- Giới thiệu
-
 Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục
Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML
Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác. Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu
Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA! Giải pháp làm việc từ xa hiệu quả và an toàn cho doanh nghiệp
Giải pháp làm việc từ xa hiệu quả và an toàn cho doanh nghiệp
 Dịch vụ máy chủ ảo tiên tiến với khả năng mở rộng nhanh chóng
Dịch vụ máy chủ ảo tiên tiến với khả năng mở rộng nhanh chóng Hiệu năng mạnh mẽ với hạ tầng riêng biệt
Hiệu năng mạnh mẽ với hạ tầng riêng biệt
Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML
Dịch vụ máy chủ ảo tiết kiệm đến 90% chi phí cho doanh nghiệp
Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu
Dịch vụ dự phòng & khôi phục hệ thống nhanh chóng
Lưu trữ khối đa dạng thông lượng và dung lượng cho mọi nhu cầu
Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục Nâng cao năng lực, tính sẵn sàng của ứng dụng
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Dịch vụ tường lửa thông minh cho các ứng dụng web - Giải pháp bảo mật đột phá với sự hợp tác giữa FPT Cloud và Penta Security.
Dịch vụ bảo mật tường lửa thế hệ mới
Lưu trữ, quản lý, và bảo mật các Docker Images
Nền tảng Kubernetes an toàn, bảo mật, ổn định, hiệu năng cao
Nâng cao năng lực, tính sẵn sàng của ứng dụng
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Dịch vụ tường lửa thông minh cho các ứng dụng web - Giải pháp bảo mật đột phá với sự hợp tác giữa FPT Cloud và Penta Security.
Dịch vụ bảo mật tường lửa thế hệ mới
Lưu trữ, quản lý, và bảo mật các Docker Images
Nền tảng Kubernetes an toàn, bảo mật, ổn định, hiệu năng cao Tăng tốc phát triển ứng dụng yêu cầu hiệu năng cao bằng dịch vụ Kubernetes tích hợp với vi xử lý cao cấp GPU
Giám sát và triển khai cơ sở dữ liệu như Kafka,..
Tăng tốc phát triển ứng dụng yêu cầu hiệu năng cao bằng dịch vụ Kubernetes tích hợp với vi xử lý cao cấp GPU
Giám sát và triển khai cơ sở dữ liệu như Kafka,..
Giám sát và triển khai cơ sở dữ liệu Redis, Cassandra, ...
Giám sát và triển khai cơ sở dữ liệu xử lý phân tích trực tuyến
Giám sát và triển khai cơ sở dữ liệu MySQL, Postgres, SQLserver, MariaDB,...
Giám sát và triển khai cơ sở dữ liệu truy vấn thông tin
Giám sát và triển khai cơ sở dữ liệu chuỗi thời gian
Giám sát hệ thống và tài nguyên toàn diện trên mọi nền tảng Giải pháp quản lý sự cố thông minh
Giải pháp quản lý sự cố thông minh Dịch vụ cung cấp giải pháp khởi tạo và quản lý FPT ArgoCD được tạo ra từ dự án mã nguồn mở Argo
Nền tảng tự động hoá bảo mật trong quy trình phát triển phần mềm
Dịch vụ cung cấp giải pháp khởi tạo và quản lý FPT ArgoCD được tạo ra từ dự án mã nguồn mở Argo
Nền tảng tự động hoá bảo mật trong quy trình phát triển phần mềm Tăng cường khả năng quản lý tài sản dữ liệu doanh nghiệp
Tăng cường khả năng quản lý tài sản dữ liệu doanh nghiệp Quản lý dữ liệu liền mạch & toàn diện
Truy vấn, quản lý, trực quan hóa dữ liệu hiệu quả
Tăng tốc độ xử lý, đảm bảo tính nhất quán cho ứng dụng
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Nền tảng hội thoại thông minh gắn kết khách hàng trên mọi nền tảng
Xác thực nhanh chóng, dễ dàng, tối ưu chi phí
Nâng tầm trải nghiệm khách hàng
Quản lý dữ liệu liền mạch & toàn diện
Truy vấn, quản lý, trực quan hóa dữ liệu hiệu quả
Tăng tốc độ xử lý, đảm bảo tính nhất quán cho ứng dụng
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Nền tảng hội thoại thông minh gắn kết khách hàng trên mọi nền tảng
Xác thực nhanh chóng, dễ dàng, tối ưu chi phí
Nâng tầm trải nghiệm khách hàng
Trích xuất dữ liệu vượt mọi giới hạn
Chuyển văn bản thành giọng nói tiếng Việt với ngữ điệu tự nhiên.
