- Giới thiệu
-
 Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục
Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục Certified DBaaS (cơ sở dữ liệu theo dạng dịch vụ) đầu tiên của MongoDB tại Việt Nam
Certified DBaaS (cơ sở dữ liệu theo dạng dịch vụ) đầu tiên của MongoDB tại Việt Nam Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML
Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác. Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu
Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA! Giải pháp làm việc từ xa hiệu quả và an toàn cho doanh nghiệp
Giải pháp làm việc từ xa hiệu quả và an toàn cho doanh nghiệp
 Dịch vụ máy chủ ảo tiên tiến với khả năng mở rộng nhanh chóng
Dịch vụ máy chủ ảo tiên tiến với khả năng mở rộng nhanh chóng Hiệu năng mạnh mẽ với hạ tầng riêng biệt
Hiệu năng mạnh mẽ với hạ tầng riêng biệt
Tích hợp với máy chủ ảo dành cho 3D Rendering, AI hay ML
Dịch vụ máy chủ ảo tiết kiệm đến 90% chi phí cho doanh nghiệp
Sao lưu và khôi phục dữ liệu tức thời, an toàn và toàn vẹn dữ liệu
Dịch vụ dự phòng & khôi phục hệ thống nhanh chóng
Lưu trữ khối đa dạng thông lượng và dung lượng cho mọi nhu cầu
Lưu trữ dữ liệu đối tượng không giới hạn và truy xuất dữ liệu liên tục Nâng cao năng lực, tính sẵn sàng của ứng dụng
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Dịch vụ tường lửa thông minh cho các ứng dụng web - Giải pháp bảo mật đột phá với sự hợp tác giữa FPT Cloud và Penta Security.
Dịch vụ bảo mật tường lửa thế hệ mới
Lưu trữ, quản lý, và bảo mật các Docker Images
Nền tảng Kubernetes an toàn, bảo mật, ổn định, hiệu năng cao
Nâng cao năng lực, tính sẵn sàng của ứng dụng
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, dịch vụ cung cấp khả năng rà quét toàn diện, phân tích chi tiết và đánh giá lỗ hổng bảo mật để tăng cường an ninh thông tin cho hệ thống ứng dụng doanh nghiệp
Sản phẩm hợp tác giữa FPT Cloud và CyRadar, cung cấp dịch vụ tường lửa với khả năng bảo vệ mạnh mẽ cho các ứng dụng web
Dịch vụ tường lửa thông minh cho các ứng dụng web - Giải pháp bảo mật đột phá với sự hợp tác giữa FPT Cloud và Penta Security.
Dịch vụ bảo mật tường lửa thế hệ mới
Lưu trữ, quản lý, và bảo mật các Docker Images
Nền tảng Kubernetes an toàn, bảo mật, ổn định, hiệu năng cao Tăng tốc phát triển ứng dụng yêu cầu hiệu năng cao bằng dịch vụ Kubernetes tích hợp với vi xử lý cao cấp GPU
Giám sát và triển khai cơ sở dữ liệu như Kafka,..
Tăng tốc phát triển ứng dụng yêu cầu hiệu năng cao bằng dịch vụ Kubernetes tích hợp với vi xử lý cao cấp GPU
Giám sát và triển khai cơ sở dữ liệu như Kafka,..
Certified DBaaS (cơ sở dữ liệu theo dạng dịch vụ) đầu tiên của MongoDB tại Việt Nam
Giám sát và triển khai cơ sở dữ liệu Redis, Cassandra, ...
Giám sát và triển khai cơ sở dữ liệu xử lý phân tích trực tuyến
Giám sát và triển khai cơ sở dữ liệu MySQL, Postgres, SQLserver, MariaDB,...
