- Giới thiệu
-
 Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục
Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục Certified DBaaS (cơ sở dữ liệu theo dạng dịch vụ) đầu tiên của MongoDB tại Việt Nam
Certified DBaaS (cơ sở dữ liệu theo dạng dịch vụ) đầu tiên của MongoDB tại Việt Nam Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML
Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác. Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu
Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA! Giải pháp làm việc từ xa hiệu quả và an toàn cho doanh nghiệp
Giải pháp làm việc từ xa hiệu quả và an toàn cho doanh nghiệp
 Dịch vụ máy chủ ảo tiên tiến với khả năng mở rộng nhanh chóng
Dịch vụ máy chủ ảo tiên tiến với khả năng mở rộng nhanh chóng Hiệu năng mạnh mẽ với hạ tầng riêng biệt
Hiệu năng mạnh mẽ với hạ tầng riêng biệt
Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML
Dịch vụ máy chủ ảo tiết kiệm đến 90% chi phí cho doanh nghiệp
Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu
Dịch vụ dự phòng & khôi phục hệ thống nhanh chóng
Lưu trữ khối đa dạng thông lượng và dung lượng cho mọi nhu cầu
Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục Nâng cao năng lực, tính sẵn sàng của ứng dụng
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Dịch vụ tường lửa thông minh cho các ứng dụng web - Giải pháp bảo mật đột phá với sự hợp tác giữa FPT Cloud và Penta Security.
Dịch vụ bảo mật tường lửa thế hệ mới
Lưu trữ, quản lý, và bảo mật các Docker Images
Nền tảng Kubernetes an toàn, bảo mật, ổn định, hiệu năng cao
Nâng cao năng lực, tính sẵn sàng của ứng dụng
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Dịch vụ tường lửa thông minh cho các ứng dụng web - Giải pháp bảo mật đột phá với sự hợp tác giữa FPT Cloud và Penta Security.
Dịch vụ bảo mật tường lửa thế hệ mới
Lưu trữ, quản lý, và bảo mật các Docker Images
Nền tảng Kubernetes an toàn, bảo mật, ổn định, hiệu năng cao Tăng tốc phát triển ứng dụng yêu cầu hiệu năng cao bằng dịch vụ Kubernetes tích hợp với vi xử lý cao cấp GPU
Giám sát và triển khai cơ sở dữ liệu như Kafka,..
Tăng tốc phát triển ứng dụng yêu cầu hiệu năng cao bằng dịch vụ Kubernetes tích hợp với vi xử lý cao cấp GPU
Giám sát và triển khai cơ sở dữ liệu như Kafka,..
Certified DBaaS (cơ sở dữ liệu theo dạng dịch vụ) đầu tiên của MongoDB tại Việt Nam
Giám sát và triển khai cơ sở dữ liệu Redis, Cassandra, ...
Giám sát và triển khai cơ sở dữ liệu xử lý phân tích trực tuyến
Giám sát và triển khai cơ sở dữ liệu MySQL, Postgres, SQLserver, MariaDB,...
Giám sát và triển khai cơ sở dữ liệu truy vấn thông tin
Giám sát và triển khai cơ sở dữ liệu chuỗi thời gian
Giám sát hệ thống và tài nguyên toàn diện trên mọi nền tảng Giải pháp quản lý sự cố thông minh
Giải pháp quản lý sự cố thông minh Dịch vụ cung cấp giải pháp khởi tạo và quản lý FPT ArgoCD được tạo ra từ dự án mã nguồn mở Argo
Nền tảng tự động hoá bảo mật trong quy trình phát triển phần mềm
Dịch vụ cung cấp giải pháp khởi tạo và quản lý FPT ArgoCD được tạo ra từ dự án mã nguồn mở Argo
Nền tảng tự động hoá bảo mật trong quy trình phát triển phần mềm Tăng cường khả năng quản lý tài sản dữ liệu doanh nghiệp
Tăng cường khả năng quản lý tài sản dữ liệu doanh nghiệp Quản lý dữ liệu liền mạch & toàn diện
Truy vấn, quản lý, trực quan hóa dữ liệu hiệu quả
Tăng tốc độ xử lý, đảm bảo tính nhất quán cho ứng dụng
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Nền tảng hội thoại thông minh gắn kết khách hàng trên mọi nền tảng
Xác thực nhanh chóng, dễ dàng, tối ưu chi phí
Nâng tầm trải nghiệm khách hàng
Quản lý dữ liệu liền mạch & toàn diện
Truy vấn, quản lý, trực quan hóa dữ liệu hiệu quả
Tăng tốc độ xử lý, đảm bảo tính nhất quán cho ứng dụng
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Nền tảng hội thoại thông minh gắn kết khách hàng trên mọi nền tảng
Xác thực nhanh chóng, dễ dàng, tối ưu chi phí
Nâng tầm trải nghiệm khách hàng
Trích xuất dữ liệu vượt mọi giới hạn
Chuyển văn bản thành giọng nói tiếng Việt với ngữ điệu tự nhiên.
- Bảng giá
- Sự kiện
Blogs Tech




Hạ tầng vững – xương sống để mở rộng chuỗi F&B và bán lẻ
18:19 16/04/2026
Trong bối cảnh ngành F&B và Bán lẻ Việt Nam đang bước vào giai đoạn tái cấu trúc để mở rộng quy mô, sự ổn định của hệ thống công nghệ không còn là yếu tố bổ trợ mà đã trở thành điều kiện sống còn. Hiện nay, FPT Cloud đang đóng vai trò là hạ tầng vững chắc cho việc vận hành hệ sinh thái quản trị All-in-one của KAS Technology, mang lại một lời giải toàn diện để doanh nghiệp cân bằng giữa tốc độ tăng trưởng và năng lực kiểm soát.
Giải quyết điểm nghẽn vận hành chuỗi bằng công nghệ All-in-one và AI
Theo báo cáo tổng kết của Bộ Công Thương, quy mô thị trường bán lẻ Việt Nam đã đạt mốc 269 tỷ USD (năm 2025). Tuy nhiên, theo khảo sát từ Vietnam Report, chỉ khoảng 65% doanh nghiệp ngành bán lẻ và tiêu dùng ghi nhận đà tăng trưởng thực sự ổn định trong giai đoạn 2025-2026. Áp lực từ chi phí vận hành, biến động giá mặt bằng và nhu cầu tiêu dùng ngày càng cá nhân hóa đã khiến không ít chuỗi cửa hàng rơi vào tình trạng mở rộng nóng nhưng không kiểm soát được hiệu quả kinh doanh.
Nguyên nhân chính nằm ở sự rời rạc của các công cụ quản lý khi số lượng cửa hàng tăng lên. Việc thiếu hụt một hệ thống dữ liệu thống nhất dẫn đến sai sót trong kiểm soát tồn kho, thất thoát dòng tiền và chậm trễ trong việc phản ứng với biến động thị trường.
Trước bài toán đó, KAS Technology đã tái thiết lập quy trình vận hành bằng bộ giải pháp All-in-one, hướng tới xây dựng một hệ sinh thái thống nhất lấy dữ liệu làm trung tâm. Thay vì sử dụng các phần mềm đơn lẻ, giải pháp KAS POSX cho phép doanh nghiệp đồng bộ dữ liệu toàn hệ thống từ online đến offline theo thời gian thực, đảm bảo tính nhất quán trên mọi điểm chạm khách hàng. Sức mạnh này được cộng hưởng bởi KAI, nền tảng Multi-Agent AI giúp tự động hóa các tác vụ phức tạp và phân tích hành vi khách hàng chuyên sâu. Khi kết hợp cùng hệ thống Digital Workplace từ KOM, mạng xã hội nội bộ doanh nghiệp chuyên biệt (Private Social Network) và nền tảng ký số Ksign, các đơn vị sẽ thiết lập được một bộ khung vận hành hoàn chỉnh, sẵn sàng cho việc mở rộng quy mô mà không lo ngại sự đứt gãy quy trình.
