- Giới thiệu
-
 Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục
Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục Certified DBaaS (cơ sở dữ liệu theo dạng dịch vụ) đầu tiên của MongoDB tại Việt Nam
Certified DBaaS (cơ sở dữ liệu theo dạng dịch vụ) đầu tiên của MongoDB tại Việt Nam Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML
Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác. Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu
Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA! Giải pháp làm việc từ xa hiệu quả và an toàn cho doanh nghiệp
Giải pháp làm việc từ xa hiệu quả và an toàn cho doanh nghiệp
 Dịch vụ máy chủ ảo tiên tiến với khả năng mở rộng nhanh chóng
Dịch vụ máy chủ ảo tiên tiến với khả năng mở rộng nhanh chóng Hiệu năng mạnh mẽ với hạ tầng riêng biệt
Hiệu năng mạnh mẽ với hạ tầng riêng biệt
Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML
Dịch vụ máy chủ ảo tiết kiệm đến 90% chi phí cho doanh nghiệp
Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu
Dịch vụ dự phòng & khôi phục hệ thống nhanh chóng
Lưu trữ khối đa dạng thông lượng và dung lượng cho mọi nhu cầu
Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục Nâng cao năng lực, tính sẵn sàng của ứng dụng
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Dịch vụ tường lửa thông minh cho các ứng dụng web - Giải pháp bảo mật đột phá với sự hợp tác giữa FPT Cloud và Penta Security.
Dịch vụ bảo mật tường lửa thế hệ mới
Lưu trữ, quản lý, và bảo mật các Docker Images
Nền tảng Kubernetes an toàn, bảo mật, ổn định, hiệu năng cao
Nâng cao năng lực, tính sẵn sàng của ứng dụng
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Dịch vụ tường lửa thông minh cho các ứng dụng web - Giải pháp bảo mật đột phá với sự hợp tác giữa FPT Cloud và Penta Security.
Dịch vụ bảo mật tường lửa thế hệ mới
Lưu trữ, quản lý, và bảo mật các Docker Images
Nền tảng Kubernetes an toàn, bảo mật, ổn định, hiệu năng cao Tăng tốc phát triển ứng dụng yêu cầu hiệu năng cao bằng dịch vụ Kubernetes tích hợp với vi xử lý cao cấp GPU
Giám sát và triển khai cơ sở dữ liệu như Kafka,..
Tăng tốc phát triển ứng dụng yêu cầu hiệu năng cao bằng dịch vụ Kubernetes tích hợp với vi xử lý cao cấp GPU
Giám sát và triển khai cơ sở dữ liệu như Kafka,..
Certified DBaaS (cơ sở dữ liệu theo dạng dịch vụ) đầu tiên của MongoDB tại Việt Nam
Giám sát và triển khai cơ sở dữ liệu Redis, Cassandra, ...
Giám sát và triển khai cơ sở dữ liệu xử lý phân tích trực tuyến
Giám sát và triển khai cơ sở dữ liệu MySQL, Postgres, SQLserver, MariaDB,...
Giám sát và triển khai cơ sở dữ liệu truy vấn thông tin
Giám sát và triển khai cơ sở dữ liệu chuỗi thời gian
Giám sát hệ thống và tài nguyên toàn diện trên mọi nền tảng Giải pháp quản lý sự cố thông minh
Giải pháp quản lý sự cố thông minh Dịch vụ cung cấp giải pháp khởi tạo và quản lý FPT ArgoCD được tạo ra từ dự án mã nguồn mở Argo
Nền tảng tự động hoá bảo mật trong quy trình phát triển phần mềm
Dịch vụ cung cấp giải pháp khởi tạo và quản lý FPT ArgoCD được tạo ra từ dự án mã nguồn mở Argo
Nền tảng tự động hoá bảo mật trong quy trình phát triển phần mềm Tăng cường khả năng quản lý tài sản dữ liệu doanh nghiệp
Tăng cường khả năng quản lý tài sản dữ liệu doanh nghiệp Quản lý dữ liệu liền mạch & toàn diện
Truy vấn, quản lý, trực quan hóa dữ liệu hiệu quả
Tăng tốc độ xử lý, đảm bảo tính nhất quán cho ứng dụng
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Nền tảng hội thoại thông minh gắn kết khách hàng trên mọi nền tảng
Xác thực nhanh chóng, dễ dàng, tối ưu chi phí
Nâng tầm trải nghiệm khách hàng
Quản lý dữ liệu liền mạch & toàn diện
Truy vấn, quản lý, trực quan hóa dữ liệu hiệu quả
Tăng tốc độ xử lý, đảm bảo tính nhất quán cho ứng dụng
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Nền tảng hội thoại thông minh gắn kết khách hàng trên mọi nền tảng
Xác thực nhanh chóng, dễ dàng, tối ưu chi phí
Nâng tầm trải nghiệm khách hàng
Trích xuất dữ liệu vượt mọi giới hạn
Chuyển văn bản thành giọng nói tiếng Việt với ngữ điệu tự nhiên.
- Bảng giá
- Sự kiện
Blogs Tech
Danh mục
Các chuyên gia viết chia sẻ kiến thức – FPT CLoud



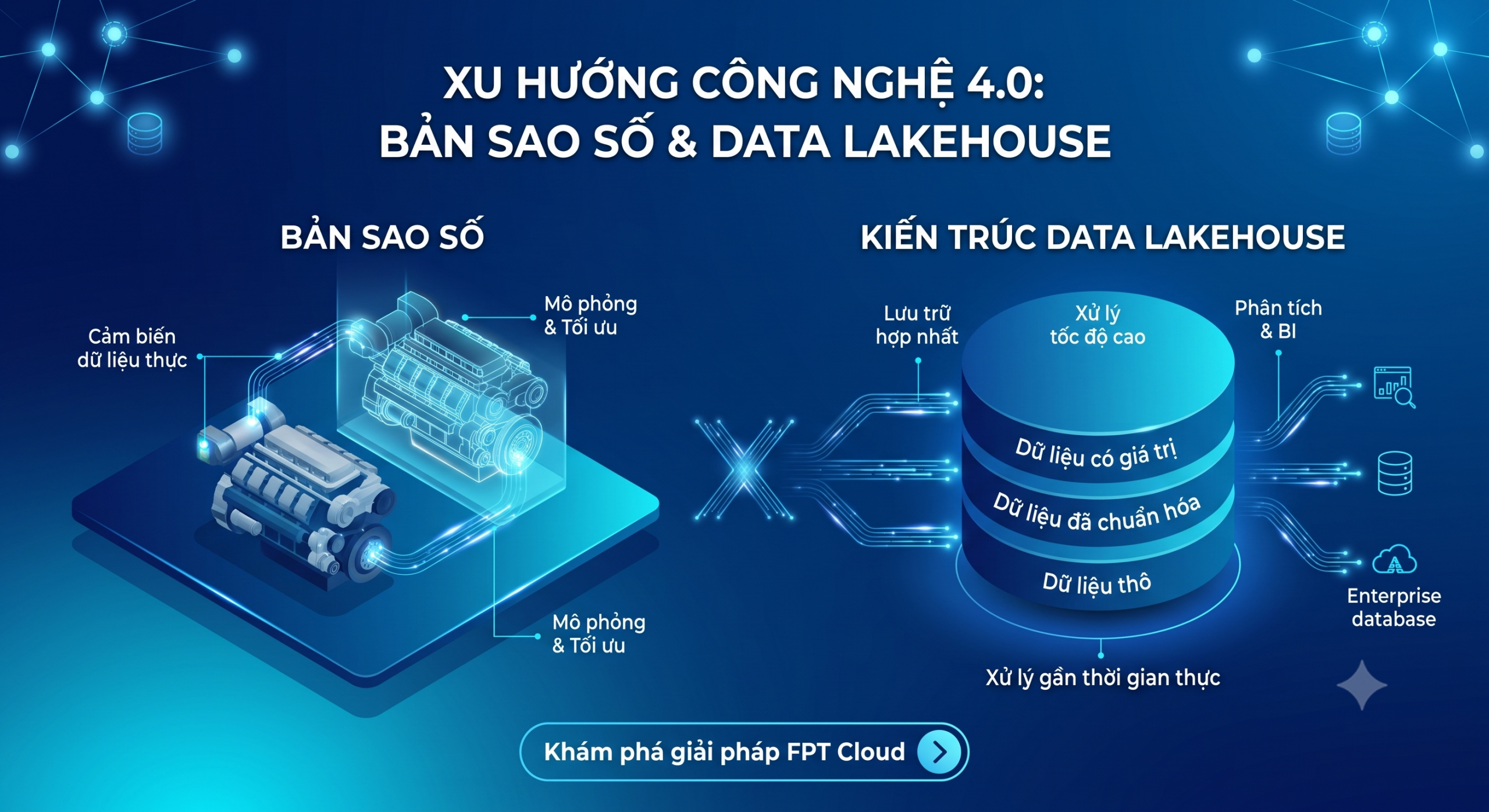
Nền tảng dữ liệu vận hành chuỗi cung ứng: Xây dựng bản sao số Digital Twins với kiến trúc Data Lakehouse
11:25 06/07/2026
Trong bối cảnh thị trường biến động liên tục, việc vận hành và quản lý chuỗi cung ứng được đáng giá là năng lực cạnh tranh cốt lõi của các doanh nghiệp logistic nói riêng và supply chain nói chung. Năng lực này ảnh hưởng trực tiếp đến biên lợi nhuận và trải nghiệm khách hàng của các doanh nghiệp sản xuất, bán lẻ và phân phối thông qua việc điều phối, giữ đúng cam kết cung cấp sản phẩm tới khách hàng hay không.
Theo báo cáo của Gartner, 80% doanh nghiệp quản lý chuỗi cung ứng lựa chọn triển khai giải pháp công nghệ để hỗ trợ quy trình vận hành toàn trình trong tổ chức, đặc biệt là công nghệ liên quan tới phân tích dữ liệu và AI. Tuy nhiên, khi các doanh nghiệp muốn ứng dụng trí tuệ nhân tạo (AI) để tối ưu hóa vận hành, họ thường gặp một bài toán thực tế: các mô hình AI không thể hoạt động hiệu quả nếu không có dữ liệu sạch và đồng bộ trong tổ chức.
Nhằm mang đến lời giải cho bài toán hạ tầng này, vừa qua, FPT Smart Cloud (FCI) đã bắt tay cùng Smartlog đồng tổ chức hội thảo chuyên sâu mang tên “Next Generation Logistics powered by Cloud, Data và AI”. Trong khuôn khổ sự kiện, bài tham luận “Cloud-native Digital Twin for next-gen Logistics” của diễn giả Đặng Thị Giang – Product Owner FPT Data Platform (FPT Smart Cloud) đã thu hút sự chú ý khi đưa ra giải pháp công nghệ và lộ trình triển khai thực tiễn: xây dựng mô hình bản sao số Digital Twins trên nền tảng kiến trúc Lakehouse để chuẩn hóa dữ liệu logistics. Đây được xem là kiến trúc nền tảng giúp doanh nghiệp chuẩn hóa hạ tầng dữ liệu, tối ưu hiệu năng, chi phí quản trị dữ liệu và tạo đà bứt phá tăng trưởng vượt bậc.
Hình ảnh: Diễn giả: Đặng Thị Giang – Product Owner FPT Data Platform, FPT Smart Cloud, Tập đoàn FPT
Dữ liệu bị cô lập, phân mảnh làm tăng chi phí vận hành doanh nghiệp
Để hiểu lý do tại sao mô hình bản sao số (Digital twins) và kiến trúc Data Lakehouse là giải pháp công nghệ tối ưu, doanh nghiệp cần nhìn thẳng vào thực trạng quản trị dữ liệu chuỗi cung ứng hiện nay. Điểm nghẽn lớn nhất của doanh nghiệp chính là tình trạng cô lập dữ liệu (data silos) giữa các hệ thống phần mềm quản lý riêng biệt trong tổ chức.