Giám sát và triển khai cơ sở dữ liệu truy vấn thông tin
Giám sát và triển khai cơ sở dữ liệu chuỗi thời gian
Giám sát hệ thống và tài nguyên toàn diện trên mọi nền tảng Giải pháp quản lý sự cố thông minh
Giải pháp quản lý sự cố thông minh Dịch vụ cung cấp giải pháp khởi tạo và quản lý FPT ArgoCD được tạo ra từ dự án mã nguồn mở Argo
Nền tảng tự động hoá bảo mật trong quy trình phát triển phần mềm
Dịch vụ cung cấp giải pháp khởi tạo và quản lý FPT ArgoCD được tạo ra từ dự án mã nguồn mở Argo
Nền tảng tự động hoá bảo mật trong quy trình phát triển phần mềm Tăng cường khả năng quản lý tài sản dữ liệu doanh nghiệp
Tăng cường khả năng quản lý tài sản dữ liệu doanh nghiệp Quản lý dữ liệu liền mạch & toàn diện
Truy vấn, quản lý, trực quan hóa dữ liệu hiệu quả
Tăng tốc độ xử lý, đảm bảo tính nhất quán cho ứng dụng
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Nền tảng hội thoại thông minh gắn kết khách hàng trên mọi nền tảng
Xác thực nhanh chóng, dễ dàng, tối ưu chi phí
Nâng tầm trải nghiệm khách hàng
Quản lý dữ liệu liền mạch & toàn diện
Truy vấn, quản lý, trực quan hóa dữ liệu hiệu quả
Tăng tốc độ xử lý, đảm bảo tính nhất quán cho ứng dụng
Nền tảng phân tích dữ liệu đáng tin cậy cho doanh nghiệp và chuyên gia, giúp tối ưu chi phí vận hành lên đến 40% so với giải pháp BI khác.
Trở thành doanh nghiệp đầu tiên trải nghiệm bộ giải pháp phát triển AI toàn diện, được phát triển trên công nghệ mạnh mẽ bậc nhất từ NVIDIA!
Nền tảng hội thoại thông minh gắn kết khách hàng trên mọi nền tảng
Xác thực nhanh chóng, dễ dàng, tối ưu chi phí
Nâng tầm trải nghiệm khách hàng
Trích xuất dữ liệu vượt mọi giới hạn
Chuyển văn bản thành giọng nói tiếng Việt với ngữ điệu tự nhiên.
- Bảng giá
- Sự kiện
Managed – FPT Database Engines
-
 Concepts
Concepts
-
 Thiết lập ban đầu (Initial Setup)
Thiết lập ban đầu (Initial Setup)
-
 Hướng dẫn chi tiết
Hướng dẫn chi tiết
-
 Peformance & Benchmark
Peformance & Benchmark
-
 Troubleshooting
Troubleshooting
-
 Các câu hỏi thường gặp (FAQs)
Các câu hỏi thường gặp (FAQs)
-
 Glossary
Glossary
-
Chức năng Khởi tạo cụm cơ sở dữ liệu cho phép triển khai nhanh các cụm cơ sở dữ liệu khác nhau trên nền tảng FPT Database Engine mà không cần cấu hình chi tiết hạ tầng vật lý. Việc khởi tạo một cụm cơ sở dữ liệu mới yêu cầu bạn nhập các cấu hình liên quan đến loại engine, network, định danh cluster và các dịch vụ bổ sung như backup và auto-scaling. Hướng dẫn chi tiết mô tả ngay dưới đây.
