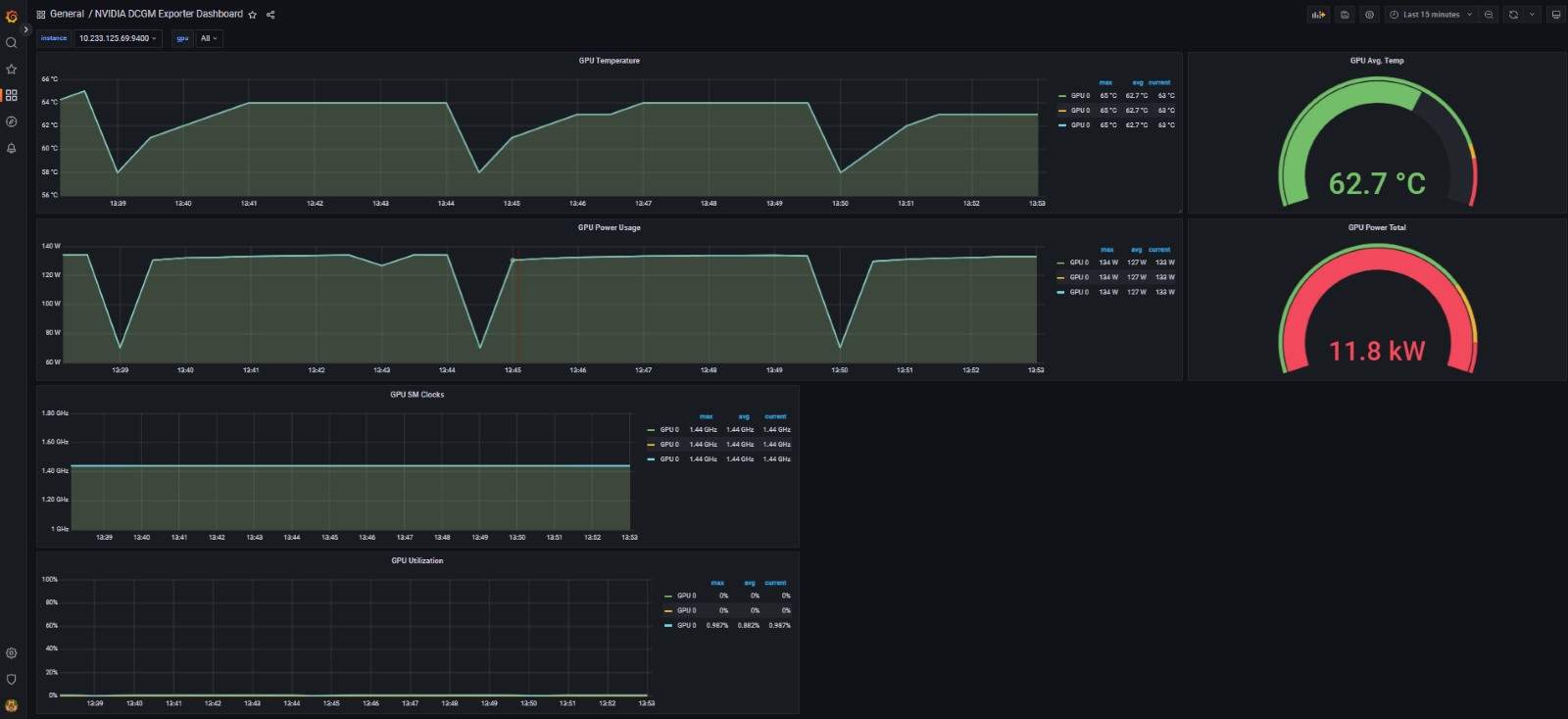
Conclusion: Is using GPU on Kubernetes a good solution for AI workloads? Certainly, as there are increasingly open-source extensions for Kubernetes like KNative, Istio, Kubeflow, and KFSServing that aid in running AI workloads on Kubernetes, accelerating and simplifying the deployment of AI and machine learning on Kubernetes, eliminating complexity, and facilitating deployment and management at scale.
Kubernetes is becoming a central technology in AI deployment today. From data and models to prototypes and finally production, the process has been rationalized and simplified significantly by libraries like PyTorch, TensorFlow, and Keras. These frameworks can also be applied in detail, if necessary, to develop custom components or to integrate and fine-tune existing models using transfer learning. Container technology allows results to be packaged into an image with all the requirements and dependencies of the application, and it can be executed almost anywhere without speed limitations. In the final step, deployment, maintenance, and scalable expansion become extremely straightforward and powerful with Kubernetes.
The combination of GPU on K8s is essential to improve performance and processing speed for AI applications. The GPU services on Kubernetes by FPT Cloud bring efficiency in terms of quality and time savings, especially for financial institutions dealing with large volumes of data.