Theo lãnh đạo KAS Technology, trong ngành bán lẻ, việc mở rộng nhanh không khó bằng việc duy trì kiểm soát và trải nghiệm khách hàng khi quy mô tăng lên. Doanh nghiệp chỉ thực sự bứt phá khi sở hữu một nền tảng đủ mạnh để hợp nhất dữ liệu và ứng dụng AI vào từng quyết định kinh doanh, giúp chuyển mình từ quản trị cảm tính sang quản trị dựa trên dữ liệu thực chất.
Vai trò bệ đỡ hạ tầng và chiến lược nâng tầm giải pháp từ FPT Cloud
Để các giải pháp All-in-one của KAS vận hành hiệu quả ở quy mô hàng trăm điểm bán, vai trò hỗ trợ hạ tầng từ FPT Cloud trở thành yếu tố then chốt. Việc đưa toàn bộ các giải pháp All-in-one của KAS lên nền tảng FPT Cloud không chỉ đơn thuần là bài toán lưu trữ, mà là sự tối ưu hóa toàn diện về hiệu năng và khả năng tăng tốc xử lý dữ liệu.
FPT Cloud giúp doanh nghiệp ngành bán lẻ xóa bỏ rào cản về chi phí đầu tư hạ tầng vật lý ban đầu, cho phép linh hoạt điều chỉnh tài nguyên theo nhu cầu thực tế của từng điểm bán. Đặc biệt, với các tiêu chuẩn bảo mật quốc tế khắt khe, dữ liệu khách hàng và giao dịch của doanh nghiệp luôn được bảo vệ ở cấp độ cao nhất. Sự ổn định của hạ tầng từ FPT Cloud chính là cam kết quan trọng để các giải pháp như KAI hay KAS POSX có thể xử lý hàng triệu giao dịch mỗi giây mà không xảy ra tình trạng trễ hay gián đoạn hệ thống. Trong ngành bán lẻ, mỗi giây gián đoạn tại điểm bán không chỉ là tổn thất về doanh thu mà còn là rủi ro đối với uy tín thương hiệu trong mắt người tiêu dùng.
Ông Đoàn Đăng Khoa – Phó Tổng giám đốc, FPT Smart Cloud, tập đoàn FPT chia sẻ: “Sứ mệnh của chúng tôi là cung cấp một nền tảng công nghệ vững chắc để những giải pháp công nghệ Việt như KAS có thể vươn tầm. Hệ sinh thái dịch vụ của FPT từ hạ tầng Cloud kết hợp với các giải pháp AI, Big Data đang đồng hành cùng KAS Technology mang đến một giải pháp toàn diện, giúp các nhà quản trị ngành bán lẻ và chuỗi F&B yên tâm tập trung vào chiến lược kinh doanh thay vì phải lo lắng về những rủi ro kỹ thuật hay giới hạn của hạ tầng”.
Chính năng lực hạ tầng này đã giúp KAS có thêm không gian để phát triển thêm nhiều giải pháp đột phá mới, liên tục cập nhật các tính năng AI hiện đại nhất vào sản phẩm mà không bị giới hạn bởi năng lực tính toán hay tính bảo mật.
Giá trị thực chiến cho doanh nghiệp từ hệ sinh thái đồng nhất
Nhờ có bệ đỡ hạ tầng vững chắc từ FPT Cloud, các giải pháp trong hệ sinh thái của KAS mang lại những lợi ích thiết thực và đo lường được cho doanh nghiệp. Công nghệ không chỉ là ứng dụng thông minh mà còn phải dựa trên một hạ tầng tin cậy.
Việc ứng dụng các giải pháp này mang lại ba giá trị cốt lõi cho các chuỗi F&B và Bán lẻ. Thứ nhất là tính tối ưu hóa vận hành, khi mọi quy trình từ bán hàng, kho bãi đến ký số văn bản đều được số hóa hoàn toàn. Thứ hai là khả năng mở rộng linh hoạt, doanh nghiệp có thể dễ dàng kích hoạt hệ thống cho một điểm bán mới chỉ trong thời gian ngắn mà không cần lo lắng về tính tương thích hay hạ tầng máy chủ. Cuối cùng là niềm tin chiến lược thông qua tính bảo mật và an toàn dữ liệu khách hàng theo tiêu chuẩn quốc tế khắt khe từ FPT Cloud, giúp doanh nghiệp xây dựng uy tín vững chắc với người tiêu dùng.
Sự cộng hưởng giữa năng lực hạ tầng của FPT Cloud và sự am hiểu nghiệp vụ của KAS Technology chính là chìa khóa để doanh nghiệp Việt không chỉ đứng vững mà còn vươn xa trong cuộc đua cạnh tranh khốc liệt hiện nay.

FPT AI Factory được vinh danh tại Giải thưởng Make in Vietnam 2025: Thúc đẩy công nghệ Make in Vietnam vươn tầm thế giới
10:00 08/01/2026
Ngày 30/12/2025, FPT AI Factory được vinh danh trong Top 10 Sản phẩm công nghệ số chiến lược xuất sắc tại Giải thưởng Make in Vietnam 2025, do Bộ Khoa học & Công nghệ tổ chức. Thông tin được công bố trong khuôn khổ Diễn đàn Quốc gia Phát triển Doanh nghiệp Công nghệ số Việt Nam 2025 – sự kiện quan trọng cấp quốc gia nhằm tôn vinh đổi mới sáng tạo và năng lực dẫn dắt công nghệ.
Giải thưởng ghi nhận những đóng góp của FPT AI Factory trong việc tăng cường năng lực trí tuệ nhân tạo của Việt Nam, đồng thời góp phần nâng cao vị thế của Việt Nam trên bản đồ công nghệ toàn cầu.
Nền tảng phát triển Trí tuệ Nhân tạo (AI) toàn diện FPT AI Factory là thành quả của quá trình nghiên cứu và phát triển chiến lược, kế thừa và phát huy kinh nghiệm dày dặn cùng các thành tựu đột phá trong lĩnh vực AI mà Tập đoàn FPT đã đầu tư và phát triển liên tục từ năm 2012. Được phát triển bởi FPT Smart Cloud, đơn vị thành viên chiến lược của Tập đoàn FPT về cloud và AI, FPT AI Factory ra đời nhằm giải quyết nhu cầu cấp thiết về hạ tầng AI hiệu năng cao, các công cụ phát triển và dịch vụ AI chuyên sâu, không chỉ tại Việt Nam mà còn vươn ra thị trường khu vực và quốc tế, đồng thời hiện thực hóa mục tiêu tự chủ công nghệ AI quốc gia (Sovereign AI).
Hiện nay, FPT AI Factory cung cấp 43 dịch vụ AI, ứng dụng các siêu chip AI thế hệ mới cùng công nghệ tiên tiến từ NVIDIA, giúp tăng tốc toàn bộ vòng đời phát triển AI, từ huấn luyện, tinh chỉnh mô hình đến việc triển khai và suy luận. Sau một năm kể từ khi chính thức ra mắt, FPT AI Factory đã được tin tưởng bởi 18.853 nhà khoa học AI, lập trình viên ứng dụng và kỹ sư AI trên toàn thế giới, hỗ trợ đa dạng nhu cầu phát triển và ứng dụng AI trong nhiều lĩnh vực.
Với vai trò là nền tảng công nghệ chiến lược quốc gia, FPT AI Factory tích cực thúc đẩy quá trình đổi mới sáng tạo với AI tại Việt Nam. FPT AI Factory đã đồng hành cùng hơn 20 startup AI nhằm nhanh chóng biến các ý tưởng thành ứng dụng AI thực tiễn và đồng tổ chức 8 cuộc thi AI, qua đó nuôi dưỡng nguồn nhân lực AI và thúc đẩy đổi mới sáng tạo dài hạn.