Bước 1: Mở màn hình tạo cụm cơ sở dữ liệu
Truy cập trang danh sách cụm cơ sở dữ liệu tương ứng với loại cơ sở dữ liệu cần tạo (chi tiết xem mục Xem danh sách cụm cơ sở dữ liệu, chọn Create a Database Engine hoặc Create để bắt đầu quá trình khởi tạo một cụm cơ sở dữ liệu mới. Màn hình Create New Database sẽ được mở, cho phép bạn cấu hình các thông số cần thiết để định nghĩa và triển khai cụm cơ sở dữ liệu trong môi trường FPT Database Engine. Tiến trình triển khai gồm 3 bước:
- Step 1 – Database Configuration
- Step 2 – Additional Service Configuration
- Step 3 – Review & Create
Bước 2: Định nghĩa cấu hình cụm cơ sở dữ liệu
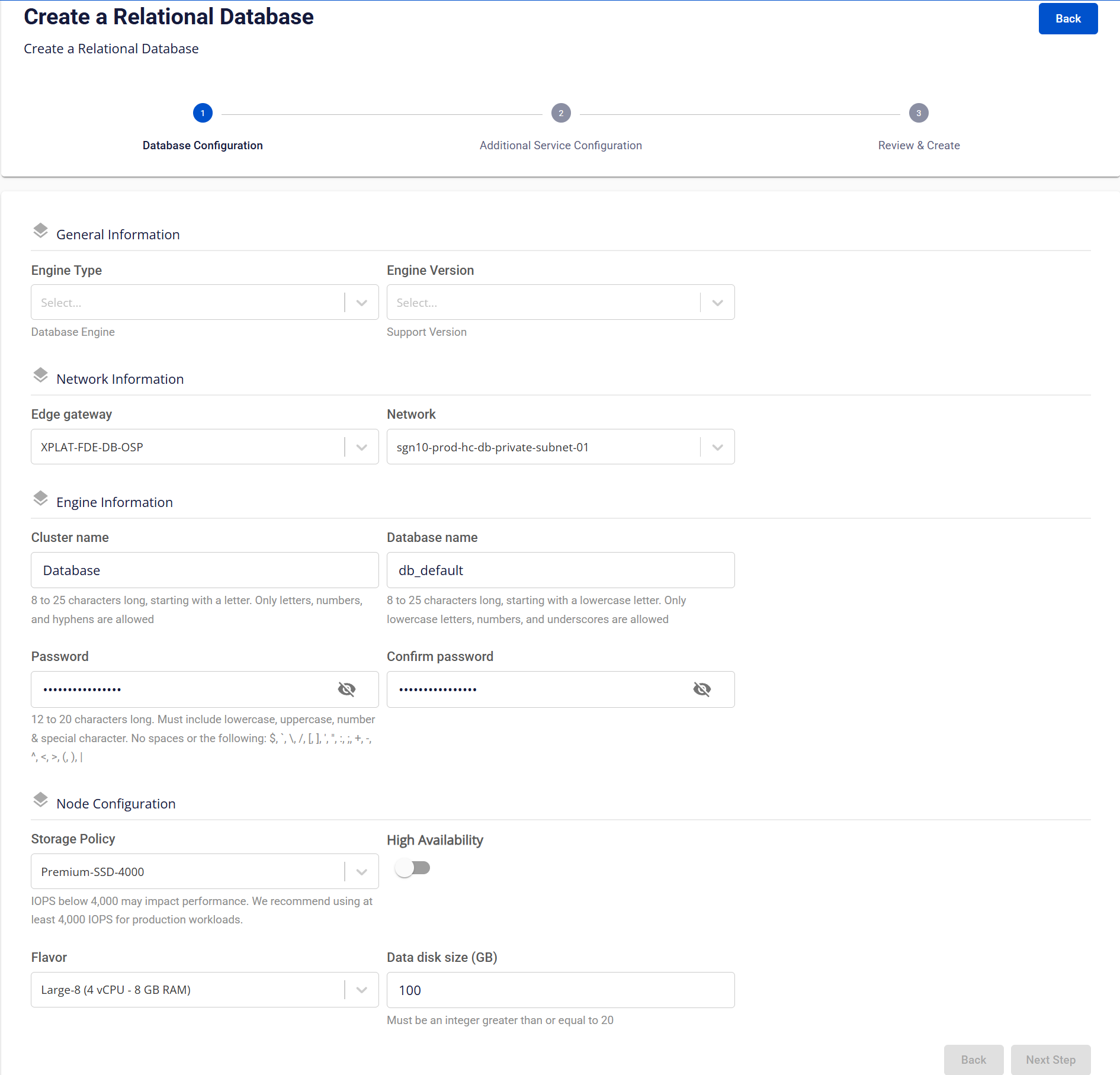
Màn hình này là bước đầu tiên trong quy trình khởi tạo cụm cơ sở dữ liệu, dùng để cấu hình các tham số nền tảng như engine, mạng, thông tin xác thực và tài nguyên. Tùy theo loại engine được chọn, một số trường thông tin có thể khác nhau.