Các số liệu thực tế cho thấy trung bình một doanh nghiệp phải sử dụng từ 4 đến 8 hệ thống phần mềm độc lập chỉ để quản lý một đơn hàng với thông tin đơn hàng gồm: khách hàng ở hệ thống CRM, thông tin hàng hóa ở WMS, thông tin vận chuyển ở TMS, thông tin tài chính, kế hoạch ở ERP …Việc tra cứu thông tin vận hành hàng ngày như điều phối kho hàng, trạng thái giao hàng phải kiểm tra thủ công qua các hệ thống và phụ thuộc hoàn toàn vào đối tác giao nhận trong việc đảm bảo uy tín giao nhận hàng tới khách hàng. Điều đó trực tiếp ảnh hưởng tới không chi chi phí vận hành mà cả doanh thu, trải nghiệm khách hàng của tổ chức.
Đặc biệt khi tổ chức mở rộng quy mô phát triển, việc mất đồng bộ dữ liệu ngày càng tạo áp lực lên quy trình vận hành và đảm bảo cam kết với khách hàng. Trung bình hàng năm, tỷ lệ lệch tồn kho giữa các hệ thống và thực tế dao động từ 8% đến 15%, buộc doanh nghiệp phải tăng chi phí lưu kho từ 10% đến 25% mỗi năm để duy trì lượng hàng dự trữ an toàn. Ngoài ra, các dữ liệu di chuyển thực địa như định vị GPS, dữ liệu quét mã vạch tại tổng kho, hay cảm biến IoT hoàn toàn bị tách biệt với dòng dữ liệu chứng từ pháp lý như biên bản bàn giao (POD), hóa đơn và phiếu xuất kho, dẫn tới rủi ro sai lệch dữ liệu tài chính - kế toán của doanh nghiệp. Hàng bị giao trễ với biên độ sai lệch thời gian dự kiến (ETA) lên tới 2 đến 4 tiếng, chứng từ bị thất lạc, hay lệch tồn kho... đều mất nhiều ngày đối soát thủ công mới phát hiện ra. Sự chậm trễ này làm giảm chất lượng dịch vụ khách hàng, trực tiếp làm giảm từ 2% đến 5% biên lợi nhuận ròng trên mỗi đơn hàng và đẩy tổng chi phí vận hành (TCO) tăng cao.
Hình ảnh minh họa: xu hướng (digital twins) và kiến trúc Data Lakehouse
Kiến trúc Lakehouse trên nền tảng FPT Data Platform – Hạ tầng quản trị dữ liệu tập trung
Để xử lý bài toán thông tin phân mảnh và cô lập trong tổ chức, đại diện từ FPT Cloud, chị Đặng Thị Giang đã giới thiệu giải pháp quản lý dữ liệu với kiến trúc Data Lakehouse trên nền tảng hạ tầng FPT Cloud. Giải pháp giúp các doanh nghiệp tập trung, chuẩn hóa dữ liệu và là nền tảng để dịch chuyển mô hình quản lý từ phản ứng với sự cố (reactive) sang dự báo và phòng ngừa (predictive).
Giải pháp Data Lakehouse hiện đại giúp tổ chức thu thập từ nhiều nguồn khác nhau (như ERP, CRM, TMS, GPS, IoT, chứng từ ...) với cơ chế thu thập đa dạng theo yêu cầu dữ liệu (theo batch/ realtime/ near realtime/ streaming ...) về lưu trữ và quản trị tập trung ở FPT Cloud.
Tổ chức dễ dàng tích hợp và thu thập toàn bộ dữ liệu trong chuỗi cung ứng, bao gồm dữ liệu có cấu trúc (structured data) từ ERP, dữ liệu streaming từ GPS xe, đến dữ liệu phi cấu trúc (unstructured data) như ảnh chụp chứng từ, thu âm hotline, ... và không cần đội ngũ phát triển, tích hợp từng nguồn dữ liệu riêng biệt.
Sau đó, dữ liệu được đẩy vào quản lý ở Lakehouse với kiến trúc 3 lớp: Bronze – Silver – Gold. Trong đó, lớp Bronze được dùng lưu trữ dữ liệu gốc, phục vụ mục đích kiểm tra, thanh tra theo quy định. Tiếp theo, dòng thông tin sẽ chuyển lên tầng Silver (Dữ liệu chuẩn hóa) để được lọc sạch, loại bỏ thông tin trùng lặp, xử lý các lỗi sai sót và định dạng lại theo một cấu trúc thống nhất, đảm bảo chất lượng dữ liệu trong hệ thống. Cuối cùng, dữ liệu tiếp tục được biến đổi và lưu trữ sẵn tại lớp Gold, tạo thành bộ dữ liệu (dataset) để đảm bảo tốc độ truy xuất dữ liệu tối ưu theo mục đích sử dụng của người dùng cuối, như: các dashboard điều hành, hệ thống báo cáo quản trị (BI Tools) hoặc làm nguyên liệu đầu vào cho các thuật toán học máy (Machine Learning)/ AI.
Điểm mạnh vượt trội của kiến trúc Lakehouse trên nền tảng FPT Data Platform là khả năng xử lý đồng thời cả dữ liệu theo lô (batch data) lẫn dữ liệu thời gian thực (streaming data) trên cùng một hệ thống. Điểm cốt lõi này giúp doanh nghiệp loại bỏ hoàn toàn độ trễ thông tin, từ đó vừa phân tích được xu hướng lịch sử, vừa kiểm soát được các biến động ngoài thực địa ngay lập tức.
Toàn bộ hoạt động thu thập, biến đổi dữ liệu được thực hiện tự động trên hệ thống (Policy as a Code) giúp giảm thiểu khả năng sai sót trong vận hành, tiết kiệm nguồn lực vận hành dữ liệu. Đồng thời công nghệ nén dữ liệu theo cột giúp tối ưu lượng dữ liệu lưu trữ thực tế ở Lakehouse so với lưu trữ dữ liệu gốc ở Data warehouse hay Data Lake, tiết kiệm chi phí lưu trữ không nhỏ đối với bài toán lưu trữ hóa đơn chứng từ lâu dài lên tới 10 năm theo quy định pháp luật.
Quản trị dữ liệu và bảo mật hệ thống toàn diện với dịch vụ FPT Lakehouse
Khi toàn bộ dữ liệu trong chuỗi cung ứng được quản lý tập trung ở Lakehouse, bảo mật dữ liệu chính là bảo vệ hồ sơ cạnh tranh của doanh nghiệp với dữ liệu nhạy cảm như thông tin khách hàng, hợp đồng tới thông tin thương mại như tình trạng hàng hóa, kho bãi, chi phí gốc, biên lợi nhuận hay lộ trình di chuyển của các chuyến hàng giá trị cao.
Nhằm bảo vệ tài sản số cho doanh nghiệp, dịch vụ FPT Lakehouse thuộc hệ sinh thái FPT Data Platform đã thiết lập hệ thống bảo mật toàn diện kết hợp chặt chẽ giữa quản trị, bảo vệ và giám sát.
Đầu tiên, ở khâu kiểm soát và phân quyền sử dụng (Access control), hệ thống cho phép doanh nghiệp chia nhỏ và quản lý quyền truy cập của từng người dùng đến từng dòng, từng cột dữ liệu cụ thể trong hệ thống, cho từng phòng ban, nhân sự riêng biệt (Fine grained access control); ví dụ như nhân viên kế toán chỉ được xem thông tin đơn hàng, hóa đơn còn điều phối viên chỉ được cập nhật trạng thái xe mà không thể can thiệp vào số liệu tài chính. Ngoài ra, hệ thống cung cấp tính năng phân quyền theo nhãn dữ liệu (Tagging) để áp dụng quy định bảo mật đồng loạt theo loại dữ liệu nhạy cảm ở mọi schema dữ liệu.
Tiếp theo, để bảo vệ dữ liệu và ngăn chặn nguy cơ rò rỉ, thông tin luôn được mã hóa theo tiêu chuẩn quốc tế xuyên suốt vòng đời từ lúc thu thập, truyền đi cho đến khi lưu trữ tĩnh (In use, In transit, At rest). Đặc biệt, công nghệ mặt nạ dữ liệu động (Dynamic Masking) sẽ tự động mã hóa (masking) thông tin nhạy cảm theo cơ chế phù hợp như masking toàn bộ/ một phần/ hash/ .... Cuối cùng, tính minh bạch và an toàn được hoàn thiện nhờ hệ thống nhật ký giám sát tự động, nơi mọi hành động truy cập, chỉnh sửa hay xóa dữ liệu của bất kỳ ai đều được ghi lại chính xác, giúp doanh nghiệp dễ dàng truy vết nguồn gốc khi xảy ra sự cố và đáp ứng hoàn hảo các tiêu chuẩn kiểm toán khắt khe của ngành.
Dựa trên nền tảng công nghệ đó, doanh nghiệp không chỉ tập trung dữ liệu mà còn quản trị dữ liệu tốt hơn, đảm bảo dòng chảy dữ liệu thông suốt trong hệ thống và giúp các hệ thống hoạt động liên tục và đồng bộ kết quả tới người dùng cuối cùng, giúp doanh nghiệp khai phá sức mạnh dữ liệu trong công nghệ phân tích hiện đại và triển khai AI/ML trong hoạt động quản lý - kinh doanh của mình.
Giải pháp nền tảng dữ liệu được FPT Cloud đem đến hội thảo cách tiếp cận hiện đại và thực tế cho các nhà điều hành chuỗi cung ứng. Kiến trúc Data Lakehouse không phải là một xu hướng nhất thời, mà là lựa chọn giải pháp công nghệ tối ưu để giải quyết thách thức trong quản lý điều hành chuỗi cung hiện nay và phát triển trong tương lai. FPT vinh dự được đồng hành cùng doanh nghiệp trong suốt quá trình chuyển đổi và mang lại giá trị thực cho doanh nghiệp từ chính công nghệ Cloud-native do chúng tôi phát triển.
Liên hệ với chúng tôi để được tư vấn chi tiết về các giải pháp, dịch vụ của FPT Cloud:
Hotline: 1900 638 399
Email: support@fptcloud.com
Support: m.me/fptsmartcloud

3 yếu tố cốt lõi đánh giá hiệu năng của hạ tầng Cloud
13:54 25/06/2026
Sự phát triển của AI, 5G, NFV và các ứng dụng thời gian thực đang đặt ra những yêu cầu mới cho hạ tầng cloud. Bên cạnh khả năng mở rộng và tính linh hoạt, doanh nghiệp ngày càng quan tâm đến hiệu năng mạng, độ trễ và năng lực xử lý lưu lượng ở quy mô lớn. Điều này tạo ra một thách thức không nhỏ: làm thế nào để duy trì những lợi ích vốn có của cloud trong khi vẫn đáp ứng được các workload vốn trước đây thường chỉ phù hợp với hạ tầng vật lý chuyên dụng.
Đó cũng là bài toán mà kiến trúc High-Performance OpenStack hướng tới giải quyết thông qua việc tối ưu toàn diện từ kernel, CPU, bộ nhớ đến tầng xử lý dữ liệu (dataplane) và phần cứng mạng. Tuy nhiên, giá trị của những cải tiến này không chỉ nằm ở thiết kế kiến trúc mà cần được chứng minh bằng các số liệu thực tế. Trong whitepaper "High-Performance OpenStack: Khi hạ tầng cloud Việt Nam không còn là bottleneck", FPT Smart Cloud đã công bố loạt đo kiểm hiệu năng và kết quả triển khai thực tế, qua đó đánh giá toàn diện các chỉ số quan trọng như thông lượng (throughput), tốc độ xử lý gói tin (packet processing rate) , độ trễ (latency) và dao động độ trễ (jitter), đồng thời cho thấy cách một nền tảng cloud hiện đại có thể đạt hiệu năng tiệm cận hạ tầng vật lý đối với những workload khắt khe nhất hiện nay.
Đo hiệu năng cloud bằng những công cụ nào?
Để đảm bảo kết quả phản ánh đúng năng lực vận hành của hệ thống, nhóm nghiên cứu sử dụng đồng thời nhiều công cụ đo kiểm hiệu năng phổ biến trong lĩnh vực cloud và viễn thông.
Ba mô hình kiểm chứng được sử dụng song song, mỗi mô hình phục vụ một góc nhìn khác nhau. iperf đo thông lượng có tham gia của TCP stack; T-Rex đo năng lực chuyển tiếp thuần ở tầng 2 và tầng 3; Grafana k6 mô phỏng tải thực tế từ nhiều client đồng thời.