Việc được vinh danh trong Top 10 Sản phẩm công nghệ số chiến lược xuất sắc tại Giải thưởng Make in Vietnam 2025 cho thấy năng lực ngày càng lớn của các doanh nghiệp Việt Nam trong việc phát triển các sản phẩm công nghệ tiên tiến, có khả năng cạnh tranh trên thị trường toàn cầu.
Đối với FPT, sự ghi nhận này phản ánh một khát vọng lớn hơn: đưa các sản phẩm Make in Vietnam và trí tuệ Việt ra thế giới, góp phần khẳng định vị thế của Việt Nam là một trung tâm công nghệ mới nổi trong kỷ nguyên AI.
Trong bối cảnh Việt Nam tiếp tục theo đuổi chiến lược tăng trưởng thông qua chuyển đổi số, FPT AI Factory sẽ tiếp tục thúc đẩy đổi mới sáng tạo, nâng cao năng suất và giúp các tổ chức dẫn dắt trong kỷ nguyên trí tuệ nhân tạo.
Giải thưởng Make in Vietnam 2025 tôn vinh các sản phẩm công nghệ số xuất sắc, mang đậm dấu ấn sáng tạo và trí tuệ Việt Nam. Giải thưởng hướng tới thúc đẩy chuyển đổi số toàn dân, toàn diện và toàn trình; tăng tốc phát triển kinh tế số; tạo bước đột phá về năng suất, chất lượng, hiệu quả và năng lực cạnh tranh quốc gia. Đồng thời, giải thưởng cũng ghi nhận các sản phẩm công nghệ Việt Nam chinh phục thị trường toàn cầu, đóng góp cho sự phát triển của nhân loại và sự thịnh vượng của đất nước. Đáng chú ý, năm 2025 là năm đầu tiên giải thưởng vinh danh các Sản phẩm công nghệ số chiến lược xuất sắc nằm trong Danh mục công nghệ chiến lược và sản phẩm công nghệ chiến lược theo Quyết định số 1131/QĐ-TTg ngày 12/6/2025 của Thủ tướng Chính phủ.

FPT đồng hành cùng cộng đồng AI developer tại Viet Nam – Japan AI Hackathon 2025
11:51 10/12/2025
Là Official Technology Partner, FPT cam kết tài trợ các giải pháp AI Cloud cho các đội thi, hỗ trợ phát triển những ý tưởng AI đột phá. Sự đồng hành này khẳng định nỗ lực của FPT trong việc phát triển cộng đồng AI, thúc đẩy đổi mới sáng tạo tại Nhật Bản.
Trong khuôn khổ cuộc thi, FPT cung cấp hạ tầng điện toán hiệu năng cao cùng bộ công cụ phát triển AI từ FPT AI Factory. Đội ngũ chuyên gia FPT cũng trực tiếp đồng hành thông qua các buổi hướng dẫn và chia sẻ kinh nghiệm triển khai AI thực tiễn, giúp các đội thi hiểu sâu hơn cách xây dựng và triển khai mô hình và giải pháp AI.
Với nguồn lực hỗ trợ này, các đội có thể khai thác tối đa sức mạnh siêu tính toán của NVIDIA H200 GPUs, tăng tốc quá trình huấn luyện và triển khai, rút ngắn thời gian thử nghiệm, từ đó nhanh chóng biến những ý tưởng phức tạp thành giải pháp ứng dụng thiết thực phục vụ nhu cầu doanh nghiệp và thị trường tại Nhật Bản.
Đặc biệt, FPT sẽ trao giải thưởng FPT AI Factory Breakthrough Innovation - Giải Đột Phá Sáng tạo dành cho đội thi mang đến giải pháp AI đột phá, tận dụng tối đa sức mạnh của FPT AI Factory để hiện thực hóa những ý tưởng công nghệ tiên phong.
“Chúng tôi tin rằng các nhà phát triển trẻ tại Nhật Bản và Việt Nam đang nắm giữ chìa khóa mở ra những đột phá mới cho lĩnh vực AI. Thông qua cuộc thi, FPT mong muốn đồng hành cùng các đội thi, giúp các bạn trẻ phát triển năng lực và kỹ năng AI, đồng thời khuyến khích sáng tạo để tạo ra những đổi mới công nghệ thực tiễn.”, ông Đào Thanh Bình, Giám đốc điều hành của FPT Data & AI Integration, Tập đoàn FPT chia sẻ.
Cuộc thi không chỉ là sân chơi để các nhà phát triển trẻ khẳng định tài năng, mà còn là cầu nối hợp tác giữa cộng đồng AI Việt Nam và Nhật Bản. Với sự đồng hành về công nghệ từ FPT, chương trình trở thành bệ phóng hỗ trợ các đội biến ý tưởng thành sản phẩm thực tế, thúc đẩy đổi mới sáng tạo và tạo thêm nhiều cơ hội phát triển cho cộng đồng AI trong khu vực.
Viet Nam – Japan AI Hackathon 2025 – cuộc thi AI dành cho tài năng trẻ Việt Nam và Nhật Bản – thu hút 140 thí sinh với 33 ý tưởng phát triển ứng dụng AI đa dạng và thiết thực trong đời sống, y tế, giáo dục và pháp luật. Trải qua các vòng tuyển chọn khắt khe, 8 đội ấn tượng được lựa chọn vào vòng chung kết, gấp rút hoàn thiện các sản phẩm trong vòng 3 tuần. Top 3 sản phẩm xuất sắc nhất sẽ được vinh danh và trao giải với tổng giá trị lên tới ¥600,000.

Hướng dẫn tích hợp FPT AI Marketplace API key vào Cursor IDE để Sinh code nhanh chóng
17:03 18/11/2025
Trong kỷ nguyên AI, việc tận dụng mô hình ngôn ngữ lớn (LLM) để hỗ trợ lập trình ngày càng phổ biến. Tuy nhiên, thay vì dùng các dịch vụ quốc tế chi phí cao, bạn hoàn toàn có thể khai thác FPT AI Marketplace — nền tảng AI Inference nội địa với chi phí cạnh tranh, độ ổn định cao, và data locality ưu việt.
Bài viết này sẽ hướng dẫn bạn cách tích hợp AI Model API từ FPT AI Marketplace vào Cursor IDE để sử dụng các mô hình sinh code mạnh mẽ.
1. Tạo Tài Khoản FPT AI Marketplace
Truy cập trang https://marketplace.fptcloud.com/ và đăng ký tài khoản.
Ưu đãi: Tài khoản mới sẽ được tặng 1 USD miễn phí để trải nghiệm các dịch vụ AI Inference !
2. Xem Danh Sách Model Khả Dụng
Sau khi đăng nhập, bạn có thể xem các mô hình khả dụng trên FPT Marketplace
[Hình 1: Danh sách model trên FPT AI Marketplace]
Bạn nên chọn những model như Qwen-32B Coder, Llama-8B, hoặc DeepSeek để có kết quả sinh code tối ưu.
3. Tạo API Key
Bạn vui lòng đăng nhập & truy cập https://marketplace.fptcloud.com/en/my-account#my-api-key
Click “Create new API Key” và chọn models, điền tên API Key và ấn “Create”
[Hình 2: Giao diện tạo API Key]
Xác nhận và lấy API Key mới tạo
[Hình 3: Giao diện hoàn thành tạo API Key]
4. Cấu Hình Cursor IDE Với API Key trên FPT AI Marketplace
Các bước thực hiện:
1. Mở Cursor IDE -> Vào Cursor Settings -> Models.
Thêm Model:
Nhấn Add model
Thêm tên model (ví dụ: qwen_coder, deepseek_r1).
3. Điền API Key:
Trong phần OpenAI API Key, dán API Key bạn vừa tạo từ FPT AI Marketplace.
4. Cấu hình URL FPT AI:
Bật Override OpenAI Base URL.
Điền URL: https://mkp-api.fptcloud.com
[Hình 4: Cấu hình API Key và URL trong Cursor]
5. Xác nhận:
Nhấn nút Verify.
Nếu hiện Verified Successfully, bạn đã sẵn sàng sử dụng mô hình!