Mô tả các trường trên màn hình:
| 1. Section General Information (Thông tin chung) | ||
|---|---|---|
| Trường | Mô tả | |
| Engine Type | Chọn loại cơ sở dữ liệu. Tùy thuộc vào menu đã chọn, hệ thống sẽ hiển thị các tùy chọn tương ứng:
|
|
| Edition | Chọn loại edition, bao gồm các giá trị: “Enterprise”, “Standard”, “Web”. Trường này chỉ hiển thị đối với Engine Type là "SQL Server". |
|
| Engine Version | Chọn phiên bản engine được hệ thống hỗ trợ theo Chính sách phiên bản Database Engine. | |
| 2. Section Network Information (Thông tin mạng) | ||
| Trường | Mô tả | |
| Edge Gateway | Chọn Edge Gateway để định tuyến lưu lượng mạng giữa cụm cơ sửo dữ liệu và các hệ thống khác. | |
| Network | Chọn Network/Subnet nơi cụm cơ sở dữ liệu sẽ được triển khai. Network này quyết định phạm vi truy cập và mức độ cô lập. | |
| 3. Section Engine Information (Thông tin cơ sở dữ liệu) | ||
| Trường | Mô tả | |
| Cluster Name | Tên định danh cho cụm cơ sở dữ liệu, độ dài từ 8–25 ký tự, chỉ bao gồm chữ cái, số và dấu gạch ngang (-). Bắt đầu bằng chữ cái. | |
| Database Name | Tên database mặc định được tạo trong cụm, độ dài từ 8–25 ký tự, chỉ bao gồm chữ cái in thường, chữ số và dấu gạch dưới (_). Bắt đầu bằng chữ thường. Trường này không được hiển thị đối với Engine Type là Redis hoặc Kafka. |
|
| VHost Name | Tên VHost mặc định được tạo trong cụm, độ dài từ 8–25 ký tự, chỉ bao gồm chữ cái in thường, chữ số và dấu gạch dưới (_). Bắt đầu bằng chữ thường. Chỉ hiển thị đối với Engine Type là RabbitMQ. |
|
| Password/ Confirm Password | Mật khẩu cho tài khoản quản trị database mặc định, độ dài từ 12–20 ký tự, bao gồm chữ hoa, chữ thường, số và ký tự đặc biệt, đồng thời không được chứa khoảng trắng hoặc các ký tự đặc biệt sau: / \ " ' < > ? % ; : $ ! [ ] { } ( ) , & + | |
| 4. Section Node Configuration (Cấu hình node) | ||
| Trường | Mô tả | |
| Storage Policy | Chọn Storage Policy xác định hiệu năng lưu trữ (IOPS). Khuyến nghị chọn IOPS ≥ 4,000 cho môi trường production để đảm bảo hiệu suất và ổn định. | |
| High Availability | Bật High Availability (HA) để triển khai cụm cơ sở dữ liệu nhiều node với khả năng automatic failover. Với Engine Type là Cassandra thì không hiển thị trường này. ⚠️
Lưu ý quan trọng khi sử dụng HA cho engine ClickHouse:
|
|
| Number Of Nodes | Chọn số node cần tạo cho cụm cơ sở dữ liệu.
Chỉ hiển thị đối với Engine Type là Cassandra. |
|
| Flavor | Chọn Flavor để xác định tài nguyên compute cho mỗi node (vCPU, RAM). | |
| Data Disk Size (GB) | Dung lượng ổ đĩa dữ liệu cho cụm cơ sở dữ liệu, tính theo đơn vị GB với giá trị tối thiểu là 20 GB. |
Sau khi nhập đầy đủ thông tin, nhấn Next Step để chuyển sang cấu hình các dịch vụ đi kèm.