Cisco T-Rex được sử dụng để đo khả năng xử lý gói tin (packet) ở Tầng 2 và Tầng 3, đặc biệt phù hợp với các workload viễn thông và NFV. Trong khi đó, iperf giúp đánh giá thông lượng (throughput) theo cách tiếp cận gần với các ứng dụng thực tế. Bên cạnh đó, Grafana k6 được sử dụng để mô phỏng tải ứng dụng và hành vi người dùng trong môi trường production.
Việc kết hợp nhiều phương pháp đo khác nhau giúp đảm bảo kết quả đo kiểm hiệu năng không chỉ phản ánh hiệu năng lý thuyết mà còn cho thấy khả năng vận hành trong các tình huống thực tế.
Thông lượng (throughput) - Khi mạng ảo tiến gần giới hạn phần cứng
Một trong những tiêu chí quan trọng nhất đối với hạ tầng cloud là khả năng khai thác tối đa băng thông vật lý của hệ thống. Đây cũng là chỉ số phản ánh trực tiếp mức độ hiệu quả của tầng mạng ảo hóa, vốn từ lâu được xem là một trong những nguyên nhân gây suy giảm hiệu năng trong môi trường cloud.
Kết quả đo kiểm hiệu năng trên Cisco C8000V cho thấy sự khác biệt đáng kể giữa kiến trúc High-Performance OpenStack và môi trường KVM truyền thống.
So sánh thông lượng (throughput) Tầng 3 trên môi trường 10Gbps. High-Performance Compute Host đạt 6,4 Gbps, cao hơn đáng kể so với mức 2,3 Gbps của mô hình KVM truyền thống.
Trong môi trường 10Gbps, hệ thống đạt thông lượng (throughput) 6,4 Gbps, trong khi mô hình KVM thông thường chỉ đạt khoảng 2,3 Gbps. Kết quả này cho thấy những tối ưu ở tầng tầng xử lý dữ liệu (dataplane) đã giúp khai thác hiệu quả hơn năng lực của phần cứng, đồng thời giảm đáng kể các chi phí xử lý phát sinh trong quá trình truyền tải dữ liệu.
Ở môi trường 25Gbps, nền tảng tiếp tục đạt line-rate ngay cả khi lưu lượng đi qua các lớp overlay networking như VXLAN hoặc Geneve. Điều này cho thấy tầng mạng ảo không còn là nút thắt cổ chai như trong nhiều mô hình cloud truyền thống, nơi hiệu năng thường suy giảm đáng kể khi áp dụng các cơ chế đóng gói lưu lượng phục vụ đa thuê (multi-tenancy).
Đáng chú ý, mức hao hụt băng thông giữa tầng mạng ảo hóa và hạ tầng vật lý được duy trì ở mức dưới 10%. Đây là một chỉ số kỹ thuật quan trọng nhưng không phải lúc nào cũng được công bố rộng rãi trên thị trường cloud. Trên thực tế, đây cũng chính là một trong những yêu cầu được đề cập trong Thông tư 1145 của Chính phủ về tiêu chuẩn chất lượng dịch vụ điện toán đám mây, nhằm đảm bảo hiệu năng của hạ tầng ảo hóa tiệm cận với năng lực thực tế của phần cứng bên dưới.
Những kết quả này cho thấy khi được thiết kế và tối ưu đúng cách, hạ tầng cloud hoàn toàn có thể cung cấp hiệu năng mạng gần với môi trường vật lý, đồng thời vẫn duy trì được khả năng mở rộng và tính linh hoạt vốn là thế mạnh của điện toán đám mây.
Tốc độ gói tin - Yếu tố quyết định thực sự
Nếu thông lượng (throughput) phản ánh khả năng truyền tải dữ liệu của hệ thống, thì tốc độ xử lý gói tin (packet processing rate) mới là chỉ số thể hiện rõ nhất năng lực xử lý của tầng dữ liệu (dataplane). Một hệ thống có thể đạt thông lượng 25 Gbps với các gói tin lớn không đồng nghĩa với việc có thể duy trì hiệu năng tương tự khi xử lý các gói tin nhỏ. Khi kích thước gói tin giảm xuống, tỷ lệ chi phí xử lý header trên lượng dữ liệu thực tế tăng lên đáng kể, khiến áp lực lên CPU, bộ nhớ và tầng xử lý dữ liệu (dataplane) trở nên lớn hơn nhiều.
Khả năng xử lý gói tin (packet) trên mỗi giây của High-Performance OpenStack cao hơn nhiều lần so với mô hình cloud truyền thống.
Kết quả đo kiểm hiệu năng bằng Cisco T-Rex trên Cisco C8000V cho thấy High-Performance Compute Host đạt tới 2,2 triệu gói tin (packet) mỗi giây với gói tin 64 byte và khoảng 1,5 triệu gói tin (packet) mỗi giây với lưu lượng hỗn hợp. Trong khi đó, các môi trường không sử dụng DPDK thường chỉ đạt khoảng 240.000 - 260.000 gói tin (packet) mỗi giây, thấp hơn từ 6 đến 8 lần.
Whitepaper cũng ghi nhận kết quả nổi bật với nền tảng VyOS do FPT Smart Cloud tùy biến. Trên hệ thống thử nghiệm gồm 32 lõi CPU và 32 GB RAM, nền tảng đạt hơn 12 triệu gói tin (packet) mỗi giây mà không ghi nhận hiện tượng mất gói. Đáng chú ý, giới hạn trong bài kiểm thử đến từ hệ thống phát tải thay vì hạ tầng được đo, cho thấy tiềm năng xử lý thực tế còn cao hơn.
Trong môi trường vận hành thực tế, các máy ảo trên High-Performance Compute Host có thể duy trì trung bình 6 - 7 triệu gói tin (packet) mỗi giây, đạt ngưỡng hiệu năng thường thấy ở các hạ tầng viễn thông và carrier-grade. Đây là yếu tố đặc biệt quan trọng đối với các workload như mạng lõi 5G (5G Core), ảo hóa chức năng mạng (NFV), tường lửa (firewall) hay các hệ thống bảo mật, nơi mỗi gói tin đều cần được xử lý ổn định và nhất quán.
Độ trễ và độ ổn định - Điều khách hàng thực sự cảm nhận
Bên cạnh thông lượng (throughput) và PPS, độ trễ là một trong những chỉ số quan trọng nhất đối với các hệ thống yêu cầu phản hồi gần như tức thời. Chỉ cần độ trễ tăng hoặc dao động bất thường, trải nghiệm dịch vụ và hiệu quả vận hành có thể bị ảnh hưởng đáng kể.
High-Performance OpenStack duy trì độ trễ ở mức dưới 1 ms cùng dao động độ trễ (jitter) rất thấp, phù hợp với các workload thời gian thực.
Kết quả đo kiểm hiệu năng trên Check Point R81 cho thấy hệ thống duy trì độ trễ ở mức rất thấp và ổn định, với độ trễ (latency) dao động từ 0,16 - 0,20 ms và dao động độ trễ (jitter) chỉ khoảng 0,015 - 0,017 ms.
Những con số này cho thấy các tối ưu về CPU pinning, NUMA locality, DPDK và hardware offload không chỉ cải thiện hiệu năng xử lý mà còn giúp hệ thống duy trì tính nhất quán trong quá trình truyền tải lưu lượng. Đây là yếu tố đặc biệt quan trọng đối với các workload nhạy cảm với độ trễ như mạng lõi 5G (5G Core), ảo hóa chức năng mạng (NFV) hay các dịch vụ mạng thời gian thực, nơi khả năng dự đoán và ổn định của hạ tầng có ý nghĩa không kém hiệu năng tối đa đạt được.
Bằng chứng từ production - Một câu chuyện thật
Đo kiểm hiệu năng là cơ sở quan trọng để đánh giá hiệu năng của một nền tảng, nhưng giá trị thực sự của kiến trúc hạ tầng chỉ được chứng minh khi triển khai trong môi trường sản xuất. Đây cũng là lý do whitepaper dành riêng một phần để chia sẻ kết quả vận hành thực tế trên hệ thống quy mô lớn.
Kết quả triển khai thực tế sau khi chuyển sang High-Performance Compute Host.
Theo whitepaper, kiến trúc High-Performance Compute Host đã được triển khai trên hệ thống phục vụ hơn 80.000 người dùng cùng hơn 10.000 desktop ảo. Trước khi tối ưu, hệ thống gặp nhiều hạn chế liên quan đến hiệu năng mạng, mức sử dụng CPU và khả năng xử lý lưu lượng.
Sau khi áp dụng kiến trúc mới, thông lượng (throughput) tăng từ 1,9 Gbps lên 3,4 Gbps, trong khi năng lực xử lý gói tin (packet) tăng từ 445.000 PPS lên 611.000 PPS. Đáng chú ý, hệ thống chỉ cần 16 vCPU để đạt hiệu năng tương đương hoặc cao hơn so với cấu hình cũ sử dụng 48 vCPU.
Bên cạnh đó, tỷ lệ mất gói được giảm xuống chỉ còn 0,001%, góp phần cải thiện tính ổn định của dịch vụ và trải nghiệm người dùng cuối. Những con số này cho thấy các tối ưu ở tầng CPU, bộ nhớ, tầng xử lý dữ liệu (dataplane) và phần cứng mạng không chỉ mang lại kết quả trong môi trường thử nghiệm mà còn phát huy hiệu quả khi vận hành ở quy mô lớn.
Hiệu năng cao không đồng nghĩa mất tính năng cloud
Một lo ngại phổ biến khi triển khai các công nghệ như DPDK hay tăng tốc bằng phần cứng là doanh nghiệp có thể phải đánh đổi các tính năng quen thuộc của cloud để đạt hiệu năng cao hơn. Tuy nhiên, kết quả được công bố trong whitepaper cho thấy High-Performance Compute Host vẫn duy trì đầy đủ các tính năng quan trọng như di chuyển máy ảo trực tiếp (live migration), thay đổi cấu hình tài nguyên (resize), nhóm chính sách bảo mật (securitygroup), địa chỉ IP công cộng linh hoạt (floating IP) và biên dịch địa chỉ mạng (NAT) cùng các mô hình kết nối Đông - Tây (East-West Traffic) và Bắc - Nam (North-South Traffic).
Các tính năng cloud cốt lõi vẫn được duy trì trên kiến trúc High-Performance Compute Host.
Theo FPT Smart Cloud, điều này đạt được nhờ cách tiếp cận tối ưu đồng bộ trên toàn bộ kiến trúc, từ CPU, bộ nhớ, phần cứng mạng đến tầng xử lý dữ liệu (dataplane). Nhờ đó, doanh nghiệp có thể đồng thời đạt được hiệu năng cao và khả năng vận hành linh hoạt, thay vì phải đánh đổi một trong hai như nhiều người vẫn nghĩ.
Vị thế dẫn đầu và những gì còn ở phía trước
Mặc dù các kiến trúc dựa trên DPDK và Open vSwitch Userspace đã được nhiều nhà cung cấp quy mô lớn (hyperscale) trên thế giới ứng dụng từ lâu, đây vẫn là hướng tiếp cận còn tương đối mới tại thị trường Việt Nam. Theo whitepaper, thông qua quá trình đo kiểm hiệu năng và kiểm chứng trên các môi trường sản xuất thực tế, FPT Smart Cloud đang xây dựng một trong những nền tảng OpenInfra hiệu năng cao hàng đầu khu vực, sẵn sàng đáp ứng các workload.
Các cụm AI Factory tại Việt Nam và Nhật Bản, cùng những triển khai thực tế cho các workload viễn thông, đã cho thấy khả năng vận hành ổn định của kiến trúc này ở quy mô lớn. Quan trọng hơn, toàn bộ hạ tầng được triển khai theo cùng một bản thiết kế kiến trúc (blueprint) chuẩn hóa, giúp đảm bảo tính nhất quán về độ trễ và hiệu năng trên hàng trăm máy chủ.
Điều mà whitepaper nhấn mạnh là: cloud không còn là nút thắt cổ chai. Với kiến trúc phù hợp, hạ tầng ảo hóa hoàn toàn có thể đạt thông lượng gần với giới hạn phần cứng, xử lý hàng triệu gói tin mỗi giây và duy trì độ trễ thấp ổn định mà vẫn giữ được đầy đủ lợi ích của môi trường cloud.