- Bảng giá
- Sự kiện
FPT Kubernetes Engine with GPU
-
 Hướng dẫn sử dụng
Hướng dẫn sử dụng
- Tổng quan dịch vụ GPU trên Kubernetes FPT Cloud
- Cài đặt và khởi tạo Cluster Kubernetes sử dụng GPU
- Thay đổi Worker Group sử dụng GPU
- Triển khai ứng dụng sử dụng GPU trên Kubernetes
- Hướng dẫn sử dụng GPU Telemetry
- Hướng dẫn sử dụng Autoscaler với GPU
- Hướng dẫn sử dụng các chế độ GPU sharing
- Tăng thêm Worker Group sử dụng GPU
- Hướng dẫn cài đặt GPU Driver trên Kubernetes
- Hướng dẫn cấu hình Auto Scale sử dụng GPU Custom Metric
- Hướng dẫn cấu hình Auto Scale sử dụng KEDA và Prometheus
Hướng dẫn cấu hình Auto Scale sử dụng KEDA và Prometheus
Hướng dẫn cấu hình Auto Scale sử dụng KEDA và Prometheus
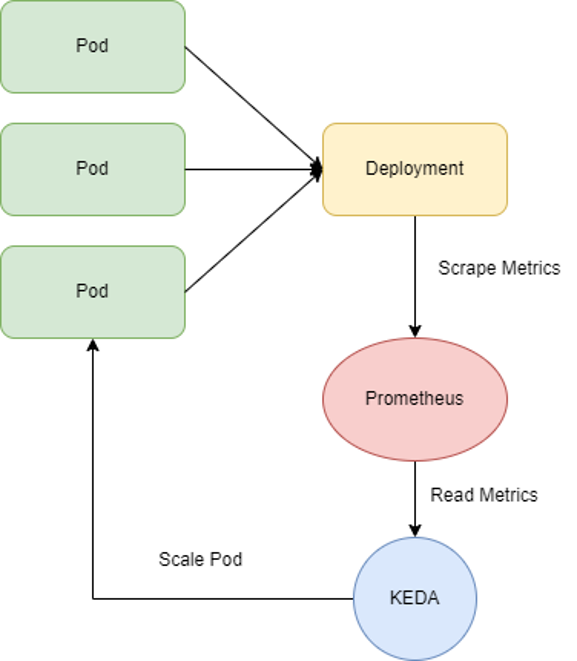
Yêu cầu
- Cụm kubernetes có gắn GPU
- Ứng dụng GPU đang ở trạng thái running
-
Đã cài đặt gói kube-prometheus-stack và prometheus-adapter ở dịch vụ FPT App Catalog như docs
Hướng dẫn cấu hình Auto Scale cho FPT Kubernetes Engine GPU sử dụng GPU Custom Metric
Các bước cấu hình:
Bước 1: Cài đặt KEDA
-
Cách 1: Sử dụng FPT App Catalog
Chọn dịch vụ FPT Cloud App Catalog sau đó tìm kiếm KEDA trong Repository fptcloud-catalogs
-
Cách 2: Sử dụng helm chart
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace- Kiểm tra xem các pod của KEDA đã hoạt động bình thường hay chưa
kubectl -n keda get podNAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-54764ff7d5-l4tks 1/1 Running 0 3d
pod/keda-operator-567cb596fd-wx4t8 1/1 Running 0 2d23h
pod/keda-operator-metrics-apiserver-6475bf5fff-8x8bw 1/1 Running 0 2d14h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/keda-admission-webhooks ClusterIP 100.71.2.54 443/TCP 3d2h
service/keda-operator ClusterIP 100.66.228.223 9666/TCP 3d2h
service/keda-operator-metrics-apiserver ClusterIP 100.71.162.181 443/TCP,8080/TCP 3d2h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/keda-admission-webhooks 1/1 1 1 3d2h
deployment.apps/keda-operator 1/1 1 1 3d2h
deployment.apps/keda-operator-metrics-apiserver 1/1 1 1 3d2h
NAME DESIRED CURRENT READY AGE
replicaset.apps/keda-admission-webhooks-54764ff7d5 1 1 1 3d2h
replicaset.apps/keda-operator-567cb596fd 1 1 1 3d2h
replicaset.apps/keda-operator-metrics-apiserver-6475bf5fff 1 1 1 3d2h Bước 2: Kiểm tra prometheus đã có các metric GPU hay chưa
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq -r . | grep DCGM"name": "namespaces/DCGM_FI_DEV_POWER_USAGE",
"name": "namespaces/DCGM_FI_DEV_FB_USED",
"name": "namespaces/DCGM_FI_DEV_PCIE_REPLAY_COUNTER",
"name": "pods/DCGM_FI_DEV_XID_ERRORS",
"name": "namespaces/DCGM_FI_PROF_GR_ENGINE_ACTIVE",
"name": "namespaces/DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION",
"name": "pods/DCGM_FI_PROF_DRAM_ACTIVE",
"name": "jobs.batch/DCGM_FI_DEV_POWER_USAGE",
"name": "jobs.batch/DCGM_FI_DEV_SM_CLOCK",
"name": "namespaces/DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL",
"name": "pods/DCGM_FI_DEV_POWER_USAGE",