Bước 3: Cấu hình dịch vụ add-on
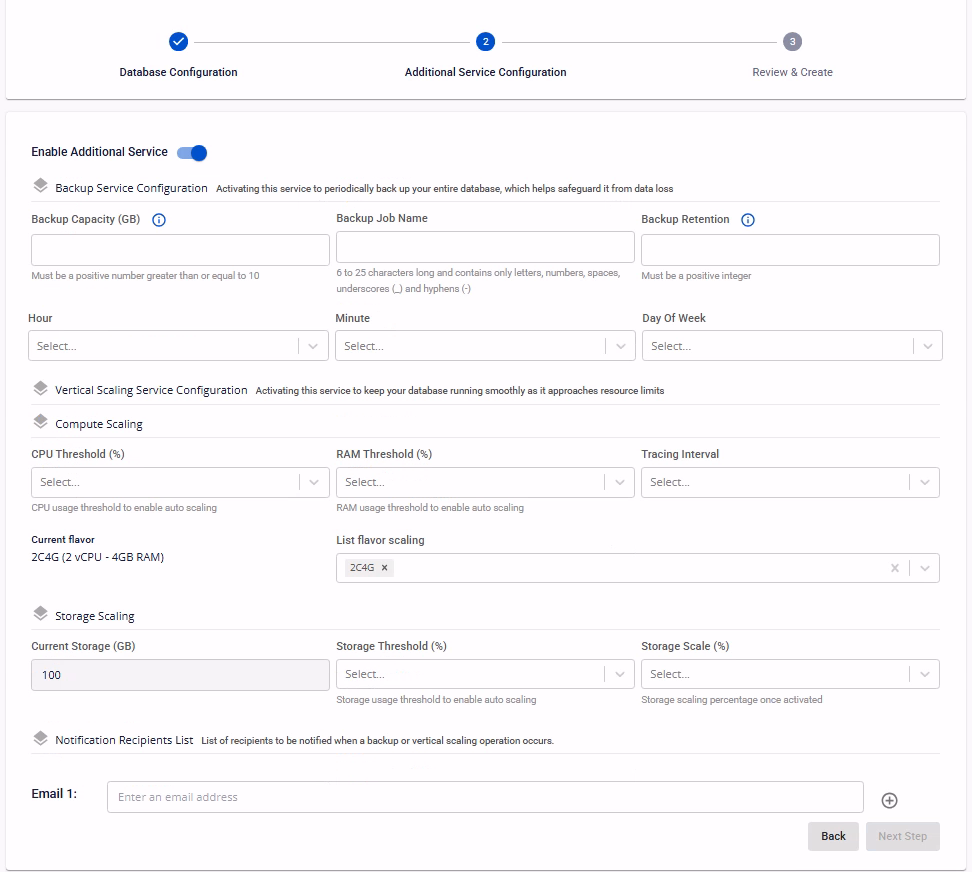
Màn hình này cho phép cấu hình các dịch vụ bổ sung (optional) cho cụm cơ sở dữ liệu như backup, tự động mở rộng tài nguyên, và thông báo, nhằm tăng độ sẵn sàng, khả năng mở rộng và khả năng vận hành.
Khuyến nghị bật dịch vụ Backup và Auto Scaling ngay khi khởi tạo để đảm bảo an toàn dữ liệu, ổn định và liên tục vận hành của hệ thống.
Mô tả các trường trên màn hình:
-
Enable Additional Service: Bật/tắt các dịch vụ add-on cho cụm cơ sở dữ liệu, gồm backup và auto scaling. Khi tắt, cụm cơ sở dữ liệu sẽ được tạo mà không được kích hoạt các dịch vụ này. Bạn có thể bật các dịch vụ add-on sau khi cụm được tạo thành công.