Cẩm nang triển khai chi tiết nằm trong whitepaper
Bài viết này chỉ tóm lược những nội dung chính của whitepaper "High-Performance OpenStack: Khi hạ tầng cloud Việt Nam không còn là bottleneck". Tài liệu cung cấp đầy đủ các phân tích kỹ thuật, phương pháp tối ưu kiến trúc, kết quả đo kiểm hiệu năng và các case study thực tế để các đội ngũ hạ tầng tham khảo khi xây dựng hoặc nâng cấp cụm OpenStack của mình.
Đây là nguồn tài liệu hữu ích cho các tổ chức đang chuẩn bị cho các workload thế hệ mới, đồng thời muốn khai thác tối đa hiệu năng của hạ tầng cloud mã nguồn mở.
Khám phá toàn bộ kiến trúc, phương pháp đo kiểm hiệu năng và các case study thực tế trong whitepaper tại đây.
Liên hệ với chúng tôi để được tư vấn chi tiết về các giải pháp, dịch vụ của FPT Cloud:
Hotline: 1900 638 399
Email: support@fptcloud.com
Support: m.me/fptsmartcloud

Khi Cloud không còn là nút thắt cổ chai: Hành trình tái kiến trúc hạ tầng cho workload hiệu năng cao
13:33 25/06/2026
Whitepaper “High-Performance OpenStack: Khi hạ tầng cloud Việt Nam không còn là bottleneck” do FPT Smart Cloud thực hiện là tài liệu tổng hợp quá trình nghiên cứu, phát triển và vận hành một kiến trúc hạ tầng tính toán hiệu năng cao được tối ưu từ nhân hệ điều hành (kernel) đến tầng xử lý dữ liệu mạng. Bài viết này điểm lại những luận điểm chính và các kết quả đo kiểm nổi bật trong whitepaper, giúp người đọc có cái nhìn tổng quan trước khi tìm hiểu chi tiết tài liệu gốc.
Trong nhiều năm, tồn tại một quan niệm phổ biến trong ngành công nghệ rằng nếu cần độ trễ cực thấp, băng thông lớn và khả năng xử lý hàng triệu gói tin mỗi giây, doanh nghiệp sẽ phải lựa chọn hạ tầng vật lý thay vì điện toán đám mây.
Quan điểm này từng hoàn toàn có cơ sở khi các kiến trúc cloud truyền thống vẫn phải đi qua nhiều lớp xử lý trung gian, khiến hiệu năng bị ảnh hưởng đáng kể. Tuy nhiên, sự phát triển của nhà máy AI (AI Factory), mạng lõi 5G (5G Core), ảo hóa chức năng mạng (NFV) và các ứng dụng xử lý thời gian thực đang đặt ra một yêu cầu mới: cloud không chỉ cần linh hoạt và dễ mở rộng, mà còn phải đạt hiệu năng đủ cao để đáp ứng những workload vốn trước đây chỉ phù hợp với hạ tầng chuyên dụng.
Cloud hiệu năng cao: Yêu cầu mới của hạ tầng số
Ngày nay, hiệu năng hạ tầng không còn được đo đơn thuần bằng số lượng CPU hay dung lượng RAM.
Một hệ thống nhà máy AI (AI Factory) cần kết nối tốc độ cao giữa các cụm GPU để huấn luyện mô hình. Một nhà mạng triển khai mạng lõi 5G (5G Core) cần khả năng xử lý hàng triệu gói tin (packet) mỗi giây với độ trễ cực thấp. Trong khi đó, các hệ thống tài chính hay truyền phát dữ liệu thời gian thực (streaming) lại yêu cầu sự ổn định tuyệt đối về độ trễ (latency) và độ dao động độ trễ (jitter).
Đây đều là những workload mà trước đây thường được triển khai trên hạ tầng vật lý chuyên dụng. Tuy nhiên, nhu cầu tối ưu chi phí, tăng khả năng mở rộng và tự động hóa vận hành đang khiến doanh nghiệp tìm kiếm những nền tảng cloud có thể đáp ứng đồng thời cả hai yếu tố: hiệu năng và tính linh hoạt.
Vì sao cloud truyền thống trở thành bottleneck?
Một trong những nguyên nhân lớn nhất nằm ở cách gói tin (packet) được xử lý trong môi trường cloud truyền thống.
Một gói tin (packet) phải đi qua nhiều lớp: NIC→ Kernel → Netfilter → Open vSwitch → Hypervisor → Kernel của VM → Ứng dụng
Mỗi lần xử lý dữ liệu chỉ mất một khoảng thời gian rất nhỏ, gần như không đáng kể. Tuy nhiên, khi hệ thống phải xử lý hàng triệu gói dữ liệu mỗi giây, những khoảng thời gian nhỏ đó sẽ cộng dồn lại và ảnh hưởng đáng kể đến hiệu năng tổng thể.
Bên cạnh đó, cơ chế phân bổ tài nguyên của hệ điều hành Linux được thiết kế để phục vụ nhiều tác vụ cùng lúc. Vì vậy, bộ xử lý có thể bị tạm ngắt để thực hiện các công việc nền hoặc xử lý các yêu cầu từ hệ thống. Điều này khiến thời gian phản hồi không hoàn toàn đồng đều, tạo ra những dao động nhỏ và ảnh hưởng đến các ứng dụng yêu cầu độ ổn định cao hoặc phản hồi theo thời gian thực.
Một điểm hạn chế khác nằm ở tầng chuyển tiếp dữ liệu của mạng ảo. Trong một số trường hợp, dữ liệu phải di chuyển qua lại giữa các lớp xử lý khác nhau của hệ điều hành trước khi được gửi đi. Quá trình này làm phát sinh thêm các bước trung gian, khiến thời gian xử lý tăng lên và làm giảm hiệu quả khai thác phần cứng.
Từ góc độ kiến trúc, có thể thấy, thách thức không nằm ở phần cứng, mà nằm ở cách phần mềm khai thác phần cứng.
So sánh Kernel Stack truyền thống và Đường dẫn DPDK
Tư duy mới: Tách biệt tầng xử lý dữ liệu (dataplane) để giải phóng hiệu năng
Để giải quyết các giới hạn trên, Whitepaper High-Performance OpenStack được xây dựng dựa trên nguyên tắc: Tách biệt hoàn toàn tầng dữ liệu khỏi mọi tác vụ khác của hệ điều hành, và đẩy nó lên một con đường được tối ưu riêng từ đầu đến cuối.
Các thành phần điều khiển và vận hành vẫn hoạt động như một môi trường OpenStack tiêu chuẩn. Tuy nhiên, tầng xử lý dữ liệu (dataplane) được đưa vào một "fast path" riêng, nơi tài nguyên được tối ưu hóa dành riêng cho xử lý lưu lượng.
Kiến trúc này được xây dựng dựa trên bốn trụ cột chính. Cụ thể như sau:
Bốn trụ cột của kiến trúc High-Performance OpenStack.
Trụ cột thứ nhất - Tái thiết kế kernel cho workload thời gian thực
Một trong những thay đổi quan trọng nhất của kiến trúc High-Performance OpenStack là tái thiết kế cách hệ điều hành sử dụng tài nguyên CPU. Thay vì để tất cả các tiến trình cùng chia sẻ một tập CPU chung, hệ thống phân tách CPU thành các nhóm chức năng riêng biệt dành cho kernel, hypervisor, Open vSwitch DPDK và các workload của khách hàng.
Bên cạnh đó, các vCPU của máy ảo được gán cố định vào những lõi CPU chuyên dụng (CPU pinning), giúp hạn chế tối đa sự can thiệp của hệ điều hành Linux (Linux scheduler). Cách tiếp cận này giúp giảm hiện tượng dao động độ trễ (jitter), hạn chế các độ trễ phát sinh không mong muốn và mang lại khả năng phản hồi ổn định hơn cho các ứng dụng yêu cầu xử lý theo thời gian thực như mạng lõi 5G (5G Core), suy luận AI (AI Inference) hay các hệ thống tài chính.
Trụ cột thứ hai - Tối ưu bộ nhớ với Hugepage và NUMA Locality
Bộ nhớ cũng là một yếu tố ảnh hưởng trực tiếp đến hiệu năng của hệ thống. Trong môi trường thông thường, bộ nhớ được chia thành các page có kích thước nhỏ, khiến CPU phải quản lý số lượng lớn page và dễ phát sinh chi phí truy xuất bộ nhớ.
Để giải quyết vấn đề này, kiến trúc High-Performance OpenStack sử dụng Hugepage kích thước lớn nhằm giảm đáng kể số lượng page cần quản lý. Nhờ đó, hệ thống hạn chế được các chi phí phát sinh trong quá trình truy xuất bộ nhớ và tối ưu hiệu quả sử dụng CPU.
Song song với đó, toàn bộ các thành phần liên quan đến xử lý lưu lượng như CPU, bộ nhớ, cơ chế xử lý chủ động (Poll Mode Driver - PMD) và card mạng (NIC) được bố trí trên cùng một NUMA node. Việc duy trì tính cục bộ của tài nguyên giúp tránh các truy cập chéo giữa các socket vật lý, từ đó giảm độ trễ và cải thiện hiệu năng tổng thể của hệ thống.
Trụ cột thứ ba - Tầng chuyển mạch trên không gian người dùng
Một thay đổi mang tính nền tảng khác là việc chuyển Open vSwitch từ kernel datapath truyền thống sang userspace datapath dựa trên DPDK.
Trong kiến trúc thông thường, mỗi khi có gói tin đi qua, hệ thống phải xử lý interrupt và thực hiện nhiều lần chuyển đổi ngữ cảnh (context switching), tạo ra chi phí đáng kể khi lưu lượng tăng cao. Với DPDK, Open vSwitch sử dụng cơ chế xử lý chủ động (Poll Mode Driver - PMD), cho phép các lõi CPU chuyên dụng liên tục thăm dò lưu lượng từ card mạng thay vì chờ tín hiệu ngắt (interrupt) từ hệ điều hành.
Cách tiếp cận này giúp loại bỏ phần lớn chi phí xử lý phát sinh từ cơ chế ngắt của hệ thống và chuyển đổi ngữ cảnh (context switching), từ đó giảm độ trễ, tăng khả năng xử lý gói tin (packet) và tạo ra một tầng xử lý dữ liệu (dataplane) hiệu năng cao hơn đáng kể so với mô hình truyền thống.
Trụ cột thứ tư - Đẩy việc xuống chip mạng
Sau khi tối ưu tầng phần mềm, bước tiếp theo là khai thác tối đa các tính năng tăng tốc sẵn có trên phần cứng hiện đại. Các card mạng như NVIDIA Mellanox ConnectX-6 được trang bị nhiều cơ chế chuyển tải xử lý xuống phần cứng (offload), cho phép đảm nhiệm một phần công việc xử lý gói tin (packet) thay cho CPU.
Các công việc như xử lý thông tin điều khiển của gói tin, quản lý luồng dữ liệu nhận vào hay giảm lượng dữ liệu cần chuyển qua CPU đều có thể được thực hiện trực tiếp trên card mạng thay vì bộ xử lý trung tâm. Nhờ đó, CPU được giải phóng khỏi các tác vụ xử lý lặp lại, tập trung nhiều hơn vào workload chính và nâng cao hiệu quả sử dụng tài nguyên của toàn hệ thống.
Khi kết hợp với các tối ưu về CPU, bộ nhớ và tầng xử lý dữ liệu (dataplane), khả năng chuyển tải xử lý xuống phần cứng (offload) đóng vai trò quan trọng trong việc đưa hiệu năng của môi trường điện toán đám mây tiến gần hơn tới giới hạn của hạ tầng vật lý.
Cloud hiệu năng cao đang trở thành nền tảng cho thế hệ hạ tầng mới
Khi AI, 5G, các hệ thống tài chính thời gian thực và những ứng dụng yêu cầu độ trễ thấp tiếp tục phát triển, hiệu năng hạ tầng không còn là một yêu cầu riêng biệt của một số ngành đặc thù mà đang trở thành yếu tố cốt lõi trong chiến lược chuyển đổi số của doanh nghiệp. Trong bối cảnh đó, khả năng kết hợp giữa hiệu năng gần với hạ tầng vật lý và sự linh hoạt của môi trường cloud sẽ trở thành lợi thế cạnh tranh quan trọng.