"name": "jobs.batch/DCGM_FI_DEV_MEM_CLOCK",
"name": "jobs.batch/DCGM_FI_DEV_FB_USED",
"name": "namespaces/DCGM_FI_DEV_FB_FREE",
"name": "jobs.batch/DCGM_FI_PROF_GR_ENGINE_ACTIVE",
"name": "pods/DCGM_FI_DEV_MEMORY_TEMP",
"name": "pods/DCGM_FI_DEV_FB_FREE",
"name": "pods/DCGM_FI_DEV_MEM_CLOCK",
"name": "pods/DCGM_FI_PROF_GR_ENGINE_ACTIVE",
"name": "pods/DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL",
"name": "pods/DCGM_FI_PROF_PIPE_TENSOR_ACTIVE",
"name": "jobs.batch/DCGM_FI_DEV_MEMORY_TEMP",
"name": "namespaces/DCGM_FI_DEV_MEM_CLOCK",
"name": "jobs.batch/DCGM_FI_DEV_XID_ERRORS",
"name": "namespaces/DCGM_FI_DEV_VGPU_LICENSE_STATUS",
"name": "jobs.batch/DCGM_FI_DEV_VGPU_LICENSE_STATUS",
"name": "pods/DCGM_FI_DEV_GPU_TEMP",
"name": "jobs.batch/DCGM_FI_PROF_PIPE_TENSOR_ACTIVE",
"name": "pods/DCGM_FI_DEV_PCIE_REPLAY_COUNTER",
"name": "pods/DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION",
"name": "jobs.batch/DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION",
"name": "pods/DCGM_FI_DEV_FB_USED",
"name": "pods/DCGM_FI_DEV_VGPU_LICENSE_STATUS",
"name": "namespaces/DCGM_FI_DEV_MEMORY_TEMP",
"name": "jobs.batch/DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL",
"name": "namespaces/DCGM_FI_DEV_SM_CLOCK",
"name": "namespaces/DCGM_FI_PROF_PIPE_TENSOR_ACTIVE",
"name": "namespaces/DCGM_FI_DEV_GPU_TEMP",
"name": "jobs.batch/DCGM_FI_DEV_GPU_TEMP",
"name": "namespaces/DCGM_FI_PROF_DRAM_ACTIVE",
"name": "namespaces/DCGM_FI_DEV_XID_ERRORS",
"name": "jobs.batch/DCGM_FI_DEV_FB_FREE",
"name": "pods/DCGM_FI_DEV_SM_CLOCK",
"name": "jobs.batch/DCGM_FI_DEV_PCIE_REPLAY_COUNTER",
"name": "jobs.batch/DCGM_FI_PROF_DRAM_ACTIVE",Bước 3: Tạo ScaledObject để chỉ định autoscale cho Ứng dụng
- Manifest
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: scaled-object
spec:
scaleTargetRef:
name: gpu-test
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-kube-prometheus-prometheus.prometheus.svc.cluster.local:9090
metricName: engine_active
query: sum(DCGM_FI_PROF_GR_ENGINE_ACTIVE{modelName="NVIDIA A30", container="gpu-test"}) / count(DCGM_FI_PROF_GR_ENGINE_ACTIVE{modelName="NVIDIA A30", container="gpu-test"})
threshold: '0.8'- name: Tên Deployment GPU ở ví dụ là
gpu-test - serverAddress: Endpoint của Prometheus server ở ví dụ là
http://prometheus-kube-prometheus-prometheus.prometheus.svc.cluster.local:9090 - query: Câu lệnh PromQL để tìm ra giá trị dựa vào đó tiến hành autoscale, ở trên ví dụ là tìm các giá trị trung bình của biến
DCGM_FI_PROF_GR_ENGINE_ACTIVE - threshold: giá trị đạt ngưỡng để bắt đầu active autoscale, ở ví dụ là
0.8
Như vậy như ví dụ trên, mỗi khi có giá trị trung bình củaDCGM_FI_PROF_GR_ENGINE_ACTIVE lớn hơn 0.8 thì ScaledObject sẽ thực hiện scale các pod của Deployment name gpu-test.
Sau khi tạo ScaledObject, deployment sẽ tự động scale về 0, như vậy là đã cấu hình thành công.
© 2025 FPT Cloud. Đã đăng ký Bản quyền.