5. Sử Dụng Model Sinh Code Trong Cursor
Bây giờ, bạn có thể:
Dùng AI Assistant ngay trong IDE để sinh code.
Yêu cầu AI refactor, tối ưu, hoặc giải thích code hiện có.
Chọn model muốn sử dụng.
[Hình 5: Sử dụng model Llama-3.3-70B-Instruction của FPT AI Marketplace để refactor code]
6. Theo Dõi Lượng Token Đã Dùng
Để quản lý chi phí:
Vào My Usage trong FPT AI Marketplace.
Xem số lượng requests, tokens input/output, và tổng lượng usage.
Bạn sẽ biết mình đã dùng bao nhiêu tokens, từ đó kiểm soát được chi phí tốt hơn.
Kết Luận
Chỉ với vài thao tác đơn giản, bạn có thể khai thác trọn vẹn sức mạnh từ FPT AI Marketplace. Từ việc sinh code nguồn nhanh chóng, review thông minh, tối ưu hiệu suất cho đến hỗ trợ debug tự động, tất cả đều được thiết kế để giúp người dùng tăng tốc quy trình làm việc. Đồng thời, các mô hình AI tiên tiến được cung cấp với chi phí hợp lý, đi kèm khả năng theo dõi và quản lý mức sử dụng một cách rõ ràng, minh bạch.

FPT Data Platform: Linh hoạt hơn, bảo mật hơn, vận hành mạnh mẽ hơn
11:32 06/11/2025
Bản nâng cấp mới cho FPT Data Platform – nền tảng dữ liệu toàn diện dành cho doanh nghiệp trên nền tảng đám mây. Với sự nâng cấp lần này, doanh nghiệp sẽ có thêm nhiều công cụ mạnh mẽ hơn để quản lý dữ liệu, phân tích, vận hành và bảo mật. Dưới đây là chi tiết những điểm nổi bật của bản cập nhật.
1. Tính năng chung – Cho toàn bộ nền tảng
Tuỳ chỉnh tên miền riêng
Người dùng giờ đây có thể sử dụng tên miền riêng (custom domain) để truy cập các dịch vụ trên nền tảng, thay vì chỉ sử dụng tên miền mặc định. Điều này giúp tăng nhận diện thương hiệu, tạo sự chuyên nghiệp và dễ dàng tích hợp với hệ thống IT hiện có.
Quản lý Certificate tập trung cho Workspace
Một phân hệ quản lý certificate đã được bổ sung: cho phép thêm, xóa, import và gia hạn (renew) certificate cho các dịch vụ bên trong Workspace. Việc này giúp việc quản lý kết nối bảo mật (HTTPS, TLS) trở nên đơn giản và tập trung hơn – giúp doanh nghiệp yên tâm hơn về mặt bảo mật.
2. Processing Service (v1.2.1) – Nâng cấp cho môi trường xử lý & phân tích dữ liệu
JupyterHub – Kết nối cơ sở dữ liệu ngoài ngay khi khởi tạo
Trong phiên bản mới, khi tạo dịch vụ JupyterHub, người dùng có thể kết nối và sử dụng cơ sở dữ liệu bên ngoài (external DB) ngay từ khâu khởi tạo. Điều này giúp tận dụng hạ tầng dữ liệu sẵn có, tăng tính linh hoạt trong cấu hình môi trường, đảm bảo dữ liệu có thể lưu trữ và chia sẻ ổn định giữa các phiên làm việc.
Mã hoá dữ liệu nhạy cảm trong lúc provision
Hệ thống được bổ sung khả năng cho phép người dùng nhập khoá mã hoá ngay trong luồng provision dịch vụ. Khoá này sẽ được dùng để mã hoá các dữ liệu nhạy cảm trước khi lưu trữ vào cơ sở dữ liệu.→ Tính năng này giúp tăng cường bảo mật, đảm bảo thông tin quan trọng được mã hoá riêng cho từng phiên triển khai, giảm thiểu rủi ro rò rỉ thông tin và đáp ứng yêu cầu tuân thủ bảo mật nội bộ.
3. Orchestration Service – Quản lý và vận hành luồng dữ liệu, công việc tự động
Apache Airflow – Cấu hình Secret Backend khi khởi tạo
Bổ sung tính năng cho phép người dùng nhập secret ngay trong luồng khởi tạo dịch vụ Airflow. Các secret này được sử dụng để cấu hình “Secret Backend” – nơi lưu trữ và quản lý thông tin nhạy cảm như token, password hoặc credential một cách bảo mật.→ Nhờ đó, doanh nghiệp có thể tự quản lý khóa và thông tin nhạy cảm theo từng phiên bản dịch vụ, đồng thời đơn giản hóa quá trình tích hợp với các nguồn dữ liệu hoặc hệ thống bên ngoài.
Governance & Security – Quản trị dữ liệu & bảo mật ở cấp doanh nghiệp
• Ra mắt dịch vụ OpenMetadata (v1.0.0)
OpenMetadata là nền tảng quản lý siêu dữ liệu (metadata) giúp doanh nghiệp chuẩn hoá, khám phá, giám sát và quản trị tài sản dữ liệu một cách tập trung, hiệu quả.
Các tính năng chính:
Central Metadata Catalog: quản lý metadata ở một kho trung tâm.
Data Lineage & Impact Analysis: hiển thị từ upstream → downstream, dễ kiểm soát thay đổi.
Data Quality & Profiler: kiểm tra chất lượng dữ liệu theo rule-based validation.
Glossary & Tagging: định nghĩa thuật ngữ chung, gắn tag phân loại như PII, Confidential.
Collaboration & Search: tìm kiếm, comment, đánh giá, phân quyền ownership.Tác động: giúp doanh nghiệp có cái nhìn toàn diện về dữ liệu, kiểm soát được nguồn gốc, chất lượng và phân quyền sử dụng – hỗ trợ tốt cho tuân thủ quy định và vận hành dữ liệu doanh nghiệp.
5. Lakehouse Analytics – Truy vấn dữ liệu mạnh mẽ & linh hoạt
Trino (v1.4.4) – Auto Scaling worker node
Hệ thống bật hỗ trợ tự động mở rộng (Auto Scale) cho dịch vụ Trino. Số lượng worker node sẽ được điều chỉnh linh hoạt theo tải truy vấn và mức tiêu thụ tài nguyên thực tế.
→ Tính năng giúp tối ưu hiệu năng xử lý truy vấn, giảm chi phí vận hành khi hệ thống ở trạng thái tải thấp, đồng thời đảm bảo hiệu suất cao và độ ổn định khi có nhiều yêu cầu truy cập đồng thời.→ Doanh nghiệp được hưởng lợi lớn khi triển khai phân tích dữ liệu lớn (big data), truy vấn đa nguồn, hoặc môi trường có nhiều người dùng truy cập song song.
Bản cập nhật mới của FPT Data Platform mang đến cho doanh nghiệp:
Bảo mật được nâng cấp, đặc biệt với khả năng mã hoá dữ liệu và quản lý secret tập trung.
Khả năng vận hành và cấu hình linh hoạt hơn: từ kết nối DB ngoài đến tuỳ chỉnh tên miền riêng.
Hiệu năng phân tích dữ liệu được cải thiện thông qua auto scaling và nền tảng metadata quản trị tốt.
Quản trị dữ liệu bài bản hơn – phục vụ nhu cầu doanh nghiệp lớn hoặc tổ chức cần tuân thủ cao.
FPT Cloud khuyến khích doanh nghiệp và đội ngũ trải nghiệm ngay bản cập nhật này để tận dụng tốt nhất các tính năng mới.