-
Backup Service Configuration: Kích hoạt dịch vụ này để hệ thống thực hiện backup toàn bộ cụm cơ sở dữ liệu hàng ngày, giúp bảo vệ dữ liệu trước các sự cố. Các trường thông tin cần nhập bao gồm:
| Trường | Mô tả |
|---|---|
| Backup Capacity (GB) | Dung lượng lưu trữ dành cho backup, tính theo đơn vị GB với giá trị tối thiểu là 10 GB. |
| Storage Policy | Chính sách lưu trữ backup, xác định hiệu năng và độ bền của storage. |
| Enable point-in-time recovery (PITR) | Bật tính năng PITR cho cụm cơ sở dữ liệu. Chỉ hiển thị nếu loại engine được chọn là PostgreSQL, MySQL hoặc MariaDB |
| Backup Job Name | Tên định danh cho backup job, độ dài từ 6–25 ký tự và chỉ được chứa chữ cái, chữ số, khoảng trắng, dấu gạch ngang (-) và dấu gạch dưới (_). |
| Backup Retention | Số lượng bản backup toàn bộ cụm cơ sở dữ liệu được giữ lại. Khi số lượng bản backup vượt quá giới hạn này, các bản backup cũ nhất sẽ được tự động xóa. |
| Hour / Minute / Day of Week | Cấu hình lịch chạy backup định kỳ:
|
- Vertical Scaling Service Configuration: Kích hoạt dịch vụ này cho phép hệ thống tự động mở rộng tài nguyên compute hoặc storage khi vượt ngưỡng sử dụng. Các trường thông tin cần nhập bao gồm:
| 1. Section Compute Scaling (Cấu hình tự động mở rộng compute) | ||
|---|---|---|
| Trường | Mô tả | |
| CPU Threshold (%) | Ngưỡng sử dụng CPU để kích hoạt auto scaling cho cụm cơ sở dữ liệu. | |
| RAM Threshold (%) | Ngưỡng sử dụng RAM để kích hoạt auto scaling cho cụm cơ sở dữ liệu. | |
| Tracing Interval | Chu kỳ giám sát mức sử dụng tài nguyên CPU và RAM để đưa ra quyết định scale. | |
| Current Flavor | Flavor hiện tại của database node (vCPU / RAM). | |
| List Flavor Scaling | Danh sách các flavor được phép scale lên khi auto scaling được kích hoạt. Danh sách sẽ được sắp xếp tăng dần và được scale theo đúng thứ tự từ bé đến lớn. | |
| 2. Section Storage Scaling (cấu hình tự động mở rộng storage) | ||
| Trường | Mô tả | |
| Current Storage (GB) | Dung lượng storage hiện tại của cụm cơ sở dữ liệu. | |
| Storage Threshold (%) | Ngưỡng sử dụng storage để kích hoạt auto scaling. | |
| Storage Scale (%) | Tỷ lệ mở rộng dung lượng storage mỗi lần scale. |
-
Maintenance Window: Khai báo khung thời gian mà hệ thống được phép thực hiện bảo trì:
- Day of Week: Ngày trong tuần thực hiện bảo trì, cho phép lựa chọn từ “Monday” đến “Sunday”.
- Start Time: Thời điểm bắt đầu được phép thực hiện bảo trì trong ngày đã chọn. Thời lượng bảo trì: 1 giờ, tính từ thời điểm Start Time đã cấu hình.
-
Notification Recipients List: Nhập danh sách email để nhận thông báo khi có sự kiện backup hoặc scaling được thực hiện. Bạn có thể thêm nhiều email bằng cách nhấn icon "+" để nhập email mới vào danh sách.
Sau khi nhập đầy đủ thông tin, nhấn Next Step để chuyển sang bước kiểm tra các thông tin đã nhập và xác nhận việc khởi tạo cụm cơ sở dữ liệu.
Bước 4: Kiểm tra thông tin & xác nhận khởi tạo
Người dùng cần kiểm tra toàn bộ thông tin đã cấu hình cho cụm cơ sở dữ liệu trước khi xác nhận khởi tạo:
- Nếu cần chỉnh sửa, nhấn “Back” để quay lại bước trước và cập nhật thông tin.
- Nếu thông tin đã chính xác, nhấn “Create” để xác nhận khởi tạo cụm cơ sở dữ liệu.
Sau khi xác nhận:
- Hệ thống sẽ kiểm tra tài nguyên, hiển thị thông báo khởi tạo và bắt đầu quá trình triển khai cụm cơ sở dữ liệu mới dựa trên cấu hình đã nhập.
- Người dùng sẽ được chuyển về màn hình danh sách, trong đó cụm cơ sở dữ liệu vừa tạo sẽ hiển thị ở trạng thái “Processing” ở đầu danh sách.
Quá trình khởi tạo thường kéo dài 5–7 phút. Khi hoàn tất, cụm cơ sở dữ liệu sẽ chuyển sang trạng thái “Running” và sẵn sàng để sử dụng. Lưu ý: Nếu quá trình khởi tạo thất bại, vui lòng xóa cụm bị lỗi và thực hiện khởi tạo lại.
Để kết nối tới cụm cơ sở dữ liệu vừa tạo, xem hướng dẫn tại mục Kết nối cụm cơ sở dữ liệu.
Để vận hành cụm cơ sở dữ liệu, xem hướng dẫn tại mục Vận hành cụm cơ sở dữ liệu.