High-Performance OpenStack mang đến một cách tiếp cận mới cho hạ tầng cloud, nơi các giới hạn truyền thống về độ trễ, thông lượng hay khả năng xử lý gói tin (packet) được giải quyết ngay từ tầng kiến trúc. Thông qua việc tối ưu toàn diện từ CPU, bộ nhớ, mạng đến phần cứng tăng tốc, doanh nghiệp có thể xây dựng những nền tảng sẵn sàng cho các workload thế hệ mới mà vẫn duy trì đầy đủ các lợi ích vốn có của cloud.
Whitepaper "High-Performance OpenStack: Khi hạ tầng cloud Việt Nam không còn là bottleneck" không chỉ trình bày các kỹ thuật tối ưu hiệu năng, mà còn mang đến góc nhìn toàn diện về cách xây dựng và vận hành hạ tầng cloud hiệu năng cao trong kỷ nguyên AI và dữ liệu thời gian thực. Đây là bước đi quan trọng giúp doanh nghiệp chuẩn bị cho tương lai, nơi khả năng khai thác tối đa tài nguyên hạ tầng sẽ quyết định tốc độ đổi mới và năng lực cạnh tranh.
Khám phá cách FPT Smart Cloud tái kiến trúc hạ tầng OpenStack để đưa cloud tiến gần hơn đến hiệu năng của hệ thống vật lý, đồng thời đáp ứng những yêu cầu khắt khe của các workload hiệu năng cao tại đây.
Liên hệ với chúng tôi để được tư vấn chi tiết về các giải pháp, dịch vụ của FPT Cloud:
Hotline: 1900 638 399
Email: support@fptcloud.com
Support: m.me/fptsmartcloud

Từ GPU đến AI Factory: Chuẩn hóa kiến trúc hạ tầng AI trên nền tảng OpenStack
09:12 16/01/2026
Trong bài viết trước, chúng ta đã khẳng định OpenStack là "xương sống" cho hạ tầng AI thế hệ mới. Tuy nhiên, để chuyển đổi từ một cụm máy chủ gắn GPU rời rạc thành một AI Factory - một nhà máy sản xuất trí tuệ nhân tạo có khả năng thương mại hóa và mở rộng vô hạn – doanh nghiệp cần một bản thiết kế kiến trúc chuẩn mực.
Dựa trên Whitepaper "Open Infrastructure for AI", kiến trúc AI hiện đại không còn là câu chuyện của riêng con chip, mà là sự hòa quyện của ba trụ cột: GPU tối ưu, Lưu trữ hiệu năng cao và Mạng tốc độ cực lớn.
GPU: Tài nguyên chiến lược và tư duy đa mô hình
Trong một AI Factory, GPU không chỉ là phần cứng tăng tốc, nó là "tiền tệ" của hệ thống. Để tối ưu hóa dòng tiền này, kiến trúc hạ tầng phải cho phép khai thác GPU theo nhiều kịch bản khác nhau thay vì một cấu hình cố định.
OpenStack mang lại sự linh hoạt đặc yếu qua ba phương thức tiếp cận:
PCI Passthrough: Dành cho các tác vụ huấn luyện (Training) mô hình lớn hoặc suy luận (Inference) thời gian thực. Bằng cách gắn trực tiếp GPU vật lý vào máy ảo, chúng ta loại bỏ độ trễ của lớp trung gian, đạt hiệu năng tương đương máy chủ vật lý (Bare-metal).
Virtual GPU (vGPU): Giải pháp hoàn hảo cho môi trường phát triển (R&D) hoặc thử nghiệm. Một GPU vật lý được chia sẻ cho nhiều người dùng, giúp tối ưu hóa chi phí đầu tư ban đầu.
Multi-Instance GPU (MIG): Đây là chìa khóa cho mô hình AI đa người dùng (Multi-tenant). MIG chia nhỏ GPU thành các phân vùng có tài nguyên phần cứng độc lập, đảm bảo tính cô lập tuyệt đối và độ ổn định cho các dịch vụ Inference quy mô lớn.
Lợi thế của AI Factory trên nền OpenStack chính là khả năng điều phối tự động cả ba mô hình này trên cùng một cụm tài nguyên thông qua API, giúp doanh nghiệp sẵn sàng cung cấp dịch vụ GPU-as-a-Service chuyên nghiệp.
Lưu trữ và Network: "Hệ thần kinh" của các mô hình LLM
Nếu GPU là bộ não, thì lưu trữ và mạng lưới chính là hệ thần kinh trung ương. Với các mô hình ngôn ngữ lớn (LLM) nặng hàng trăm GB, bài toán không còn là "lưu trữ ở đâu" mà là "dữ liệu di chuyển nhanh thế nào".
Lưu trữ hiệu năng cao (HPS) – Bài toán sống còn
Thời gian tải mô hình từ ổ cứng lên vRAM của GPU quyết định tính sẵn sàng của dịch vụ. Whitepaper nhấn mạnh vai trò của Parallel File System. Trong kiến trúc AI Factory, lưu trữ không còn là thành phần phụ trợ mà là yếu tố quyết định khả năng mở rộng (Scalability) và thời gian đưa dịch vụ ra thị trường (Time-to-market).
Network - Kết nối quy mô siêu máy tính
Workload AI đòi hỏi băng thông mạng từ 100Gb/s đến 200Gb/s – gấp 10-20 lần so với ứng dụng web truyền thống. Để vận hành như một hệ thống HPC (Tính toán hiệu năng cao) thực thụ, AI Factory tích hợp sâu các công nghệ:
RDMA & InfiniBand: Giảm tải cho CPU và tăng tốc truyền dữ liệu giữa các node GPU.
SR-IOV: Tối ưu hóa hiệu suất mạng cho máy ảo.
Tối ưu hóa: Lợi thế cạnh tranh nằm ở những "chi tiết ẩn"
Một kiến trúc sư hạ tầng AI giỏi khác biệt ở chỗ họ biết cách "tinh chỉnh" những thông số nhỏ để tạo ra hiệu năng lớn. OpenStack cho phép can thiệp sâu vào tầng dưới cùng của phần cứng – điều mà các nền tảng Public Cloud đóng thường hạn chế:
NUMA Affinity & CPU Pinning: Giảm thiểu độ trễ truy cập bộ nhớ, giúp GPU VM hoạt động mượt mà nhất.
Hardware Offload & RoCE: Tận dụng tối đa năng lực card mạng để giảm tải cho vi xử lý chính.
Chính những tinh chỉnh mang tính đặc thù này giúp các AI Factory vận hành trên hạ tầng mở đạt hiệu suất vượt trội hơn hẳn so với các cấu hình phần cứng tương đương trên nền tảng đóng.
Hệ sinh thái toàn diện: Từ hạ tầng đến dịch vụ thương mại
Sức mạnh thực sự của OpenStack nằm ở khả năng biến các tài nguyên thô thành một hệ sinh thái dịch vụ hoàn chỉnh:
OpenStack Ironic: Cung cấp GPU Bare-metal cho các tác vụ cần hiệu năng tuyệt đối.
Magnum: Triển khai cụm Kubernetes GPU phục vụ container hóa ứng dụng AI.
Trove & Manila: Tự động hóa quản trị cơ sở dữ liệu và hệ thống tệp tin cho AI.
Khả năng tùy biến sâu này giúp doanh nghiệp không chỉ xây dựng được hạ tầng AI mà còn sở hữu một nền tảng sẵn sàng cho thương mại hóa, có thể thích ứng với bất kỳ framework hay dòng chip AI mới nào xuất hiện trong tương lai.
Minh chứng từ thực tế
Kiến trúc AI Factory trên nền OpenStack không còn là lý thuyết. Từ những "gã khổng lồ" viễn thông như China Mobile, các nhà cung cấp cloud như Rackspace, cho đến những đơn vị tiên phong tại Việt Nam như FPT Smart Cloud (FPT Cloud & FPT AI Factory), tất cả đều đang chứng minh rằng: Hạ tầng mở là con đường ngắn nhất và bền vững nhất để làm chủ cuộc chơi AI.
Đứng sau sự thành công này là AI Working Group (thuộc OpenInfra Foundation) – nơi quy tụ những khối óc hàng đầu thế giới về hạ tầng mở. Sự kết nối tri thức này đảm bảo rằng AI Factory của doanh nghiệp bạn luôn được vận hành dựa trên những tiêu chuẩn kiến trúc tiên tiến nhất toàn cầu.
Xem thêm thông tin về OpenStack tại đây.
Tác giả: Trần Quốc Sang
Phó Giám đốc Trung tâm Phát triển Dịch vụ Hạ Tầng Cloud - FPT Smart Cloud, Tập đoàn FPT

Open Infrastructure for AI: Vì sao OpenStack đang trở thành nền tảng hạ tầng chiến lược cho AI thế hệ mới
14:39 09/01/2026
Sự trỗi dậy của Generative AI không chỉ thay đổi cách chúng ta tương tác với công nghệ mà đã kéo theo một làn sóng tái kiến trúc hạ tầng ở quy mô toàn cầu. Những mô hình ngôn ngữ lớn (LLM), GPU chuyên dụng như H100/H200, hay các cụm HPC tốc độ cao đã khiến yêu cầu về hạ tầng tăng mạnh chưa từng thấy. Doanh nghiệp không chỉ cần sức mạnh tính toán; họ cần một nền tảng mở, linh hoạt, dễ mở rộng và có khả năng bắt kịp tốc độ thay đổi của hệ sinh thái AI. Họ cần một "AI Factory" – một nhà máy AI thực thụ.
Trong bối cảnh đó, OpenStack đang nổi lên như một nền tảng mở, linh hoạt và mạnh mẽ, đóng vai trò kim chỉ nam cho hạ tầng AI thế hệ tiếp theo nơi khả năng mô-đun hóa, tự do tích hợp và tốc độ cải tiến cộng đồng trở thành lợi thế vượt trội.
OpenStack: Nền tảng mở cho kỷ nguyên AI
Khi các workload AI ngày càng tiêu tốn tài nguyên hơn và nhạy cảm về độ trễ hơn, OpenStack cung cấp lớp ảo hóa và quản trị hạ tầng mạnh mẽ, đủ khả năng hỗ trợ môi trường tính toán hiệu suất cao thông qua các dịch vụ như Nova, Neutron, Cinder và Ironic. Khả năng mở rộng đã được kiểm chứng và mức độ linh hoạt cao khiến OpenStack trở thành lựa chọn phù hợp cho thế hệ tiếp theo của workload AI và HPC.
Khác với các giải pháp đám mây độc quyền vốn phụ thuộc vào lộ trình của nhà cung cấp, OpenStack được phát triển bởi chính cộng đồng những doanh nghiệp vận hành nó trong thực tế. Điều này đảm bảo tốc độ cải tiến nhanh, khả năng cập nhật các công nghệ mới nổi như lập lịch GPU đa người dùng, tối ưu theo NUMA hay tăng tốc mạng SR-IOV, đồng thời mang lại mức độ linh hoạt mà các nền tảng đóng không thể có.
Xuất phát từ thực tiễn đó, AI Working Group - được thành lập bởi Open Infra Foundation đã cùng hợp tác để giới thiệu kiến trúc và usecase công nghệ của việc sử dụng OpenStack nhằm hỗ trợ các workload AI trong whitepaper “Open Infrastructure for AI: OpenStack’s Role in the Next Generation Cloud”
Kim chỉ nam cho hạ tầng AI - Và 5 bài toán lớn định hình tương lai
Generative AI tạo ra một sự thay đổi căn bản trong cách chúng ta thiết kế, triển khai và vận hành hạ tầng AI. Việc huấn luyện mô hình ngôn ngữ lớn, tự lưu trữ các mô hình mã nguồn mở, hay phục vụ suy luận (inference) ở quy mô lớn đòi hỏi phần cứng thế hệ mới như GPU H100/H200 cùng với tốc độ kết nối và băng thông lưu trữ ở mức HPC.