Liên hệ với chúng tôi để được tư vấn chi tiết về các giải pháp, dịch vụ của FPT Cloud
Hotline: 1900 638 399
Email: support@fptcloud.com
Support: m.me/fptsmartcloud

FPT đón tiếp đoàn lãnh đạo DAIWA Institute & Research, thúc đẩy cơ hội hợp tác
10:34 22/10/2025
Tuần vừa qua, FPT vinh dự đón tiếp đoàn lãnh đạo cấp cao của DAIWA Institute & Research (Nhật Bản) đến tham quan và làm việc tại FPT Tower, Hà Nội. Buổi gặp gỡ góp phần thắt chặt mối quan hệ hợp tác bền vững, đồng thời mở ra nhiều hướng hợp tác mới trong lĩnh vực trí tuệ nhân tạo (AI), hạ tầng tính toán hiệu năng cao (HPC) và chuyển đổi số toàn diện.
Củng cố mối quan hệ hợp tác bền vững dựa trên đổi mới sáng tạo
Tại buổi làm việc, ông Atsushi Mochizuki – Chủ tịch DAIWA Institute & Research, bày tỏ sự quan tâm đặc biệt đến năng lực phát triển AI, hạ tầng GPU tiên tiến và khả năng mở rộng quy mô công nghệ của FPT. Ông đánh giá cao những bước tiến mạnh mẽ của Tập đoàn trong việc triển khai các giải pháp AI ở cấp độ doanh nghiệp và khả năng vận hành hệ thống phức tạp cho các khách hàng toàn cầu.
Các cuộc thảo luận tập trung vào việc khai thác sức mạnh của FPT AI Factory và nền tảng hạ tầng đám mây AI nhằm cùng nghiên cứu và phát triển các giải pháp đổi mới cho lĩnh vực tài chính, phân tích dữ liệu và AI doanh nghiệp tại Nhật Bản cũng như khu vực châu Á – Thái Bình Dương.
Ảnh: Đoàn lãnh đạo DAIWA Institute of Research và FPT trong buổi làm việc tại trụ sở FPT
“Chúng tôi thực sự ấn tượng với hệ sinh thái AI toàn diện của FPT và năng lực mở rộng đổi mới thông qua hạ tầng kỹ thuật mạnh mẽ. Sự cộng hưởng này mở ra nhiều tiềm năng hợp tác xuyên biên giới trong việc ứng dụng AI, nhằm nâng cao hiệu quả hoạt động và chất lượng nghiên cứu,” ông Atsushi Mochizuki chia sẻ.
FPT AI Factory: Nền tảng phát triển AI toàn diện, quy mô toàn cầu
Điểm nhấn trong chuyến thăm là phần giới thiệu chi tiết về FPT AI Factory – bộ giải pháp phát triển AI toàn diện của FPT. Mới đây, FPT AI Factory đã lọt vào bảng xếp hạng TOP500 siêu máy tính mạnh nhất thế giới, ghi dấu bước tiến vượt bậc trong năng lực tính toán và đầu tư chiến lược vào hạ tầng AI.
Trang bị NVIDIA H100/H200 GPU hiện đại, FPT AI Factory cho phép doanh nghiệp huấn luyện, tinh chỉnh và triển khai mô hình AI một cách nhanh chóng, bảo mật và hiệu quả. Thành tích này không chỉ khẳng định năng lực kỹ thuật và tầm vóc công nghệ của FPT, mà còn thể hiện sự sẵn sàng phục vụ nhu cầu triển khai AI ở quy mô toàn cầu.
Đoàn DAIWA đặc biệt quan tâm đến tiềm năng ứng dụng hạ tầng này trong các hoạt động mô hình hoá tài chính, phân tích dự đoán và nghiên cứu AI chuyên sâu – những lĩnh vực gắn liền với thế mạnh của DAIWA Institute & Research.
Mở rộng hợp tác phát triển AI giữa Nhật Bản và Việt Nam
FPT và DAIWA Institute & Research đã có quá trình hợp tác thành công trong nhiều dự án trước đây, dựa trên niềm tin và tầm nhìn chung về đổi mới sáng tạo. Chuyến thăm lần này một lần nữa khẳng định cam kết của hai bên trong việc mở rộng quan hệ hợp tác vượt ra ngoài phạm vi cung cấp dịch vụ công nghệ, hướng đến các sáng kiến R&D chung, ứng dụng AI trong tài chính và các chương trình trao đổi tri thức giữa hai quốc gia.
FPT kỳ vọng mối quan hệ hợp tác này sẽ trở thành cầu nối vững chắc giữa hệ sinh thái AI của Việt Nam và Nhật Bản, kết hợp năng lực kỹ thuật và tính toán của FPT với kinh nghiệm nghiên cứu và chuyên môn tài chính của DAIWA, cùng hướng tới những sáng tạo có tác động thực tiễn, thúc đẩy năng suất và năng lực cạnh tranh số cho doanh nghiệp.
Đồng hành kiến tạo tương lai trí tuệ nhân tạo
Chuyến thăm của lãnh đạo DAIWA Institute & Research không chỉ là dịp gặp gỡ hợp tác, mà còn thể hiện tầm nhìn chung của hai bên trong hành trình kiến tạo tương lai doanh nghiệp thông minh. Trong vai trò đối tác công nghệ tin cậy, FPT cam kết tiếp tục đồng hành cùng các tổ chức toàn cầu trong việc ứng dụng công nghệ AI một cách bền vững, an toàn và hiệu quả, góp phần xây dựng một thế giới kết nối thông minh hơn.
FPT tin tưởng rằng, với nền tảng công nghệ vững chắc cùng chiến lược của DAIWA Institute & Research, hai bên sẽ cùng mở ra những bước tiến đột phá trong lĩnh vực AI, mang lại giá trị thiết thực cho cộng đồng doanh nghiệp và xã hội.

FPT AI Factory: Đồng hành cùng AI startup phát triển AI hiện đại, hiệu quả
16:25 21/10/2025
Trí tuệ nhân tạo (AI) đang trở thành công nghệ then chốt cho quá trình chuyển đổi số, tái định hình nền kinh tế và xã hội toàn cầu. Ngày nay, AI đang góp phần thúc đẩy đổi mới sáng tạo, nâng cao năng suất, và giải quyết các thách thức phức tạp trong nhiều ngành nghề khác nhau. Đối với các quốc gia đang phát triển, AI không chỉ là công nghệ mới mà còn là cơ hội chiến lược để thúc đẩy tăng trưởng, nâng cao năng lực cạnh tranh và xây dựng một nền kinh tế vững mạnh, sẵn sàng cho tương lai.
Tuy nhiên, bên cạnh những tiềm năng to lớn mà AI mang lại, các AI startup thường phải đối mặt với rào cản lớn nhất, đó là việc thiếu khả năng tiếp cận hạ tầng tính toán hiệu năng cao, một yếu tố cốt lõi để biến các ý tưởng thành những giải pháp thực tiễn. Sự bùng nổ của AI đã tạo nên nhu cầu khổng lồ về GPU và tài nguyên tính toán, khiến việc huấn luyện, tinh chỉnh và triển khai mô hình trở nên thách thức hơn bao giờ hết. Đối với những startup muốn phát triển các giải pháp từ mô hình AI tạo sinh (Generative AI) đến phân tích dữ liệu nâng cao, việc sở hữu nền tảng hạ tầng mạnh mẽ là điều kiện quan trọng để xử lý dữ liệu lớn, tối ưu hóa quy trình huấn luyện và rút ngắn thời gian ra mắt sản phẩm.
Trong bối cảnh cạnh tranh AI khốc liệt, tốc độ, khả năng mở rộng trong quá trình triển khai chính là những yếu tố quyết định thành công của doanh nghiệp. Các startup cần biết cách tận dụng nguồn lực của hạ tầng tính toán mạnh mẽ để nắm bắt lợi thế vượt trội và không bị bỏ lại phía sau trong cuộc chiến công nghệ toàn cầu.