Nhằm bám sát vào những thay đổi lớn của hạ tầng AI thế hệ mới này, 5 bài toán kinh điển và cách thức để hạ tầng mã nguồn mở giải quyết chúng đã được đưa ra bao gồm:
1. ModelTraining & Serving - Tăng tốc sáng tạo mô hình
Trong nhiều năm, xây dựng một pipeline AI hoàn chỉnh đòi hỏi đội ngũ kỹ thuật phải giải quyết hàng loạt bước phức tạp ở tầng hạ tầng. Xu hướng hiện nay đi theo hướng đơn giản hóa: nhà phát triển ứng dụng AI không cần quan tâm vào hạ tầng, chỉ cần thông qua giao diện code như Jupiter Notebook hoặc code IDE là có thể gọi vào training một model LLM. Sau khi training thì có thể chạy serving model đó thông qua API (e.g. OpenAI Compatible API) chỉ với vài thao tác.
2. GPU-as-a-Service - Tối ưu hiệu năng và chi phí GPU
Những dòng GPU tân tiến như H100/H200 rất mạnh mẽ nhưng giá thành cao, việc sở hữu một thiết bị H100 gần như là chỉ có ở những doanh nghiệp lớn và thường không sử dụng hết năng lực của một thiết bị gây lãng phí, thay vào đó là việc đi thuê tài nguyên mang lại chi phí tối ưu hơn và phù hợp cho mọi doanh nghiệp. Kiến trúc mở cho phép chia nhỏ GPU thành nhiều phần (MIG), xây dựng máy ảo GPU theo nhu cầu (vGPU), hoặc cấp quyền truy cập trực tiếp (PCI Passthrough) để tối ưu hiệu năng.
Thay vì sở hữu toàn bộ phần cứng, doanh nghiệp có thể thuê đúng mức tài nguyên cần thiết, tránh tình trạng “đầu tư lớn – sử dụng thấp”, đồng thời linh hoạt mở rộng theo nhịp phát triển AI. Doanh nghiệp có thể tham khảo dịch vụ cho thuê GPU Cloud (GPU Server) hiệu năng cao của FPT Cloud với GPU chuyên dụng của NVIDIA: H200, H100 và A30.
3. Nền tảngMLOps - Vận hành mô hình AI ở quy mô lớn
Các mô hình ngôn ngữ lớn thay đổi nhanh chóng và đòi hỏi một vòng đời vận hành liên tục: cập nhật mô hình, giám sát, tối ưu chi phí suy luận, kiểm soát hiệu năng, đảm bảo uptime. Một nền tảng MLOps hiện đại cần làm được tất cả điều này trong khi vẫn duy trì sự ổn định của hệ thống và tính liên tục của dịch vụ.
OpenStack với bộ dịch vụ mở rộng xung quanh trở thành lựa chọn phù hợp để xây dựng nền tảng tự động hóa toàn trình, từ training đến inference.
4. High-PerformanceComputing Cluster - Sức mạnh kết nối cụm GPU lớn
Những mô hình hàng tỷ tham số yêu cầu khả năng huấn luyện phân tán trên hàng chục node GPU. Kết nối một cụm 32 node H100 với thông lượng Tbps, độ trễ cực thấp và khả năng đọc ghi dữ liệu tốc độ cao là một thách thức mà chỉ các nền tảng HPC thực thụ có thể đáp ứng.
OpenStack cung cấp khả năng quản lý bare-metal kết hợp với các công nghệ tối tân như Infiniband, high-performance storage, giúp doanh nghiệp tiếp cận sức mạnh của các “AI SuperPod” theo cách linh hoạt và tối ưu chi phí hơn.
5. AIIoT& Edge Computing - Đưa AI đến gần dữ liệu hơn
Ứng dụng AI ngày càng mở rộng sang robot, xe tự hành, camera thông minh và các thiết bị IoT. Những tác vụ này cần xử lý ngay tại nguồn để đảm bảo tốc độ theo thời gian thực. Kiến trúc phân tán, edge computing và khả năng đồng bộ giữa trung tâm dữ liệu - biên - thiết bị trở thành yếu tố then chốt.
OpenStack hỗ trợ tốt cho những mô hình hạ tầng lai (hybrid) và distributed, giúp doanh nghiệp triển khai AI ở biên một cách nhất quán và an toàn.
OpenStack - nền tảng mở cho tương lai AI
Trong thế giới nơi AI đang thúc đẩy mọi ngành công nghiệp, một hạ tầng mở, linh hoạt và dễ mở rộng không còn là tùy chọn - mà trở thành nền tảng cốt lõi. OpenStack mang lại khả năng tùy biến sâu, tích hợp rộng và tốc độ cải tiến nhanh nhờ cộng đồng, giúp doanh nghiệp xây dựng “AI Factory” với chi phí tối ưu và khả năng mở rộng bền vững.
Whitepaper “Open Infrastructure for AI” không chỉ mô tả các kiến trúc kỹ thuật, mà mở ra cách nhìn toàn diện về việc vận hành AI ở quy mô lớn bằng hạ tầng mở. Đây là bước đi quan trọng để doanh nghiệp sẵn sàng cho tương lai AI, nơi tốc độ và khả năng tự chủ hạ tầng trở thành lợi thế cạnh tranh hàng đầu.
Khám phá cách chuyển đổi từ một cụm máy chủ gắn GPU rời rạc thành một AI Factory hiệu năng mạnh mẽ tại đây.
Tác giả: Trần Quốc Sang
Phó Giám đốc Trung tâm Phát triển Dịch vụ Hạ Tầng Cloud - FPT Smart Cloud, Tập đoàn FPT

Phát hiện & xử lý nhanh chóng lỗ hổng CVE-2025-55182 với tính năng Image Scanning của FPT AppSec
09:27 18/12/2025
1. CVE-2025-55182 – Lỗ hổng RCE “React2Shell” & Thống kê đáng báo động
Cuối năm 2025, cộng đồng bảo mật toàn cầu đã bị báo động mạnh mẽ bởi một lỗ hổng cực kỳ nguy hiểm mang tên CVE-2025-55182, hay còn gọi là React2Shell, liên quan đến cơ chế React Server Components (RSC) và lan rộng đến các framework như Next.js, vốn được sử dụng phổ biến trong hàng chục triệu ứng dụng web và dịch vụ đám mây.
Theo dữ liệu nghiên cứu bảo mật, ~39% môi trường cloud surveyed chứa instance dễ bị tấn công bởi lỗ hổng này, tức là gần 4 trong 10 hệ thống cloud đang hoạt động có nguy cơ bị khai thác nếu chưa vá lỗi.
Những gì khiến CVE-2025-55182 trở nên “nóng”: (1) Điểm CVSS tối đa 10.0, mức nghiêm trọng cao nhất, cho phép thực thi mã từ xa ngay cả khi không xác thực; (2) Exploit đã bắt đầu xuất hiện trong tự nhiên chỉ sau vài giờ kể từ khi được công khai, với nhiều scanner tự động và tay hacker chủ động tìm kiếm mục tiêu; (3) Các nhóm tội phạm mạng được ghi nhận khai thác lỗ hổng này để chèn malware, mở backdoor và thu thập credential; (4) Báo cáo cho thấy ít nhất ~30 tổ chức ở nhiều lĩnh vực khác nhau đã bị xâm nhập, bao gồm rò rỉ thông tin đăng nhập, cài malware khai thác tiền điện tử và mở lối vào hệ thống.
Trong bối cảnh này, việc phát hiện sớm lỗ hổng trong container image, hiểu rõ chính xác package/version bị ảnh hưởng ngay từ đầu, và xử lý trước khi sản phẩm được đưa vào production là ưu tiên hàng đầu của mọi đội DevSecOps.
Và đây là lúc FPT AppSec - với tính năng Image Scanning mạnh mẽ, phát huy vai trò quan trọng, giúp doanh nghiệp scan hàng nghìn image tự động, xác định đúng vị trí tồn tại lỗ hổng như CVE-2025-55182 và giảm thiểu rủi ro trong thời gian ngắn nhất.
2. Case study: FPT AppSec – Giải pháp phát hiện & xử lí CVE-2025-55182 chỉ trong vài giây
Khi khách hàng kích hoạt Image Scanning (tích hợp Docker registry hoặc CI/CD pipeline), FPT AppSec lập tức phân tích tất cả layer của image.
Trong phát hiện CVE-2025-55182, hệ thống đã: (1) Nhanh chóng xác định đúng image bị ảnh hưởng; (2) Highlight rõ gói next@15.x đang chứa lỗ hổng; (3) Chỉ ra layer build mà package này được đưa vào container; (4) Xếp hạng mức độ Critical và cảnh báo real-time.
Nhờ vậy, thay vì phải grep log build hoặc manually check package version, đội kỹ thuật có thể xử lí ngay, đúng vị trí gây rủi ro, giảm đáng kể thời gian điều tra.
[caption id="attachment_69816" align="aligncenter" width="977"] FPT AppSec phát hiện image chứa thành phần Next.js bị ảnh hưởng bởi lỗ hổng CVE-2025-55182[/caption]
Một trong những khó khăn lớn nhất khi xử lý lỗ hổng trong container là: “Package này đến từ đâu? Layer nào? Tại sao image lại mang phiên bản dễ tổn thương?”
Với FPT AppSec, người dùng có thể giải quyết triệt để bằng cách hiển thị Dockerfile layer gây ra việc cài đặt dependency và cho biết danh sách phiên bản an toàn (patched versions).
[caption id="attachment_69817" align="aligncenter" width="977"] FPT AppSec chỉ rõ lỗ hổng xuất hiện ở layer nào trong image[/caption]
FPT AppSec sở hữu những tính năng ưu việt giúp người dùng xử lý nhanh chóng, chính xác những sự cố như CVE-2025-55182:
Quét số lượng lớn image cùng lúc: Hệ thống được xây dựng theo kiến trúc cloud-native, scale-out linh hoạt, có thể xử lí mượt mà 100 hay 10.000 container images.
Phát hiện lỗ hổng real-time: Ngay khi CVE mới được công bố, hệ thống tự động đồng bộ dữ liệu vulnerability feed và re-scan nếu cần.
Giảm thời gian phản ứng từ hàng giờ xuống vài phút: Đội DevSecOps không cần truy ngược build log, không cần manually inspect, mọi thứ hiển thị trực quan.
Dễ dàng tích hợp vào hệ thống CI/CD hiện tại: Chỉ một bước thêm vào pipeline, FPT AppSec sẽ quét trước khi image được push lên registry.
3. Hướng dẫn chi tiết Cách xử lý CVE-2025-55182 trong thực tế
CVE-2025-55182 là một lỗ hổng Remote Code Execution (RCE) cực kỳ nghiêm trọng trong React Server Components (RSC), cho phép kẻ tấn công thực thi mã trên server mà không cần xác thực thông qua payload đặc biệt gửi tới endpoint RSC. Lỗi gốc nằm ở việc deserialization không an toàn của các component trên server. NVD
Bước 1: Xác định phạm vi ảnh hưởng - React Server Components
Các phiên bản sau của React Server Components bị ảnh hưởng:
react-server-dom-webpack: 0.0, 19.1.0, 19.1.1, 19.2.0
react-server-dom-parcel: 0.0, 19.1.0, 19.1.1, 19.2.0
react-server-dom-turbopack: 0.0, 19.1.0, 19.1.1, 19.2.0 NVD
Những phiên bản này là đích ngắm chính của exploit do lỗi xử lý unsafe deserialization trong Flight Protocol. NVD
Next.js
Mặc dù lỗi gốc là ở React RSC, Next.js cũng chịu ảnh hưởng khi sử dụng RSC trong App Router. Theo advisory từ Next.js, các version Next.js bị ảnh hưởng và đã được patched bao gồm: Next.js
Next.js
Tình trạng
15.0.0 – 15.0.4
Vulnerable
15.1.0 – 15.1.8
Vulnerable
15.2.0 – 15.2.5
Vulnerable
15.3.0 – 15.3.5
Vulnerable
15.4.0 – 15.4.7
Vulnerable
15.5.0 – 15.5.6
Vulnerable
16.0.0 – 16.0.6
Vulnerable
Tương ứng các bản an toàn (patched) đã được Next.js phát hành:
0.5, 15.1.9, 15.2.6
3.6, 15.4.8, 15.5.7
0.7 Next.js
Bước 2: Cập nhật dependency ngay
Nguyên tắc đầu tiên và quan trọng nhất là không chạy code với phiên bản RSC/Next.js dễ bị tấn công:
React Server Components: Cập nhật các package RSC lên phiên bản an toàn mới nhất (ví dụ 19.2.1 hoặc cao hơn nếu đã phát hành)
npm install react-server-dom-webpack@19.2.1 \
react-server-dom-parcel@19.2.1 \
react-server-dom-turbopack@19.2.1
Lưu ý: Nếu bạn không trực tiếp thêm các package RSC vào project, hãy kiểm tra plugin/bundler (ví dụ Webpack/Turbopack) đang sử dụng có phụ thuộc RSC hay không và cập nhật tương ứng.
Next.js: Nâng Next.js lên ít nhất một trong các bản đã patched. Đảm bảo lựa chọn đúng phiên bản phù hợp với nhánh hiện tại của bạn để không gây xung đột dependency.
npm install next@15.0.5 # nếu đang dùng 15.0.x
npm install next@15.1.9 # nếu đang dùng 15.1.x
npm install next@15.2.6 # nếu đang dùng 15.2.x
npm install next@15.3.6 # nếu đang dùng 15.3.x
npm install next@15.4.8 # nếu đang dùng 15.4.x
npm install next@15.5.7 # nếu đang dùng 15.5.x
npm install next@16.0.7 # nếu đang dùng 16.x
Bước 3. Quét lại & xác nhận bằng FPT AppSec
Sau khi nâng cấp:
Rebuild toàn bộ image/container để loại bỏ dependency cũ.
Scan lại với FPT AppSec Image Scanning để đảm bảo không còn phiên bản vulnerable trong bất kỳ layer nào.
Kiểm tra điều kiện chạy (runtime environment, build cache, CI/CD pipeline) để chắc chắn không còn CVE-2025-55182.
FPT AppSec sẽ chỉ ra chính xác: Image nào còn chứa phiên bản vulnerable; Layer nào cài đặt các package đó; Package/version hiện tại đã được cập nhật hay chưa. Điều này giúp bạn chốt được việc xử lý tận gốc, không chỉ patch tạm thời.
Tác giả: Lê Ngọc Linh
Chuyên gia Bảo mật - FPT Smart Cloud, Tập đoàn FPT

Phát hiện mối đe dọa – Tự động khắc phục – Phản ứng nhanh: Hướng tiếp cận thực tiễn cho doanh nghiệp Cloud-native
13:46 15/12/2025
Trong vài năm trở lại đây, phần lớn doanh nghiệp có xu hướng chuyển dần sang hạ tầng cloud hoặc các mô hình hybrid. Điều này mang lại tốc độ triển khai ứng dụng vượt bậc nhưng đồng thời cũng thay đổi hoàn toàn cách chúng ta đối diện với rủi ro bảo mật. Từ những cuộc tấn công tinh vi hơn do AI thúc đẩy, đến mức độ phức tạp ngày càng cao của kiến trúc microservices - tất cả đều khiến các công cụ bảo mật truyền thống trở nên “đuối sức".
Bài viết này chia sẻ góc nhìn từ quá trình xây dựng hệ thống bảo vệ cloud-native tại FPT Smart Cloud, dựa trên triết lý CNAPP (Cloud-Native Application Protection Platform). Thay vì nói về “một sản phẩm”, chúng ta sẽ nói về “một hành trình” - và hành trình đó bắt đầu từ việc nhìn lại chính những điểm yếu thường trực trong môi trường ứng dụng hiện đại.
1. Khi tốc độ phát triển vượt quá tốc độ kiểm soát: Mối nguy hình thành từ đâu?
Điều đầu tiên cần thừa nhận: Hầu hết lỗ hổng xuất hiện không phải do hacker quá thông minh, mà do hệ thống quá phức tạp và đang thay đổi quá nhanh.
Nếu như trước đây, một ứng dụng cần vài tháng để có một bản cập nhật mới thì ngày nay, một đội DevOps nhỏ có thể triển khai hàng chục phiên bản mới mỗi tuần nhờ pipeline CI/CD luôn hoạt động, commit liên tục và khả năng tạo lập hạ tầng tức thì bằng IaC.Cùng với đó, container, microservices, serverless... khiến bề mặt tấn công được mở rộng theo cấp số nhân. Trong bối cảnh đó, những sai sót như S3 bucket để public, IAM role cấp quyền quá rộng, API key lọt vào repo hay các gói thư viện chứa CVE nghiêm trọng rất dễ bị bỏ sót giữa hàng trăm thay đổi mỗi ngày.
Song song với đó, việc AI được sử dụng trong tấn công mạng đã giúp gia tăng tốc và mức độ tinh vi của các kỹ thuật tấn công một cách đáng kể. Một số báo cáo gần đây cho thấy những chiến dịch tấn công có dấu hiệu được tự động hóa bằng AI để mở rộng quy mô dò quét, tạo email giả mạo, thậm chí giả lập hành vi người dùng. Khi bên tấn công có “tốc độ máy”, bên phòng thủ không thể tiếp tục vận hành theo kiểu thủ công.
Nói cách khác, tốc độ và mức độ phức tạp của các cuộc tấn công hiện nay khiến doanh nghiệp buộc phải thay đổi chiến lược bảo vệ.
2. Tại sao chỉ quét production là chưa đủ?
Một thực tế thú vị trong ngành bảo mật là phần lớn lỗ hổng bảo mật nằm ngay trong code và cấu hình ở giai đoạn đầu, nhưng lại được phát hiện muộn nhất - thường là ở runtime.
Trong khi đó, chi phí sửa lỗi trong production có thể tốn kém gấp 30 lần so với khi phát hiện ngay lúc viết code. Con số có thể thay đổi tùy báo cáo, nhưng ý nghĩa thì không đổi khi càng phát hiện muộn, chi phí càng lớn, từ downtime, ảnh hưởng tới người dùng, đến tài nguyên SOC.
Thực tế tại nhiều doanh nghiệp, đội vận hành phải dành hàng giờ kiểm tra thủ công sự cố, trong khi nếu doanh nghiệp tích hợp công cụ quét vào pipeline, cùng lỗi đó có thể được phát hiện và ngăn ngay khi developer push code.
Như vậy, nếu mục tiêu là “phản ứng nhanh và khắc phục tự động”, việc phòng thủ phải bắt đầu trước khi mã chạy, chứ không thể đợi đến khi incident xảy ra.
3. CNAPP - Giải pháp hợp nhất thay cho hệ thống bảo mật rời rạc
Trong nhiều năm, các mảng AppSec, CSPM, CWPP, SIEM, hay SOAR… hoạt động như những “mảnh ghép rời rạc". Mỗi bộ phận triển khai công cụ riêng như đội DevSecOps quản lý SAST/DAST, đội hạ tầng phụ trách CSPM, SOC vận hành SIEM/SOAR hay nhóm vận hành container sử dụng CWPP. Mỗi công cụ này đều có giá trị riêng, nhưng khi đứng tách biệt, chúng không thể trả lời câu hỏi quan trọng nhất: “Trong hàng nghìn cảnh báo mỗi ngày, điều gì thực sự khiến hệ thống gặp rủi ro?”
CNAPP ra đời để giải quyết vấn đề này. Đây không phải một sản phẩm cụ thể, mà là một cách hợp nhất góc nhìn bảo mật từ code → hạ tầng → runtime → vận hành. Sau khi gom toàn bộ tín hiệu riêng lẻ vào một bức tranh thống nhất, CNAPP áp dụng phân tích ngữ cảnh để hiểu mối liên hệ giữa chúng. Từ đó, hệ thống có thể xác định, ưu tiên các lỗ hổng quan trọng, tự động hoá bước khắc phục và rút ngắn thời gian phản ứng từ hàng giờ xuống chỉ còn vài phút.
Đặc biệt, CNAPP không chỉ quét, nó còn có khả năng hiểu ngữ cảnh. Một lỗ hổng CVE mức cao có thể có mức độ rủi ro thấp nếu container đó không public ra ngoài và hoàn toàn không có traffic. Ngược lại, việc để lộ một API trong repo nhưng pipeline lại không ngăn chặn có thể là mối đe doạ nghiêm trọng.
Chỉ khi có bức tranh tổng thể này, doanh nghiệp mới đưa ra quyết định đúng, tập trung vào những rủi ro đáng xử lý nhất mà không bị “ngộp” bởi hàng nghìn cảnh báo ồn ào.
4. Từ kinh nghiệm triển khai: Vì sao AppSec/ASPM nên là điểm khởi đầu?
Ở FPT Smart Cloud, AppSec là bước mang lại hiệu quả rõ rệt nhất ngay từ đầu. Các bản quét code giúp phát hiện sớm những lỗi logic hoặc lỗ hổng injection. Việc quét IaC cũng giúp nhận diện các cấu hình sai như việc mở port không cần thiết, bỏ sót encryption hay IAM role quá rộng. Các công cụ secret scan giúp phát hiện kịp thời API key hoặc credentials trong repo. Đồng thời, image scan giúp làm rõ những gói phụ thuộc tồn tại CVE nghiêm trọng.
Trước đây, những việc này được làm thủ công mất từ vài giờ đến vài ngày. Sau khi tự động hóa trong pipeline CI/CD, thời gian xử lý rút xuống chỉ còn vài phút.
Chính vì vậy, điểm cốt lõi không nằm ở việc “dùng công cụ gì”, mà ở cách đưa bảo mật vào đúng thời điểm, biến nó thành một phần tự nhiên của vòng đời phát triển.
Tham khảo: FPT AppSec hỗ trợ đội ngũ bảo mật tìm ra CVE-2025-63601 tại đây.
5. Từ code đến vận hành: Các lớp bảo mật doanh nghiệp cần mở rộng
AppSec giúp giảm rủi ro từ gốc, nhưng để một hệ thống thực sự có khả năng phát hiện và phản ứng nhanh, doanh nghiệp cần thêm các lớp bảo vệ mạnh mẽ.
CSPM (Cloud Security Posture Management) đóng vai trò quan sát cấu hình cloud theo thời gian thực. Nhờ đó, doanh nghiệp có thể phát hiện các rủi ro như storage bucket bị public, network rule mở quá rộng, các encryption bị tắt hoặc các dữ liệu nhạy cảm nằm sai vị trí. Điều đáng nói là phần lớn những sự cố cloud lớn trong suốt thập kỷ qua đều bắt nguồn từ cấu hình sai tương tự.
Bên cạnh CSPM, CWPP (Cloud Workload Protection Platform)giúpbảo vệ workload trong quá trình runtime với khả năng phát hiện những hành vi bất thường, quy trình lạ trong container/VM, hỗ trợ tự động cô lập phiên bản bị xâm nhập.
Ở tầng mạng, Cloud Network Firewall đóng vai trò phòng thủ quan trọng trong các môi trường multi-cloud hoặc hybrid. Firewall giúp phân vùng mạng, giảm nguy cơ lateral movement. Một số giải pháp firewall hiện đại còn tích hợp thêm WAF hoặc IDPS.
Cuối cùng, SIEM kết hợp cùng SOAR giúp kết nối mọi dữ liệu để tự động hóa phản ứng. Một nền tảng SIEM/SOAR mạnh có khả năng thu thập log từ AppSec, CSPM, CWPP, Firewall, IAM sau đó mapping theo MITRE ATT&CK để xác minh hành vi tấn công, thay vì xem từng alert nhỏ lẻ. Khi cần, hệ thống có thể tự động chạy playbook để cô lập workload, vô hiệu hoá credential, chặn IP độc hại mà không cần con người can thiệp. Đây là bước quan trọng giúp doanh nghiệp chuyển từ thế “bị động" sang “chủ động".
6. FPT Cloud Defense - Giải pháp hiện thực hoá CNAPP theo cách linh hoạt
FPT Cloud Defense hiện thực hoá triết lý CNAPP bằng cách chia nhỏ thành các năng lực dễ áp dụng và phù hợp với trạng thái trưởng thành của doanh nghiệp theo lộ trình:
Bước 1: Bắt đầu bằng AppSec/ASPM, vì đây là phần dễ triển khai nhất và mang lại giá trị tức thì.
Bước 2: Mở rộng sang CSPM và CWPP để quan sát posture và runtime.
Bước 3: Kết hợp Cloud Network Firewall để bảo đảm phân vùng mạng và phòng thủ tầng network.