Thiếu hụt hạ tầng: Rào cản chính cản trợ AI startup phát triển quy mô
Trong bối cảnh AI phát triển nhanh chóng, tốc độ, hiệu quả và khả năng tạo khác biệt là yếu tố sống còn đối với mỗi startup. Việc biến những ý tưởng sáng tạo thành các giải pháp AI mang lại giá trị thực tế không chỉ đòi hỏi sự táo bạo, mà còn cần đến nền tảng hạ tầng tính toán hiệu năng cao có thể xử lý khối lượng công việc phức tạp. Việc huấn luyện và tinh chỉnh các mô hình AI quy mô lớn, đặc biệt trong lĩnh vực AI tạo sinh, phụ thuộc phần lớn vào GPU mạnh mẽ, hệ thống lưu trữ linh hoạt và kiến trúc có khả năng mở rộng nhanh chóng để thích ứng với nhu cầu ngày càng tăng.
Tuy nhiên, việc tự xây dựng một hạ tầng như vậy thường vượt quá khả năng của phần lớn các startup. Chi phí đầu tư ban đầu cao, yêu cầu bảo trì liên tục và nhu cầu nhân lực kỹ thuật chuyên nghiệp đã tạo áp lực lớn lên ngân sách hạn hẹp của các startup, khiến các doanh nghiệp trẻ khó có thể thử nghiệm mô hình AI ở quy mô lớn. Bên cạnh đó, hạn chế về năng lực tính toán khiến quá trình huấn luyện mô hình bị chậm lại, xử lý dữ liệu bị giới hạn và không thể cải tiến nhanh chóng để đáp ứng kỳ vọng từ khách hàng hay nhà đầu tư.
Trên thực tế, việc tiếp cận đủ nguồn lực tính toán đã trở thành một khoản đầu tư đáng kể, phản ánh qua quy mô tăng trưởng mạnh mẽ của thị trường hạ tầng hiệu năng cao toàn cầu từ 55,2 tỷ USD năm 2024 lên đến 101,48 tỷ USD vào năm 2033. Ví dụ, một startup muốn huấn luyện mô hình AI tạo sinh tầm trung có thể cần cụm từ 8–16 GPU cao cấp, với chi phí điện toán đám mây lên tới hàng chục nghìn USD mỗi tháng. Mức chi phí này buộc nhiều startup phải thu hẹp quy mô thử nghiệm hoặc kéo dài tiến độ phát triển, tạo nên khoảng cách hạ tầng rõ rệt so với các đối thủ được đầu tư mạnh hơn.
Không chỉ dừng lại ở bài toán phần cứng, các startup còn đối mặt với thách thức về nguồn nhân lực chất lượng cao. Việc thu hút và giữ chân các kỹ sư AI, chuyên gia khoa học dữ liệu hay chuyên viên vận hành học máy (machine learning) là một cuộc cạnh tranh gay gắt và tốn kém. Ngay cả khi có đội ngũ tài năng, việc phối hợp để vận hành hiệu quả các pipeline AI phức tạp vẫn đòi hỏi quy trình tổ chức bài bản, điều mà nhiều doanh nghiệp trẻ vẫn đang trong quá trình hoàn thiện.
Nhìn chung, các AI startup đang chịu áp lực từ ba vấn đề chính: chi phí hạ tầng cao, khan hiếm nhân tài và yêu cầu rút ngắn thời gian ra mắt sản phẩm. Những yếu tố này trở thành rào cản lớn khiến startup khó cạnh tranh hiệu quả trên quy mô toàn cầu. Cân bằng giữa năng lực tính toán, hiệu quả chi phí và nguồn nhân lực đang là bài toán then chốt mà các doanh nghiệp AI phải giải quyết nếu muốn bứt phá thành công. Nếu không tìm được lời giải, ngay cả những ý tưởng sáng tạo nhất cũng có thể bị chôn vùi trước khi chạm tới tiềm năng thực sự.
FPT AI Factory – Bộ giải pháp phát triển AI toàn diện
Trước làn sóng phát triển mạnh mẽ của AI và nhu cầu cấp bách của các doanh nghiệp trong kỷ nguyên AI, FPT hợp tác cùng NVIDIA ra mắt FPT AI Factory, bộ giải pháp toàn diện giúp tăng tốc phát triển AI một cách hiệu quả.
Không chỉ là bộ công cụ đơn thuần, FPT AI Factory là bộ giải pháp mạnh mẽ, kết hợp hạ tầng GPU tiên tiến, ứng dụng AI sẵn có và môi trường ổn định để huấn luyện, tinh chỉnh và triển khai các mô hình AI hiệu quả. Nền tảng này mang đến tốc độ, khả năng mở rộng và sự linh hoạt, giúp doanh nghiệp xây dựng, tối ưu và vận hành giải pháp AI một cách liền mạch.
Từ việc xây dựng mô hình AI tạo sinh riêng, tinh chỉnh kiến trúc hệ thống đến triển khai dịch vụ dựa trên AI, FPT AI Factory cung cấp sức mạnh tính toán vượt trội và quy trình làm việc tinh gọn, giúp doanh nghiệp nhanh chóng biến ý tưởng thành hiện thực.
Triết lý “Build Your Own AI”
Triết lý cốt lõi của FPT AI Factory là “Build Your Own AI”. Triết lý này giúp trao quyền cho các startup và doanh nghiệp dễ dàng tiếp cận và phát triển mô hình AI dành riêng cho từng nhu cầu kinh doanh. Để thành công trong thời đại trí tuệ nhân tạo đang phát triển như vũ bão, doanh nghiệp cần hội tụ đủ sự kết hợp giữa hạ tầng, công cụ và ứng dụng, giúp doanh nghiệp có thể thử nghiệm linh hoạt, cải tiến nhanh chóng và triển khai dễ dàng.
FPT AI Factory được xây dựng trên sức mạnh của nền tảng hạ tầng NVIDIA H100/H200 GPU mạnh mẽ, kết hợp bộ lưu trữ hiệu năng cao và GPU Containers linh hoạt. Bên cạnh đó, FPT AI Factory cung cấp FPT AI Studio – bộ công cụ toàn diện cho việc thử nghiệm, tinh chỉnh và quản lý dữ liệu mô hình, cùng FPT AI Inference – nền tảng hỗ trợ triển khai linh hoạt trên nhiều môi trường khác nhau. Các mô hình vận hành thực tế có thể tương tác với người dùng thông qua AI Agents và ứng dụng, mang lại giá trị kinh doanh rõ rệt.
Ứng dụng đa dạng của FPT AI Factory
Không chỉ dừng lại ở triết lý, FPT AI Factory đã khẳng định giá trị của mình qua những ứng dụng cụ thể trên nhiều lĩnh vực khác nhau, bao gồm:
Ngân hàng & Tài chính:
Triển khai voicebot sử dụng mô hình ngôn ngữ lớn để tự động hóa chăm sóc khách hàng.
Ứng dụng xử lý hình ảnh phục vụ eKYC: xác thực danh tính, nhận diện khuôn mặt, phát hiện deepfake.
Xây dựng trợ lý tài chính cá nhân, có khả năng phân tích báo cáo và tổng hợp tin tức thị trường.
Y tế:
Áp dụng mô hình AI trong chẩn đoán sớm ung thư vú và phân tích tế bào học.
Xử lý hình ảnh siêu âm nhanh hơn nhờ GPU Container.
Công nghệ sinh học:
Phân tích mã gen để hỗ trợ nghiên cứu sinh học và phát triển thuốc.
Công nghệ thông tin:
Phát triển chatbot cho chăm sóc khách hàng và hỗ trợ nội bộ.
Huấn luyện và tinh chỉnh mô hình AI theo dữ liệu doanh nghiệp.
Xây dựng mô hình AI thị giác quy mô lớn, phục vụ xử lý đa tác vụ và vận hành hệ thống ổn định.
Ứng dụng AI Agent để tối ưu quy trình bán hàng và nâng cao trải nghiệm khách hàng.
Những ví dụ trên chính là minh chứng mạnh mẽ, khẳng định rằng với hạ tầng mạnh mẽ và nền tảng phù hợp, AI có thể trở thành giá trị thực tiễn, mang lại tác động thiết thực trong hoạt động kinh doanh và xã hội.
Tiếp sức cho thế hệ startup AI tiên phong
Trong bối cảnh cạnh tranh AI toàn cầu, khả năng phát triển, huấn luyện và triển khai mô hình hiệu quả là yếu tố quyết định thành công. FPT AI Factory không chỉ mang đến nền tảng công nghệ vững chắc mà còn mở ra con đường để hiện thực hóa ước mơ đổi mới sáng tạo.
Với triết lý “Build Your Own AI” và hàng loạt những ứng dụng thực tiễn trong đa ngành nghề, FPT AI Factory đang giúp startup và doanh nghiệp tăng tốc hành trình AI, biến ý tưởng thành giải pháp thực tiễn nhanh chóng hơn, thông minh hơn và tối ưu chi phí hơn.
Liên hệ với chúng tôi để được tư vấn chi tiết về các giải pháp, dịch vụ của FPT Cloud
Hotline: 1900 638 399
Email: support@fptcloud.com
Support: m.me/fptsmartcloud
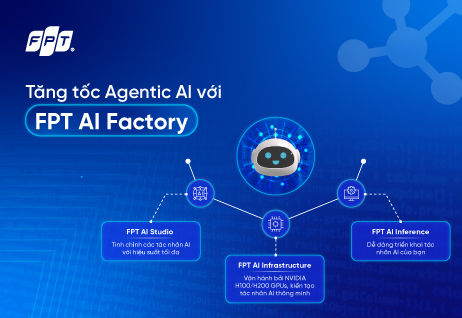
Quy trình phát triển toàn diện của Agentic AI: Cách FPT AI Factory hỗ trợ tăng tốc & phát triển AI Agents
11:04 30/09/2025
Khi trí tuệ nhân tạo (AI) tiếp tục cách mạng hóa các ngành công nghiệp, việc hiểu rõ cách thức vận hành bên trong của các hệ thống AI không chỉ thú vị mà còn trở nên thiết yếu. Một trong những đổi mới nổi bật nhất hiện nay chính là Agentic AI – công nghệ được thiết kế để mô phỏng khả năng ra quyết định, giải quyết vấn đề và thậm chí là sáng tạo giống con người.
Khác với những công cụ thông thường, chỉ phản hồi theo lệnh của người dùng, thì các Agentic AI được xây dựng với tính tự chủ: chúng có thể hiểu được mục tiêu, tự chia nhỏ thành các bước cần làm và từng bước thực hiện cho đến khi đạt được kết quả. Chính khả năng này đã biến Agentic AI trở thành công nghệ hỗ trợ doanh nghiệp tự động xử lý các quy trình phức tạp, nhiều bước với sự can thiệp tối thiểu của con người. Vậy hành trình của một Agentic AI diễn ra như thế nào? Làm thế nào mà các AI Agents có thể xử lý các nhiệm vụ phức tạp một cách liền mạch, thích ứng với thách thức và cải thiện theo thời gian?
Dưới đây là các bước chính trong vòng đời của một tác nhân AI (AI Agents) – mỗi bước đều đóng vai trò quan trọng trong việc tạo ra những hệ thống thông minh, và có khả năng thích ứng nhanh.
1. Perception – Nhận thức
Sự nhận thức của AI Agents là khả năng thu thập và diễn giải thông tin từ môi trường – có thể qua dữ liệu hình ảnh, âm thanh, văn bản hoặc các dạng tín hiệu khác. Đây là lớp nền tảng giúp hệ thống đưa ra quyết định và giải quyết vấn đề. Nếu con người dựa vào giác quan để định hướng trong thế giới thực, thì AI Agents dựa vào khả năng nhận thức để hiểu dữ liệu đầu vào, nhận diện mẫu và phản ứng phù hợp.
Nhận thức không phải là một quá trình thụ động. Nó bao gồm việc chủ động thu thập dữ liệu, xử lý và xây dựng hiểu biết về bối cảnh hiện tại. Các loại dữ liệu mà AI Agents nhận thức có thể thay đổi tùy thuộc vào thiết kế của hệ thống, và có thể bao gồm mọi thứ từ văn bản viết, lời nói, hình ảnh, âm thanh, cho đến các thay đổi trong môi trường. Có thể coi nhận thức chính là “cửa sổ nhìn ra thế giới” của AI Agents, cung cấp thông tin cần thiết để hành động thông minh và linh hoạt.
Các tác nhân AI sử dụng nhiều loại nhận thức khác nhau để hiểu và diễn giải môi trường. Mỗi loại nhận thức cho phép tác nhân tương tác với thế giới theo những cách khác nhau, giúp xử lý các dạng dữ liệu và đưa ra quyết định thông minh. Các loại nhận thức chính bao gồm:
Nhận thức văn bản (Textual Perception): Hiểu và tạo ra văn bản thông qua xử lý ngôn ngữ tự nhiên (NLP). Điều này cho phép các hệ thống AI tương tác với dữ liệu văn bản như bài viết, sách, email và trang web, rất cần thiết cho các ứng dụng như chatbot và trợ lý ảo.
Nhận thức dự đoán (Predictive Perception): AI dự đoán các sự kiện tương lai dựa trên dữ liệu lịch sử, ứng dụng trong các lĩnh vực như tài chính và xe tự lái.
Nhận thức thị giác (Visual Perception): Sử dụng thị giác máy tính (computer vision) để diễn giải hình ảnh và video – ứng dụng trong nhận diện khuôn mặt, phát hiện vật thể.
Nhận thức môi trường (Environmental Perception): AI thu thập thông tin thông qua các cảm biến như GPS hoặc cảm biến chuyển động để thích nghi với các môi trường thay đổi. Ví dụ, robot sử dụng cảm biến này để phát hiện và tránh các chướng ngại vật khi di chuyển.
Nhận thức thính giác (Auditory Perception): Khả năng xử lý và hiểu âm thanh, đặc biệt là giọng nói, giúp hệ thống như trợ lý giọng nói hoạt động hiệu quả.
2. Reasoning and Decision-making – Lập luận và Ra quyết định
Lý luận là quá trình nhận thức cho phép các tác nhân AI đưa ra quyết định, giải quyết vấn đề và suy luận các kết luận dựa trên thông tin mà chúng thu thập được. Đây là một yếu tố quan trọng giúp tác nhân AI hành động thông minh và thích nghi trong các môi trường thay đổi liên tục. Trong khi giai đoạn “Nhận thức” giúp AI thu thập dữ liệu về thế giới, “Lý luận” sẽ giúp tác nhân diễn giải dữ liệu đó, đưa ra kết luận hợp lý và đưa ra quyết định thông minh. Nói cách khác, nhận thức là việc nhận thấy đèn giao thông chuyển sang màu đỏ; lý luận là nhận ra rằng bạn cần phải dừng xe để tránh nguy hiểm.
Lý luận bao gồm việc sử dụng các quy tắc, phương pháp ước lượng, logic và các mô hình học được để xử lý thông tin từ hệ thống nhận thức. Điều này giúp các tác nhân AI không chỉ hiểu rõ trạng thái hiện tại của môi trường mà còn dự đoán kết quả, xử lý các tình huống không chắc chắn và đề ra chiến lược để đạt được mục tiêu.
Lý luận có thể được chia thành các loại khác nhau, mỗi loại đóng một vai trò đặc biệt trong việc giúp các hệ thống AI hoạt động hiệu quả trong các tình huống khác nhau:
Heuristic Reasoning: Sử dụng “luật ngón tay cái” để đơn giản hóa quyết định, phù hợp với tình huống cần phản hồi nhanh. Ví dụ, khi điều hướng trên bản đồ, AI có thể chọn "đoạn đường tốt nhất" dựa trên kinh nghiệm thay vì tính toán tất cả các tuyến đường có thể có.
ReWoo (Suy luận không cần quan sát): Quá trình cải thiện qua các lần lặp lại, giúp AI điều chỉnh và tối ưu hóa chiến lược của mình dựa trên phản hồi và thay đổi từ môi trường.