Bước 4: Hợp nhất tất cả vào SIEM/SOAR, từ đó cho phép tự động hóa khắc phục theo mô hình end-to-end.
Điều quan trọng là cách tiếp cận phù hợp, FPT Cloud Defense không phải là một “siêu sản phẩm" hay cố thay đổi toàn bộ hệ thống ngay lập tức, FPT Cloud Defense giúp doanh nghiệp từng bước, giúp nhìn rõ bề mặt tấn công, giảm thiểu lỗ hổng ngay từ code, xây dựng khả năng tự động xử lý sự cố theo playbook và giảm áp lực đáng kể cho đội SOC và DevSecOps.
7. Doanh nghiệp nên bắt đầu từ đâu?
Từ góc nhìn và kinh nghiệm triển khai thực tiễn, đây là thứ tự mà nhiều tổ chức chọn khi triển khai bảo mật cloud-native:
Bước 1: Triển khai AppSec/ASPM vào pipeline CI/CD.
Bắt đầu bằng secret scan và IaC scan - hai nguồn rủi ro phổ biến nhất.
Bước 2: Kích hoạt CSPM cơ bản để sửa lỗi cấu hình sớm.
Bước 3: Thiết lập bảo vệ runtime (CWPP) cho workload quan trọng.
Bước 4: Tối ưu firewall & network segmentation, nhất là nếu có multi-cloud.
Bước 5: Kết nối vào SIEM, xây playbook SOAR, ưu tiên 2-3 playbook quan trọng trước (ví dụ: khóa tài khoản bị xâm nhập, chặn IP, rollback cấu hình).
Bước 6: Tối ưu liên tục bằng cách đưa dữ liệu từ sự cố thực tế quay về quy trình phát triển.
Đây là cách hầu hết doanh nghiệp trưởng thành về bảo mật cloud-native thực hiện trong 3-6 tháng đầu để tăng cường khả năng phòng thủ trước những cuộc tấn công mạng tinh vi.
8. Doanh nghiệp chuyển từ “chống đỡ” sang “chủ động”
Câu chuyện bảo mật không còn là “đặt thêm tường lửa” hay “mua thêm công cụ”. Điều quan trọng doanh nghiệp cần là khả năng nhìn thấy rủi ro xuyên suốt - từ code tới production - và xử lý nó trước khi gây thiệt hại.
Triết lý CNAPP, cùng sự kết hợp giữa AppSec, CSPM, CWPP, Network Firewall và SIEM/SOAR chính là cách tiếp cận giúp doanh nghiệp chủ động, thống nhất hơn trong bảo vệ toàn bộ hệ thống.
Với FPT Cloud Defense, chúng tôi không đặt mục tiêu tạo ra “một công cụ thần kỳ”, mà hướng tới tạo ra một phương pháp phòng thủ hiện đại, giúp doanh nghiệp Việt Nam nâng cao năng lực bảo mật theo đúng cách mà thế giới đang chuyển dịch.
Lắng nghe chia sẻ đầy đủ về cách tiếp cận phòng thủ chủ động dựa trên CNAPP và ASPM từ anh Lê Ngọc Linh, Chuyên gia bảo mật, FPT Smart Cloud, Tập đoàn FPT tại đây.
Tác giả: Lê Ngọc Linh
Chuyên gia bảo mật, FPT Smart Cloud, Tập đoàn FPT
Liên hệ với chúng tôi để được tư vấn chi tiết về các giải pháp, dịch vụ của FPT Cloud
Hotline: 1900 638 399
Email: support@fptcloud.com
Support: m.me/fptsmartcloud

AI cho An ninh mạng – An ninh mạng cho AI: Hai chiều của một bức tranh đang định hình tương lai số
09:40 08/12/2025
Trong vài năm trở lại đây, trí tuệ nhân tạo (AI) phát triển với tốc độ chưa từng có, mở ra vô số cơ hội đổi mới cho doanh nghiệp và xã hội, đồng thời đẩy bối cảnh an ninh mạng trở nên phức tạp, tinh vi và khó lường hơn. Những cuộc tấn công mạng sử dụng AI, các chiến dịch tấn công được cá nhân hóa, mô hình bị đánh lừa bởi dữ liệu giả đang tạo ra sức ép chưa từng thấy lên đội ngũ lãnh đạo công nghệ. Giữa những biến động ấy, câu chuyện về AI và an ninh mạng không còn là hai chủ đề tách rời mà trở thành hai mặt của cùng một bức tranh lớn - nơi cả cơ hội lẫn rủi ro đều song hành.
Tại buổi chia sẻ trong khuôn khổ sự kiện về An toàn dữ liệu doanh nghiệp trong kỷ nguyên AI bùng nổ dành cho các lãnh đạo, startup công nghệ, anh Đặng Hải Sơn - Offensive Security Manager, FPT Smart Cloud, Tập đoàn FPT, khẳng định:“Mối quan hệ giữa AI và An ninh mạng đã chuyển từ trạng thái tuyến tính sang trạng thái tương hỗ phức tạp: AI giúp tăng cường năng lực phòng thủ, nhưng đồng thời việc ứng dụng AI lại tạo ra những lỗ hổng và bề mặt tấn công mới. Hai chiều này không thể tách rời - tổ chức muốn tận dụng AI thì phải hiểu đầy đủ cách AI can thiệp vào an ninh mạng và ngược lại, muốn vận hành AI một cách an toàn thì phải có nền tảng an ninh mạng đủ mạnh để kiểm soát.”
AI cho an ninh mạng: Cơ hội hình thành lớp phòng thủ chủ động thế hệ mới
Từ góc nhìn phòng thủ, AI đang mở ra một kỷ nguyên mới cho lĩnh vực an ninh mạng. Trước đây, các hệ thống bảo mật phần lớn dựa vào quy tắc cố định và khả năng phân tích thủ công của con người. Điều này dẫn đến tình trạng quá tải: đội ngũ SOC phải xử lý hàng nghìn cảnh báo mỗi ngày, rất nhiều trong số đó là cảnh báo giả, khiến phản ứng chậm trễ và tạo khoảng trống cho kẻ tấn công.
Sự xuất hiện của AI đã thay đổi hoàn toàn cục diện này. AI có thể phân tích dữ liệu bảo mật theo thời gian thực và học từ các mẫu tấn công trong quá khứ để dự đoán rủi ro trước khi sự cố xảy ra. Những mô hình học sâu giúp hệ thống nhận diện nhanh các hành vi bất thường trong lưu lượng mạng, từ đó phát hiện những mối đe dọa mà con người khó nhận ra. Quan trọng hơn, AI còn cho phép tự động hóa phản ứng - một máy chủ bị nghi ngờ có hành vi bất thường có thể được cô lập ngay lập tức mà không phải chờ sự can thiệp của chuyên gia. Điều này rút ngắn thời gian phản ứng từ hàng giờ xuống còn vài phút, tạo nên một hệ thống phòng thủ chủ động thay vì chỉ theo kiểu “chữa cháy” như trước.
Nhưng AI không thay thế con người. Như anh Sơn nhấn mạnh:“Cần dùng trí tuệ của con người kết hợp với tốc độ của AI để đưa ra quyết định cuối cùng.” Sự kết hợp giữa AI và con người tạo nên một mô hình phòng thủ lai vừa linh hoạt, vừa có chiều sâu, vừa tận dụng được tốc độ xử lý của máy tính vừa giữ được khả năng phán đoán chiến lược của con người. Chính sự bổ sung cho nhau này đang định hình lại cách các doanh nghiệp tổ chức vận hành an ninh mạng trong thời đại số.
An ninh mạng cho AI: Khi chính hệ thống AI trở thành mục tiêu tấn công
Ở chiều ngược lại, AI không chỉ là công cụ hỗ trợ phòng thủ mà chính nó cũng trở thành một tài sản giá trị cao và vì vậy luôn nằm trong tầm ngắm của các hacker. Các mô hình AI có thể bị thao túng chỉ bằng những tín hiệu nhỏ đến mức con người khó nhận ra. Những cuộc tấn công đối kháng (adversarial attack) có thể khiến hệ thống nhận diện hình ảnh hiểu sai biển báo, làm lệch quyết định của mô hình hỗ trợ xe tự lái và trực tiếp đe dọa an toàn con người.
Nghiêm trọng hơn là các hình thức tấn công sâu vào quá trình phát triển mô hình như đầu độc dữ liệu (data poisoning), khi dữ liệu độc hại được đưa vào giai đoạn huấn luyện khiến mô hình hoạt động sai lệch một cách âm thầm. Cùng với đó là chèn lệnh/prompt độc hại (prompt injection) - một kỹ thuật ngày càng phổ biến trong thời đại GenAI - khi các chỉ thị độc hại được giấu trong email, tệp tài liệu hoặc đường link, buộc mô hình phải thực thi những hành động vượt ngoài phạm vi an toàn đã được thiết lập và có thể dẫn đến rò rỉ dữ liệu nhạy cảm.
Những nguy cơ này cho thấy một thực tế rõ ràng: AI không được bảo vệ đúng cách có thể trở thành điểm yếu chí mạng, gây ra rủi ro lớn hơn rất nhiều so với những sự cố mất dữ liệu truyền thống.
Chính vì vậy, doanh nghiệp cần xây dựng một kiến trúc an ninh dành cho AI theo nhiều lớp, bao gồm bảo vệ dữ liệu, bảo vệ mô hình, bảo vệ hạ tầng triển khai và kiểm soát toàn bộ quá trình vận hành. Điều này đòi hỏi mã hóa dữ liệu và mô hình, tách biệt môi trường xử lý, giám sát hành vi mô hình theo thời gian thực, thực hiện red-teaming chuyên biệt cho AI và tuân thủ các tiêu chuẩn quốc tế như ISO, NIST AI RMF hay EU AI Act để bảo đảm hệ thống AI hoạt động an toàn, bền vững và đáng tin cậy.
Hai chiều - Một bức tranh thống nhất
Khi nhìn vào cả hai hướng - AI hỗ trợ an ninh mạng và an ninh mạng bảo vệ AI - có thể thấy rõ đây không còn là hai chiều hướng phát triển tách biệt với nhau. AI càng phát triển mạnh thì an ninh mạng càng cần đầu tư sâu để bảo vệ AI. Và chỉ khi nền tảng an ninh mạng đủ vững chắc, doanh nghiệp mới có khả năng để triển khai AI một cách an toàn, tận dụng trọn vẹn giá trị mà công nghệ này mang lại.
Trong phần kết của bài chia sẻ, anh Sơn nhấn mạnh thông điệp dành cho các nhà lãnh đạo: “AI không chờ đợi ai - Lãnh đạo cũng phải hành động ngay.” Doanh nghiệp không thể đợi đến khi sự cố xảy ra mới nghĩ đến việc bảo vệ AI. Thay vào đó, cần nhìn nhận đúng cả cơ hội và rủi ro, đưa an toàn vào ngay từ giai đoạn thiết kế, xem bảo mật AI như một phần của quản trị rủi ro tổng thể và đầu tư đúng mức cho những năng lực an ninh trọng yếu.
AI đang thay đổi mọi thứ với tốc độ nhanh hơn khả năng thích ứng của nhiều tổ chức. Những doanh nghiệp hành động sớm - xây dựng nền tảng an ninh vững chắc, chủ động trong chiến lược AI – sẽ là những doanh nghiệp dẫn đầu trong quá trình chuyển đổi số. Trong hành trình đó, FPT tiếp tục đóng vai trò đồng hành, mang đến các nền tảng Cloud và giải pháp AI được thiết kế theo tiêu chuẩn an toàn quốc tế, vận hành an ninh mạng toàn diện với mục tiêu không chỉ là hỗ trợ doanh nghiệp ứng dụng AI, mà là giúp ứng dụng AI một cách an toàn, bền vững để tiến xa hơn trong kỷ nguyên số.
Lắng nghe chia sẻ đầy đủ của anh Đặng Hải Sơn về bức tranh hai chiều của AI và An ninh mạng tại đây.
Liên hệ với chúng tôi để được tư vấn chi tiết về các giải pháp, dịch vụ của FPT Cloud
Hotline: 1900 638 399
Email: support@fptcloud.com
Support: m.me/fptsmartcloud