ReAct (Lý luận và hành động): Một phương pháp kết hợp lý luận và hành động đồng thời, có lợi trong những môi trường yêu cầu phản hồi ngay lập tức như lái xe tự động hay các trò chơi chiến lược thời gian thực.
Self-reflection (Tự phản ánh): AI Agents đánh giá các quyết định trong quá khứ để học hỏi và cải thiện.
Conditional Logic (Điều kiện logic): Quyết định dựa trên các điều kiện cụ thể, thường được sử dụng trong các hệ thống tự động. Ví dụ, một điều hòa thông minh có thể sử dụng logic điều kiện để điều chỉnh nhiệt độ: "Nếu nhiệt độ phòng dưới 70°F, hãy tăng nhiệt."
3. Action – Hành động
Giai đoạn “Hành động” giúp các AI Agents thực thi các quyết định trong thế giới thực, cho phép nó tương tác với người dùng, các hệ thống kỹ thuật số, hoặc thậm chí là các môi trường vật lý. Sau khi “nhận thức” môi trường và “suy luận” về phương án hành động tốt nhất, tác nhân AI phải “thực thi” các quyết định của mình trong thực tế.
Trong thế giới AI, giai đôạn “hành động” không chỉ giới hạn ở các chuyển động vật lý hay tương tác, mà còn bao gồm các quá trình như thao tác dữ liệu, thực thi quyết định và kích hoạt các hệ thống tự động. Dù là robot di chuyển trong môi trường vật lý, hệ thống phần mềm xử lý dữ liệu, hay một trợ lý ảo AI phản hồi theo lệnh, “Hành động” chính là giai đoạn mà tác nhân AI đưa lý luận và sự hiểu biết của mình thành hiện thực.
4. Learning – Học Hỏi
Giai đoạn “học hỏi” là quá trình giúp các AI Agents cải thiện hiệu suất thông qua việc thu thập kiến thức từ kinh nghiệm, dữ liệu, hoặc phản hồi góp ý. Thay vì chỉ dựa vào các hướng dẫn đã được lập trình sẵn, tác nhân AI có thể thích nghi và phát triển bằng cách học hỏi từ môi trường và kết quả của các hành động mà nó thực hiện. Khả năng học hỏi này là điều giúp các tác nhân AI có thể xử lý những tình huống mới, chưa được thấy trước, đưa ra quyết định tốt hơn và tối ưu hóa chiến lược trong các tình huống động, thực tế.
Đây là giai đoạn quan trọng đối với các tác nhân AI trong việc tự tạo ra hệ thống thông minh có khả năng tự cải tiến. Giống như con người học hỏi từ kinh nghiệm và áp dụng kiến thức đó vào các thử thách trong tương lai, các AI Agents sử dụng nhiều phương pháp học hỏi khác nhau để nâng cao khả năng ra quyết định và giải quyết vấn đề. Thông qua việc học hỏi liên tục, các tác nhân AI có thể tinh chỉnh hành vi và ngày càng phù hợp hơn với các mục tiêu của mình.
Các phương pháp học hỏi của tác nhân AI rất đa dạng, tùy thuộc vào cách thức tác nhân tương tác với dữ liệu, phản hồi nhận được và loại nhiệm vụ mà nó cần thực hiện. Dưới đây là những phương pháp học hỏi chính mà các tác nhân AI sử dụng:
Học không giám sát: Nhận diện các mô hình và cấu trúc trong dữ liệu mà không cần các ví dụ có gán nhãn. AI có thể nhóm các khách hàng dựa trên hành vi mua sắm mà không cần biết trước các nhãn.
Học có giám sát: Huấn luyện AI trên dữ liệu có gán nhãn để dự đoán kết quả dựa trên các đầu vào đã biết.
Học tăng cường: AI Agents học tập qua việc thử nghiệm và các lỗi sai gặp phải, nhận phản hồi dưới dạng thưởng hoặc phạt.
Học đa tác nhân: Sự hợp tác và cạnh tranh giữa các tác nhân AI để giải quyết vấn đề một cách hiệu quả hơn.
AI Agents không chỉ đại diện cho một sự nâng cấp vượt bậc của các hệ thống hiện tại mà là một sự chuyển mình thực sự hướng tới trí tuệ tự thích ứng và trí tuệ tự động. Bằng cách nhận thức, lý luận, hành động và học hỏi, các tác nhân AI đang dần thành công trong quá trình mô phỏng các khía cạnh cơ bản về nhận thức của con người.
Tuy nhiên, để xây dựng lên những tác nhân AI như vậy không phải là điều đơn giản; các tổ chức cần có một cơ sở hạ tầng mạnh mẽ và linh hoạt. Từ nguồn tài nguyên GPU mạnh mẽ cho đến môi trường huấn luyện mô hình linh hoạt, tất cả đều là những yếu tố tiên quyết biến lý thuyết thành hiện thực.
5. Cách FPT AI Factory tăng tốc quá trình phát triển AI Agents
Để đáp ứng nhu cầu này, FPT đã ra mắt FPT AI Factory, cung cấp một giải pháp toàn diện để hỗ trợ các doanh nghiệp phát triển AI Agents thông qua ba dịch vụ chính: FPT AI Infrastructure, FPT AI Studio và FPT AI Inference.
Xử lý dữ liệu (FPT AI Infrastructure)
Mỗi tác nhân AI thành công đều dựa vào một vòng quay dữ liệu liên tục để thúc đẩy sự cải tiến. Cơ sở hạ tầng NVIDIA H100/H200 GPU của FPT AI Factory hỗ trợ quá trình này bằng cách thu thập dữ liệu đa dạng (cuộc trò chuyện, tương tác người dùng, dữ liệu từ cảm biến), xử lý và gắn nhãn để huấn luyện AI Agents, từ đó triển khai các tác nhân AI thông minh hơn. Những tác nhân này tạo ra dữ liệu mới từ các tương tác của người dùng, truyền dữ liệu trở lại vào hệ thống để cải thiện các phiên bản tiếp theo. Chu trình tự củng cố này giúp các hệ thống AI ngày càng thông minh và phản hồi nhanh nhạy hơn khi các tác nhân được triển khai, tạo ra một vòng lặp cải tiến liên tục.
Phát triển AI Agents (FPT AI Studio)
Sau khi dữ liệu đã được chuẩn bị, các nhà phát triển có thể sử dụng FPT AI Studio để xây dựng và huấn luyện các tác nhân thông minh trong môi trường đám mây hợp tác. Nền tảng này hỗ trợ phát triển nhiều loại tác nhân AI - từ trợ lý hội thoại đến các hệ thống ra quyết định - cung cấp công cụ huấn luyện mô hình, tinh chỉnh hành vi và tối ưu hóa hiệu suất AI Agents để đảm bảo chúng phản hồi chính xác với các tình huống thực tế.
Triển khai và cung cấp AI Agents (FPT AI Inference)
Sau khi giai đoạn phát triển và kiểm tra đã hoàn thành, FPT AI Inference cho phép triển khai tác nhân AI vào các môi trường sản xuất một cách liền mạch. Những tác nhân được triển khai này không chỉ phục vụ người dùng một cách đáng tin cậy mà còn cung cấp các dữ liệu tương tác quan trọng quay trở lại vòng quay dữ liệu, tạo ra một chu trình cải tiến liên tục. Dù bạn đang triển khai một chatbot dịch vụ khách hàng, hệ thống xe tự lái, hay tích hợp AI Agents vào nền tảng thương mại điện tử, mỗi tương tác người dùng sẽ trở thành một phần của vòng quay dữ liệu giúp thế hệ tác nhân AI tiếp theo trở nên thông minh hơn.
Từ ý tưởng cho đến sản phẩm, FPT AI Factory cung cấp toàn bộ cơ sở hạ tầng cốt lõi, biến các ý tưởng về tác nhân AI thành các hệ thống thông minh và tự cải tiến thông qua sức mạnh của vòng quay dữ liệu.